在学习c语言提高总结了笔记,并分享出来。有问题请及时联系博主:Alliswell_WP,转载请注明出处。
02-c提高07day
目录:
一、链表
1、链表逆序算法
2、作业——排序算法
二、预处理
1、预处理的基本概念
2、文件包含指令(#include)
(1)文件包含处理
(2)#incude<>和#include"“区别
3、宏定义
(1)无参数的宏定义(宏常量)
(2)带参数的宏定义(宏函数)
4、条件编译
(1)基本概念
(2)条件编译
5、一些特殊的预定宏
三、动态库和静态库(动态库的封装与使用)
1、库的基本概念
2、 windows下静态库创建和使用
(1)静态库的创建
(2)静态库的使用
(3)静态库优缺点
3、 windows下动态库创建和使用
(1)动态库的创建
(2)动态库的使用
四、递归函数
1、递归函数基本概念
2、普通函数调用
3、递归函数调用
4、递归实现字符串反转
五、面向接口编程
1、案例背景
2、案例需求
3、案例要求
4、编程提示
练习:接口的封装设计
一、链表
1、链表逆序算法
练习:编写一个程序,将一个单链表逆序。例如:原链表为A->B->C->D,使链表逆置成为D->C->B->A。
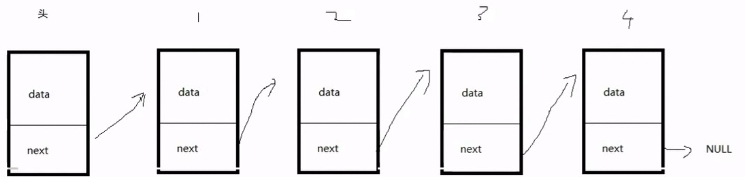
代码如下:
1 void Reverse_LinkList(struct LinkNode* header) 2 { 3 if(NULL = header) 4 { 5 return; 6 } 7 struct LinkNode* pPrev = NULL;//初始置空 8 struct LinkNode* pCurrent = header->next; 9 struct LinkNode* pNext = NULL; 10 11 while(pCurrent != NULL) 12 { 13 pNext = pCurrent->next; 14 pCurrent->next = pPrev;//第一次pCurrent->next指向空,以后指向前一个结点 15 16 pPrev = pCurrent;//移动 17 pCurrent = pNext; 18 } 19 header->next = pPrev;//当pCurrent指向空退出,pPrev指向最后一个结点 20 }
2、作业——排序算法
编写一个名叫sort的函数,它用于对一个任意类型的数组进行排序。为了使函数更为通用,它的其中一个参数必须是一个指向比较回调函数的指针,该回调函数由调用程序提供。比较函数接受两个参数,也就是两个指向需要比较的值的指针。如果两个值相等,函数返回0;如果第1个值小于第2个,函数返回一个小于0的整数;如果第1个值大于第2个值,函数返回一个大于0的整数。
sort函数的参数是:
1.一个指向需要排序的数组的第1个值的指针。
2.数组中元素的个数。
3.一个指向比较回调函数的指针。
代码如下:
1 #define _CRT_SECURE_NO_WARNINGS 2 #include<stdio.h> 3 #include<string.h> 4 #include<stdlib.h> 5 6 void SelectSort(void* ptr, int ele_size, int ele_num, int(*compare)(void*, void*)) 7 { 8 char* temp = malloc(ele_size); 9 10 for(int i = 0; i < ele_num; ++i) 11 { 12 int minOrmax = i; 13 14 for(int j = i + 1; j < ele_num; ++j) 15 { 16 17 char* pJ = (char*)ptr + j * ele_size; 18 char* pMinOrMax = (char*)ptr + minOrMax * ele_size; 19 if(compare(pJ, pMinOrMax)) 20 { 21 minOrMax = j; 22 } 23 } 24 25 if(minOrMax != i) 26 { 27 char* pMinOrMax = (char*)ptr + minOrMax * ele_size; 28 char* pI = (char*)ptr + i * ele_size; 29 30 //对下标为j和minOrmax的两个数进行交换 31 memcpy(temp, pI, ele_size); 32 memcpy(pI, pMinOrMax, ele_size); 33 memcpy(pMinOrMax, temp, ele_size); 34 } 35 36 } 37 if(temp != NULL) 38 { 39 free(temp); 40 temp = NULL; 41 } 42 43 } 44 45 //比较函数 46 int compareInt(void* d1, void* d2) 47 { 48 int* p1 = (int*)d1; 49 int* p2 = (int*)d2; 50 51 return *p1 < *p2;//改为*p1 < *p2变为由大到小排序 52 } 53 54 55 void test() 56 { 57 int arr[] = { 7, 4, 9, 2, 1}; 58 SelectSort(arr, sizeof(int), sizeof(arr)/sizeof(int), compareInt); 59 for(int i = 0; i < 5; ++i) 60 { 61 printf("%d ", arr[i]); 62 } 63 printf(" "); 64 } 65 66 67 int main(){ 68 69 test(); 70 71 system("pause"); 72 return EXIT_SUCCESS; 73 }
二、预处理
1、预处理的基本概念
C语言对源程序处理的四个步骤:预处理、编译、汇编、链接。
预处理是在程序源代码被编译之前,由预处理器(Preprocessor)对程序源代码进行的处理。这个过程并不对程序的源代码语法进行解析,但它会把源代码分割或处理成为特定的符号为下一步的编译做准备工作。(文本替换)
2、文件包含指令(#include)
(1)文件包含处理
“文件包含处理”是指一个源文件可以将另外一个文件的全部内容包含进来。C语言提供了#include命令用来实现“文件包含”的操作。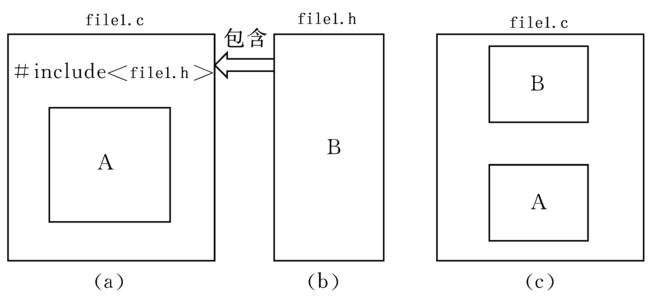
(2)#incude<>和#include"“区别
·““表示系统先在file1.c所在的当前目录找file1.h,如果找不到,再按系统指定的目录检索。
·<>表示系统直接按系统指定的目录检索。
注意:
1)#include<>常用于包含库函数的头文件;
2)#include““常用于包含自定义的头文件;
3)理论上#include可以包含任意格式的文件(.c.h等),但一般用于头文件的包含;
3、宏定义
(1)无参数的宏定义(宏常量)
如果在程序中大量使用到了100这个值,那么为了方便管理,我们可以将其定义为:const int num=100;但是如果我们使用num定义一个数组,在不支持c99标准的编译器上是不支持的,因为num不是一个编译器常量,如果想得到了一个编译器常量,那么可以使用:
1 #define num 100
在编译预处理时,将程序中在该语句以后出现的所有的num都用100代替。这种方法使用户能以一个简单的名字代替一个长的字符串在预编译时将宏名替换成字符串的过程称为“宏展开”。宏定义,只在宏定义的文件中起作用。(默认的作用域:从定义到文件结尾或#undef num)
1 #define PI 3.1415 2 void test(){ 3 doubler=10.0; 4 doubles=PI*r*r; 5 printf("s=%lf ",s); 6 }
说明:
1)宏名一般用大写,以便于与变量区别;
2)宏定义可以是常数、表达式等;
3)宏定义不作语法检查,只有在编译被宏展开后的源程序才会报错;
4)宏定义不是C语言,不在行未加分号;
5)宏名有效范围为从定义到本源文件结束;
6)可以用#undef命令终止宏定义的作用域;
7)在宏定义中,可以引用已定义的宏名;
(2)带参数的宏定义(宏函数)
在项目中,经常把一些短小而又频繁使用的函数写成宏函数,这是由于宏函数没有普通函数参数压栈、跳转、返回等的开销,可以调高程序的效率。
宏通过使用参数,可以创建外形和作用都与函数类似地类函数宏(function-like macro).宏的参数也用圆括号括起来。
