此部分是计算机视觉部分,主要侧重在底层特征提取,视频分析,跟踪,目标检测和识别方面等方面。对于自己不太熟悉的领域比如摄像机标定和立体视觉,仅仅列出上google上引用次数比较多的文献。有一些刚刚出版的文章,个人非常喜欢,也列出来了。
18. Image Stitching
图像拼接,另一个相关的词是Panoramic。在Computer Vision: Algorithms and Applications一书中,有专门一章是讨论这个问题。这里的两面文章一篇是综述,一篇是这方面很经典的文章。
[2006 Fnd] Image Alignment and Stitching A Tutorial
[2007 IJCV] Automatic Panoramic Image Stitching using Invariant Features
若引用文献:Szeliski R. Image Alignment and Stitching[M]// Handbook of Mathematical Models in Computer Vision. 2006.
翻译
图像对齐和拼接——http://tongtianta.site/paper/21917
作者:Richard Szeliski
摘要 -将多张图像拼接在一起以创建美丽的高分辨率全景图是图像配准和融合中最受欢迎的消费者应用之一。 在本章中,我将回顾基于全景图像拼接的运动模型(几何变换),讨论基于直接强度和基于特征的配准算法,并介绍在重叠图像之间建立高精度对应关系所需的全局和局部对齐技术。 然后,我讨论了各种合成选项,包括多频带和渐变域混合以及消除模糊和重影图像的技术。 由此产生的技术可用于创建用于静态或交互式查看的高质量全景图。
1 简介
对齐图像并将其缝合成无缝光马赛克的算法是计算机视觉中最古老,应用最广泛的算法之一。图像拼接算法已经使用了数十年,以创建用于生成数字地图和卫星照片的高分辨率照片马赛克[20]。帧速率图像对齐方式用于具有图像稳定功能的每台摄录机。当今的数码相机可以“开箱即用”图像拼接算法,并可用于创建精美的高分辨率全景图。
在胶片摄影中,本世纪初开发了专用相机来拍摄广角全景照片,通常是在相机沿其轴旋转时通过垂直狭缝将胶片曝光[18]。在1990年代中期,图像对齐技术开始应用于由常规手持相机制作的广角无缝全景图[17、9、27]。该领域的最新工作已解决了以下需求:计算全局一致的对齐方式[30、23、25],消除由于视差和物体移动而导致的“重影” [20、10、25、32、1],以及处理变化的曝光[17,32,1]。 (其中一些论文的集合可以在[3]中找到。)这些技术催生了大量的商业缝合产品[9,22]。
虽然上述大多数技术都是通过直接最小化像素间的差异来工作的,但不同种类的算法却是通过提取稀疏特征集然后将它们彼此匹配来进行工作的[8,6]。基于特征的方法的优点是对场景移动的鲁棒性更高,并且可能更快。但是,它们的最大优点是“识别全景图”的能力,即自动发现无序图像集之间的邻接(重叠)关系,这使其非常适合全自动拼接由休闲用户拍摄的全景图[6] ]。
那么,图像拼接所需的基本算法是什么?首先,我们必须确定将一个图像中的像素坐标与另一个图像中的像素坐标相关联的适当运动模型(第2节)。接下来,我们必须使用直接像素间比较与梯度下降或基于特征的对齐技术(第3节),以某种方式估计与各对图像相关的正确对齐。我们还必须开发算法,以从大量重叠照片中计算出全局一致的对齐方式(第4节)。一旦估计了路线,我们就必须选择一个最终的合成表面,在该表面上翘曲并放置所有已对准的图像(第5节)。我们还需要无缝地融合重叠的图像,即使存在视差,镜头失真,场景运动和曝光差异(第6节)。在本章的最后一部分中,我将讨论图像拼接的其他应用程序和开放式研究问题。有关所有这些组件的更详细的教程,请参阅[28]。
2 运动模型
在我们可以缝合图像以创建全景之前,我们需要建立数学关系,以将像素坐标从一幅图像映射到另一幅图像。从简单的2D转换到平面透视模型,3D摄像机旋转以及非平面(例如圆柱)表面,各种此类参数化运动模型都是可能的[27、30]。
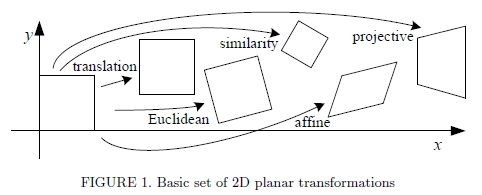
图1. 2D平面变换的基本集合
图1显示了许多常用的2D平面变换,而表1.1列出了它们的数学形式以及其固有维数。 想到这些的最简单方法是将其作为一组(可能受限制的)3×3矩阵,它们在2D齐次坐标矢量上运行,x0 =(x0,y0,1)和x =(x,y,1),s.t.
