start_urls内部原理
步骤
1 scrapy引擎来爬虫中取起始的url: 2 1.调用start_requests并获取返回值 3 2.v = iter(返回值) 4 3. 5 req1 = 执行v.__next__() 6 req2 = 执行v.__next__() 7 req3 = 执行v.__next__() 8 4.全部放到调度器中
编写
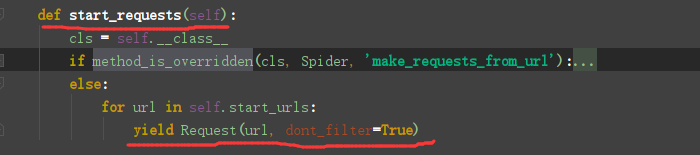
1 class ChoutiSpider(scrapy.Spider): 2 name = 'chouti' 3 # 爬取定向的网页 只允许这个域名的 4 allowed_domains = ['chouti.com'] 5 start_urls = ['https://dig.chouti.com/'] 6 cookie_dict = {} 7 8 def start_requests(self): 9 # 方式1 10 # for url in self.start_urls: 11 # yield Request(url=url) 12 # 方式2 13 # req_list = [] 14 # for url in self.start_urls: 15 # req_list.append(Request(url=url)) 16 # return req_list 17 pass
用到的知识
可迭代对象或者生成器直接iter方法变成迭代器,以后定制start_urls的时候可以自己直接发post请求,内置默认用的get方法,拿url也可以到缓存redis中拿。
源码部分:
深度、优先级
源码流程分析
结合我的这篇博文深度https://www.cnblogs.com/Alexephor/p/11437061.html
1 # -*- coding: utf-8 -*- 2 import scrapy 3 from wyb.items import WybItem 4 from scrapy.dupefilters import RFPDupeFilter 5 from scrapy.http.response.html import HtmlResponse 6 from scrapy.http.cookies import CookieJar 7 from urllib.parse import urlencode 8 from scrapy.http import Request 9 10 11 class ChoutiSpider(scrapy.Spider): 12 name = 'chouti' 13 # 爬取定向的网页 只允许这个域名的 14 allowed_domains = ['chouti.com'] 15 start_urls = ['https://dig.chouti.com/'] 16 17 def start_requests(self): 18 import os 19 # 代理设置 downloadmiddleware中httppxoxy 20 os.environ['HTTP_PROXY'] = '1.1.1.2' 21 os.environ['HTTPS_PROXY'] = 'http://root:woshinizuzong@192.168.10.10:8888/' 22 # 方式1 23 for url in self.start_urls: 24 yield Request(url=url) 25 # 方式2 26 # req_list = [] 27 # for url in self.start_urls: 28 # req_list.append(Request(url=url)) 29 # return req_list 30 31 def parse(self, response): 32 """ 33 第一次访问响应response 34 :param response: 35 :return: 36 """ 37 from scrapy.spidermiddlewares.depth import DepthMiddleware 38 from scrapy.http import Response 39 # response.request 40 # response.request.meta 此时None 41 print(response.meta.get('depth', 0)) 42 # response.request.meta['depth'] = 0 43 44 page_list = response.xpath('//div[@id="dig_lcpage"]//a/@href').extract() 45 for page in page_list: 46 from scrapy.http import Request 47 page = "https://dig.chouti.com"+page 48 # 继续发请求,回调函数parse 49 yield Request(url=page, callback=self.parse, meta={"proxy": "http://root:woshinizuzong@192.168.10.10:8888/"})
源码看下

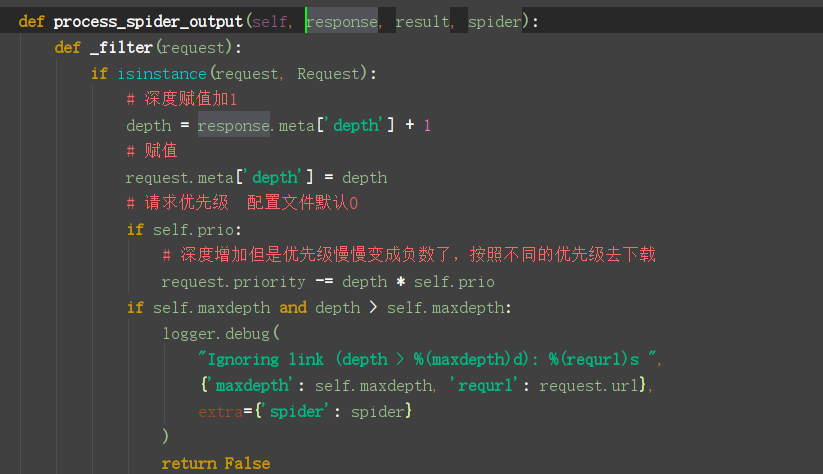

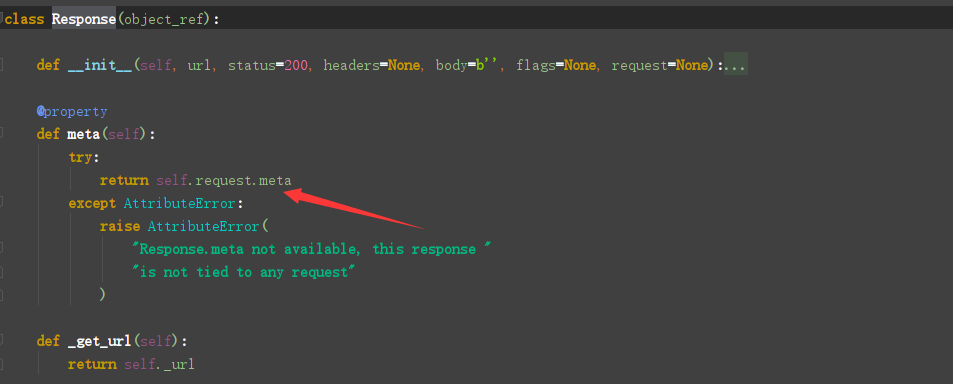
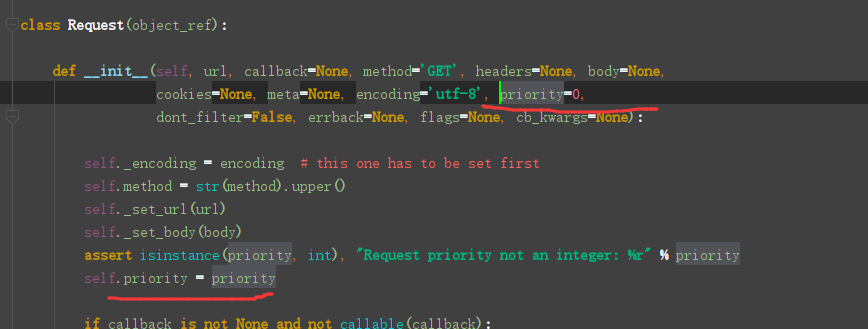
总结:
- 深度 最开始是0每次在yield原来请求中的depth自加1
- 优先级 -= 深度*配置文件优先级默认0