1 #define SUM(x,y) ((x)+(y)) 2 void test(){ 3 //仅仅只是做文本替换下例替换为int ret=((10)+(20)); 4 //不进行计算 5 int ret=SUM(10,20); 6 printf("ret:%d ",ret); 7 }
注意:
1)宏的名字中不能有空格,但是在替换的字符串中可以有空格。ANSI C允许在参数列表中使用空格;
2)用括号括住每一个参数,并括住宏的整体定义。
3)用大写字母表示宏的函数名。
4)如果打算宏代替函数来加快程序运行速度。假如在程序中只使用一次宏对程序的运行时间没有太大提高。
4、条件编译
(1)基本概念
一般情况下,源程序中所有的行都参加编译。但有时希望对部分源程序行只在满足一定条件时才编译,即对这部分源程序行指定编译条件。
(2)条件编译
■防止头文件被重复包含引用;
1 #ifndef _SOMEFILEH 2 #define _SOMEFILEH 3 4 //需要声明的变量、函数 5 //宏定义 6 //结构体 7 8 #endif
5、一些特殊的预定宏
C编译器,提供了几个特殊形式的预定义宏,在实际编程中可以直接使用,很方便。
1 //__FILE__宏所在文件的源文件名 2 //__LINE__宏所在行的行号 3 //__DATE__代码编译的日期 4 //__TIME__代码编译的时间 5 6 void test() 7 { 8 printf("%s ",__FILE__); 9 printf("%d ",__LINE__); 10 printf("%s ", __DATE__); 11 printf("%s ",__TIME__); 12 }
三、动态库和静态库(动态库的封装与使用)
1、库的基本概念
库是已经写好的、成熟的、可复用的代码。每个程序都需要依赖很多底层库,不可能每个人的代码从零开始编写代码,因此库的存在具有非常重要的意义。
在我们的开发的应用中经常有一些公共代码是需要反复使用的,就把这些代码编译为库文件。
库可以简单看成一组目标文件的集合将这些目标文件经过压缩打包之后形成的一个文件。像在Windows这样的平台上,最常用的c语言库是由集成按开发环境所附带的运行库,这些库一般由编译厂商提供。
2、 windows下静态库创建和使用
(1)静态库的创建
1.创建一个新项目,在已安装的模板中选择“常规”,在右边的类型下选择“空项目”,在名称和解决方案名称中输入staticlib。点击确定。
2.在解决方案资源管理器的头文件中添加:mylib.h文件,在源文件添加mylib.c文件(即实现文件)。
3.在mylib.h文件中添加如下代码:
1 #pragma once 2 3 #ifdef __cplusplus 4 extern "C"{ 5 #endif 6 7 int myAdd(int a, int b); 8 9 10 #ifdef __cplusplus 11 } 12 #endif
4.在mylib.c文件中添加如下代码:
1 #include "mylib.h" 2 3 int myAdd(int a, int b) 4 { 5 return a + b; 6 }
5.配置项目属性。因为这是一个静态链接库,所以应在项目属性的“配置属性”下选择“常规”,在其下的配置类型中选择“静态库(.lib)。
6.编译生成新的解决方案,在Debug文件夹下会得到mylib.lib(对象文件库),将该.lib文件和相应头文件给用户,用户就可以使用该库里的函数了。
编写完后把staticlib.lib和头文件(mylib.h)给其他用户。
(2)静态库的使用
方法一:配置项目属性
A、添加工程的头文件目录:工程---属性---配置属性---c/c++---常规---附加包含目录:加上头文件存放目录。
B、添加文件引用的lib 静态库路径:工程---属性---配置属性---链接器---常规---附加库目录:加上lib文件存放目录。
C、然后添加工程引用的lib文件名:工程---属性---配置属性---链接器---输入---附加依赖项:加上lib文件名。
方法二:使用编译语句
#pragna comment(lib,"./mylib.lib")
方法三:添加工程中
就像你添加.h和.c文件一样把lib文件添加到工程文件列表中去.
