本文主要介绍一下多分类下的ROC曲线绘制和AUC计算,并以鸢尾花数据为例,简单用python进行一下说明。如果对ROC和AUC二分类下的概念不是很了解,可以先参考下这篇文章:http://blog.csdn.net/ye1215172385/article/details/79448575
由于ROC曲线是针对二分类的情况,对于多分类问题,ROC曲线的获取主要有两种方法:
假设测试样本个数为m,类别个数为n(假设类别标签分别为:0,2,...,n-1)。在训练完成后,计算出每个测试样本的在各类别下的概率或置信度,得到一个[m, n]形状的矩阵P,每一行表示一个测试样本在各类别下概率值(按类别标签排序)。相应地,将每个测试样本的标签转换为类似二进制的形式,每个位置用来标记是否属于对应的类别(也按标签排序,这样才和前面对应),由此也可以获得一个[m, n]的标签矩阵L。
比如n等于3,标签应转换为:
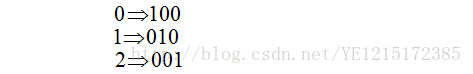
方法1:每种类别下,都可以得到m个测试样本为该类别的概率(矩阵P中的列)。所以,根据概率矩阵P和标签矩阵L中对应的每一列,可以计算出各个阈值下的假正例率(FPR)和真正例率(TPR),从而绘制出一条ROC曲线。这样总共可以绘制出n条ROC曲线。最后对n条ROC曲线取平均,即可得到最终的ROC曲线。
方法2:首先,对于一个测试样本:1)标签只由0和1组成,1的位置表明了它的类别(可对应二分类问题中的‘’正’’),0就表示其他类别(‘’负‘’);2)要是分类器对该测试样本分类正确,则该样本标签中1对应的位置在概率矩阵P中的值是大于0对应的位置的概率值的。基于这两点,将标签矩阵L和概率矩阵P分别按行展开,转置后形成两列,这就得到了一个二分类的结果。所以,此方法经过计算后可以直接得到最终的ROC曲线。
上面的两个方法得到的ROC曲线是不同的,当然曲线下的面积AUC也是不一样的。 在python中,方法1和方法2分别对应sklearn.metrics.roc_auc_score函数中参数average值为'macro'和'micro'的情况。

下面以方法2为例,直接上代码,概率矩阵P和标签矩阵L分别对应代码中的y_score和y_one_hot:
#!/usr/bin/python
# -*- coding:utf-8 -*-
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegressionCV
from sklearn import metrics
from sklearn.preprocessing import label_binarize
if __name__ == '__main__':
np.random.seed(0)
data = pd.read_csv('iris.data', header = None) #读取数据
iris_types = data[4].unique()
n_class = iris_types.size
x = data.iloc[:, :2] #只取前面两个特征
y = pd.Categorical(data[4]).codes #将标签转换0,1,...
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size = 0.6, random_state = 0)
y_one_hot = label_binarize(y_test, np.arange(n_class)) #装换成类似二进制的编码
alpha = np.logspace(-2, 2, 20) #设置超参数范围
model = LogisticRegressionCV(Cs = alpha, cv = 3, penalty = 'l2') #使用L2正则化
model.fit(x_train, y_train)
print '超参数:', model.C_
# 计算属于各个类别的概率,返回值的shape = [n_samples, n_classes]
y_score = model.predict_proba(x_test)
# 1、调用函数计算micro类型的AUC
print '调用函数auc:', metrics.roc_auc_score(y_one_hot, y_score, average='micro')
# 2、手动计算micro类型的AUC
#首先将矩阵y_one_hot和y_score展开,然后计算假正例率FPR和真正例率TPR
fpr, tpr, thresholds = metrics.roc_curve(y_one_hot.ravel(),y_score.ravel())
auc = metrics.auc(fpr, tpr)
print '手动计算auc:', auc
#绘图
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
#FPR就是横坐标,TPR就是纵坐标
plt.plot(fpr, tpr, c = 'r', lw = 2, alpha = 0.7, label = u'AUC=%.3f' % auc)
plt.plot((0, 1), (0, 1), c = '#808080', lw = 1, ls = '--', alpha = 0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=13)
plt.ylabel('True Positive Rate', fontsize=13)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
plt.title(u'鸢尾花数据Logistic分类后的ROC和AUC', fontsize=17)
plt.show()
实验输出结果:

可以从上图看出,两者计算结果一致!
实验绘图结果:

这里是micro average ROC:
https://blog.csdn.net/YE1215172385/article/details/79443552
macro average ROC 可以参考:
https://blog.csdn.net/xyz1584172808/article/details/81839230