切换到“解决方案视图",-->选中要添加lib的工程-->点击右键-->"在文件资源管理器中打开文件夹",把lib和.h拷贝进去->然后,"添加“->“现有项“-->选择lib文件和.h文件-->确定.
(3)静态库优缺点
■静态库对函数库的链接是放在编译时期完成的,静态库在程序的链接阶段被复制到了程序中,和程序运行的时候没有关系;
■程序在运行时与函数库再无瓜葛,移植方便。
■浪费空间和资源,所有相关的目标文件与牵涉到的函数库被链接合成一个可执行文件。
内存和磁盘空间
静态链接这种方法很简单,原理上也很容易理解,在操作系统和硬件不发达的早期,绝大部门系统采用这种方案。随着计算机软件的发展,这种方法的缺点很快暴露出来,那就是静态链接的方式对于计算机内存和磁盘空间浪费非常严重。特别是多进程操作系统下,静态链接极大的浪费了内存空间。在现在的linux系统中,一个普通程序会用到c语言静态库至少在1MB以上,那么如果磁盘中有2000个这样的程序,就要浪费将近2GB的磁盘空间。
程序开发和发布
空间浪费是静态链接的一个问题,另一个问题是静态链接对程序的更新、部署和发布也会带来很多麻烦。比如程序中所使用的mylib.lib是由一个第三方厂商提供的,当该厂商更新容量mylib.lib的时候,那么我们的程序就要拿到最新版的mylib.lib,然后将其重新编译链接后,将新的程序整个发布给用户。这样的做缺点很明显,即一旦程序中有任何模块更新,整个程序就要重新编译链接、发布给用户,用户要重新安装整个程序。
3、 windows下动态库创建和使用
要解决空间浪费和更新困难这两个问题,最简单的办法就是把程序的模块相互分割开来,形成独立的文件,而不是将他们静态的链接在一起。简单地讲,就是不对哪些组成程序的目标程序进行链接,等程序运行的时候才进行链接。也就是说,把整个链接过程推迟到了运行时再进行,这就是动态链接的基本思想。
(1)动态库的创建
1.创建一个新项目,在已安装的模板中选择“常规”,在右边的类型下选择“空项目”,在名称和解决方案名称中输入mydl。点击确定。
2.在解决方案资源管理器的头文件中添加,mydll.h文件,在源文件添加mydllc文件(即实现文件)。
3.在mydll.h文件中添加如下代码:
1 #pragma once 2 3 #ifdef __cplusplus 4 extern "C"{ 5 #endif 6 7 //内部函数,外部函数(导出函数) 8 __declspec(dllexport) int myAdd(int a, int b); 9 10 11 #ifdef __cplusplus 12 } 13 #endif
4.在mydll.c文件中添加如下代码:
1 #include "mydll.h" 2 3 int myAdd(int a, int b) 4 { 5 return a + b - 10; 6 }
5.配置项目属性。因为这是一个动态链接库,所以应在项目属性的“配置属性”下选择“常规”,在其下的配置类型中选择“动态库(.dll)。
6.编译生成新的解决方案,在Debug文件夹下会得到mydll.dll(对象文件库),将该.dll文件、lib文件和相应头文件给用户,用户就可以使用该库里的函数了。
疑问一:__declspec(dllexport)是什么意思?
动态链接库中定义有两种函数:导出函数(export function)和内部函数(internal function)。导出函数可以被其它模块调用,内部函数在定义它们的DLL程序内部使用。
疑问二:动态库的lib文件和静态库的lib文件的区别?
在使用动态库的时候,往往提供两个文件:一个引入库(.lib)文件(也称“导入库文件”和一个DLL(.dll)文件。虽然引入库的后缀名也是“lib",但是,动态库的引入库文件和静态库文件有着本质的区别,对一个DLL文件来说,其引入库文件(.lib)包含该DLL导出的函数和变量的符号名,而.dll文件包含该DLL实际的函数和数据。在使用动态库的情况下,在编译链接可执行文件时,只需要链接该DLL的引入库文件,该DLL中的函数代码和数据并不复制到可执行文件,直到可执行程序运行时,才去加载所需的DLL,将该DLL映射到进程的地址空间中,然后访问DLL中导出的函数。
(2)动态库的使用
方法一:隐式调用
创建主程序TestDll,将mydll.h、mydl.dl和mydl.lib复制到源代码目录下。
(PS:头文件Func.h并不是必需的,只是C++中使用外部函数时,需要先进行声明)
在程序中指定链接引用链接库:#pragma comment(lib,"/mydllib")
练习:test.c
1 #define _CRT_SECURE_NO_WARNINGS 2 #include<stdio.h> 3 #include<string.h> 4 #include<stdlib.h> 5 6 7 //1.栈区的内存自动申请自动释放,不需要程序手动管理 8 int* myFunc() 9 { 10 int a = 10; 11 return &a;//不要返回局部变量的地址 12 } 13 14 void test01() 15 { 16 //我们并不关心a的值是多少,因为局部变量a的内存已经被回收 17 int* p = myFunc(); 18 printf("*p = %d ", *p); 19 } 20 21 char *getString() 22 { 23 char str[] = "hello world"; 24 return str; 25 } 26 27 void test02() 28 { 29 char *s = NULL; 30 s = getString(); 31 printf("s = %s ", s); 32 } 33 34 int main(){ 35 36 //test01(); 37 test02(); 38 39 system("pause"); 40 return EXIT_SUCCESS; 41 }
方法二:显式调用
1 HANDLE hD11;//声明一个dl1实例文件句柄 2 hD11=LoadLibrary("mydl1.d11");//导入动态链接库 3 MYFUNC minus _test;//创建函数指针 4 //获取导入函数的函数指针 5 minus_test=(MYFUNC)GetProcAddress(hD11,"myminus");
四、递归函数
1、递归函数基本概念
C通过运行时堆栈来支持递归函数的实现。递归函数就是直接或间接调用自身的函数。
2、普通函数调用
1 void funB(int b){ 2 printf("b=%d ",b); 3 } 4 void funA(int a){ 5 funB(a-1); 6 printf("a=%d ",a); 7 } 8 9 int main(void){ 10 funA(2); 11 printf("main "); 12 return 0; 13 }
函数调用的流程如下:
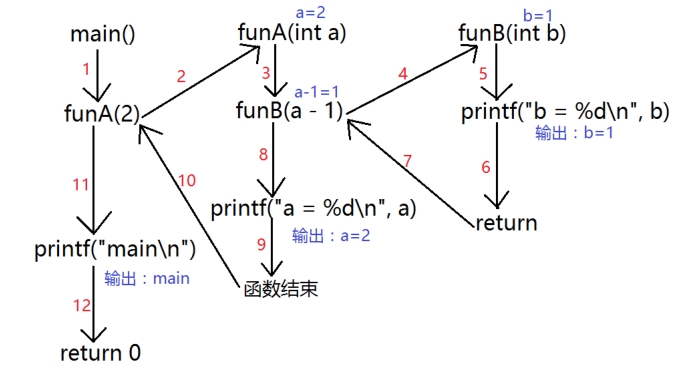
3、递归函数调用
1 void fun(int a){ 2 if(a==1){ 3 printf("a=%d ",a); 4 return;//中断函数很重要 5 } 6 7 fun(a-1); 8 printf("a=%d ",a); 9 } 10 11 int main(void){ 12 13 fun(2); 14 printf("main "); 15 return 0; 16 }
函数调用流程如下:
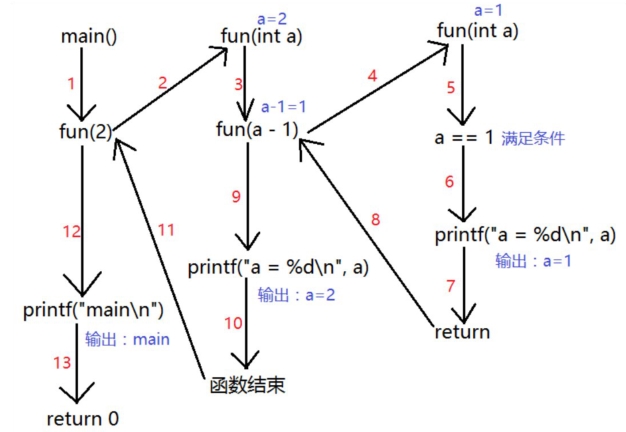
注意:
1)递归函数必须有退出条件(结束条件)
2)虽然递归调用的是自身的函数,但是每一次函数调用都有自己独立的堆栈。
作业:
递归实现给出一个数8793,依次打印千位数字8、百位数字7、十位数字9、个位数字3。
1 void recursion(int val){ 2 if(val==0){ 3 return; 4 } 5 int ret=val/10; 6 recursion(ret); 7 printf("%d",val%10); 8 }
4、递归实现字符串反转
1 int reversel(char *str){ 2 if(str==NULL) 3 { 4 return -1; 5 } 6 if(*str=='�')//首先要确定-函数递归调用结束条件 7 { 8 return 0; 9 } 10 11 reversel(str+1); 12 printf("%c",*str); 13 14 return 0; 15 } 16 char buf[1024]={0};//全局变量 17 18 int reverse2(char *str){ 19 if(str==NULL) 20 { 21 return -1; 22 } 23 if(*str=='�')//函数递归调用结束条件 24 { 25 return 0; 26 } 27 28 reverse2(str+1); 29 strncat(buf,str,1); 30 31 return 0; 32 33 int reverse3(char *str,char *dst){ 34 if(str==NULL || dst==NULL) 35 { 36 return -1; 37 } 38 if(*str=='�')//函数递归调用结束条件 39 { 40 return 0; 41 } 42 reverse3(str+1); 43 strncat(dst,str,1); 44 45 return 0; 46 47 }
练习:链表逆序打印
1 void reversePrintList(struct LinkNode* pCurrent) 2 { 3 if(NULL == pCurrent) 4 { 5 return; 6 } 7 8 reversePrintList(pCurrent->next); 9 printf("%d ", pCurrent->data); 10 } 11 12 //链表逆序打印 13 void test() 14 { 15 //初始化链表 16 struct LinkNode* header = Init_LinkList(); 17 18 //链表逆序打印 19 printf(" "); 20 reversePrintList(header->next); 21 //正序打印(对比) 22 printf(" "); 23 Foreach_linkList(header); 24 25 //销毁链表 26 Destroy_LinkList(header); 27 }
五、面向接口编程
1、案例背景
一般的企业信息系统都有成熟的框架。软件框架一般不发生变化,能自由的集成第三方厂商的产品。
2、案例需求
要求在企业信息系统框架中集成第三方厂商的socket通信产品和第三方厂商加密产品。软件设计要求:模块要求松、接口要求紧。
3、案例要求
1)能支持多个厂商的socket通信产品入围
2)能支持多个第三方厂商加密产品的入围
3)企业信息系统框架不轻易发生框架
4、编程提示
1)抽象通信接口结构体设计(CSocketProtocol)
2)框架接口设计(framework)
3)a)通信厂商1入围(CScklmp1)
b)通信厂商2入围(CSckImp2)
4)a)抽象加密接口结构体设计(CEncDesProtocol)
b)升级框架函数(增加加解密功能)
c)加密厂商1入围(CHwlmp)、加密厂商2入围(CCiscolmp)
5)框架接口分文件
练习:接口的封装设计
1 //初始化网络连接句柄 socket,也叫环境初始化 2 int socketclient_init(void** handle); 3 4 //发送报文接口 5 int socketclient_send(void* handle,unsigned char* buf,int buflen); 6 7 //接收报文接口 8 int socketclient recv(void* handle,unsigned char* buf,int* buflen); 9 10 //socket环境释放 11 int socketclient_destroy(void** handle);
test.c
1 #define _CRT_SECURE_NO_WARNINGS 2 #include<stdio.h> 3 #include<string.h> 4 #include<stdlib.h> 5 #include"CScklmp1.h" 6 7 //初始化 8 typedef void(*init_CSocketclient)(void** handle); 9 //发送接口 10 typedef void(*send_CSocketProtocol)(void* handle, unsigned char* sendData, int senLen); 11 //接收接口 12 typedef void(*recv_CSocketProtocol)(void* handle, unsigned char* recvData, int* recvLen); 13 //关闭 14 typedef void(*close_CSocketProtocol)(void* handle); 15 16 //业务代码 17 void FrameWork(init_CSocketclient init, 18 send_CSocketProtocol send, 19 recv_CSocketProtocol recv, 20 close_CSocketProtocol close) 21 { 22 //初始化连接 23 void* handle = NULL; 24 init(&handle); 25 26 //发送数据 27 char buf[] = "hello world!"; 28 int len = strlen(buf); 29 send(handle, buf, len); 30 31 //接收数据 32 char recvBuf[1024] = {0}; 33 int recvLen = 0; 34 recv(handle, recvBuf, &recvLen); 35 printf("接收到的数据:%s ", recvBuf); 36 printf("接收到的数据:%d ", recvLen); 37 38 //关闭连接 39 close(handle); 40 handle = NULL; 41 } 42 43 void test() 44 { 45 FrameWork(init_CSckImp1, send_CSckImp1, recv_CSckImp1, close_CSckImp1); 46 47 } 48 49 int main(){ 50 51 test(); 52 53 system("pause"); 54 return EXIT_SUCCESS; 55 }
CScklmp1.h
1 #define _CRT_SECURE_NO_WARNINGS 2 3 #pragma once 4 5 #include<stdlib.h> 6 #include<stdio.h> 7 #include<string.h> 8 9 //初始化 10 void init_CScklmp1(void** handle); 11 //发送接口 12 void send_CScklmp1(void* handle, unsigned char* sendData, int sendLen); 13 //接收接口 14 void recv_CScklmp1(void* handle, unsigned char* recvData, int* recvLen); 15 //关闭 16 void close_CScklmp1(void* handle);
CScklmp1.c
1 #include"CScklmp1.h" 2 3 struct Info 4 { 5 char data[1024]; 6 int len; 7 }; 8 9 //初始化 10 void init_CScklmp1(void** handle) 11 { 12 if(NULL == handle) 13 { 14 return; 15 } 16 struct Info* info = malloc(sizeof(struct Info)); 17 memset(info, 0, sizeof(struct Info)); 18 19 *handle = info; 20 } 21 //发送接口 22 void send_CScklmp1(void* handle, unsigned char* sendData, int sendLen) 23 { 24 if(NULL == handle) 25 { 26 return; 27 } 28 if(NULL == sendData) 29 { 30 return; 31 } 32 struct Info* info = (struct Info*)handle; 33 34 strncpy(info->data, sendData, sendLen); 35 info->len = sendLen; 36 37 } 38 //接收接口 39 void recv_CScklmp1(void* handle, unsigned char* recvData, int* recvLen) 40 { 41 if(NULL == handle) 42 { 43 return; 44 } 45 if(NULL == recvData) 46 { 47 return; 48 } 49 if(NULL == recvLen) 50 { 51 return; 52 } 53 54 struct Info* info = (struct Info*)handle; 55 strncpy(recvData, info->data, info->len); 56 *recvLen = info->len; 57 } 58 //关闭 59 void close_CScklmp1(void* handle) 60 { 61 if(NULL == handle) 62 { 63 return; 64 } 65 free(handle); 66 handle = NULL; 67 }
参考:
1)讲义:豆丁网:https://www.docin.com/p-2159552288.html
道客巴巴:https://www.doc88.com/p-6951788232280.html
在学习c语言提高总结了笔记,并分享出来。有问题请及时联系博主:Alliswell_WP,转载请注明出处。