其中〜表示按比例相等的等式,H是表1.1中给出的3×3矩阵之一。
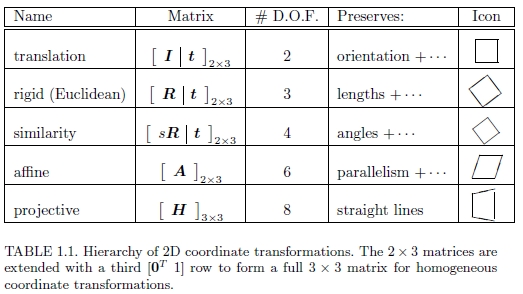
表1.1 2D坐标转换的层次结构。 将2×3矩阵扩展为第三行[0T 1],以形成完整的3×3矩阵,以进行均质坐标转换。
2D转换对于跟踪视频中的小片段和补偿瞬时相机抖动很有用。 这个简单的两参数模型是Lucas和Kanade的补丁跟踪器[16]最常用的模型,尽管事实上,他们的论文还描述了仿射运动模型的使用方法。
三参数旋转+平移(也称为2D刚体运动或2D欧几里得变换)可用于建模平面内旋转,例如,在平板扫描仪上扫描较大图像的不同部分时。
缩放旋转(也称为相似度变换)添加了第四个各向同性缩放参数s。 对于缓慢平移和缩放的相机,这是一个很好的模型,尤其是当相机具有较长的焦距时。 相似度变换保留线之间的角度。
六参数仿射变换使用常规2×3矩阵(或等效地,底行为[0 0 1]的3×3矩阵)。 它是由更复杂的转换引起的局部变形的良好模型,并且还模拟了正交摄影机观察到的3D表面缩短。 仿射变换保留线之间的并行性。
最通用的平面2D变换是由3×3矩阵H表示的八参数透视变换或单应性。 必须对乘以Hx的结果进行归一化,以获得不均匀的结果,即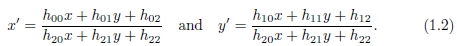
透视变换保留直线,并且正如我们将很快看到的那样,它是适用于在一般3D运动下观察到的平面和在纯相机旋转下观察到的3D场景的合适模型。
在3D中,中央投影过程通过相机原点上的针孔将3D坐标x =(x,y,z)映射到2D坐标x0 =(x',y',1)到2D投影平面上,沿z轴的距离为f,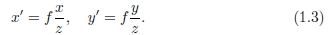
透视投影也可以使用3×3上三角固有校正矩阵K表示,该矩阵可以考虑非正方形像素,偏斜和可变的光学中心位置。 但是,实际上,在拼接来自常规相机的图像时,上面使用的简单焦距缩放可提供高质量的结果。
当我们从不同的相机位置和/或方向拍摄3D场景的两个图像时会发生什么? 通过3D刚体(欧几里得)运动E0和透视投影K0的组合,将3D点p =(X,Y,Z,1)映射到图像坐标x0',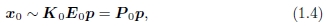
其中3×4矩阵P0通常称为相机矩阵。 如果我们有一个2D点x0,我们只能将其投射回空间中的3D射线中。 但是,对于一个平面场景,我们还有一个附加的平面方程 ˆn0·p + d0 = 0,我们可以使用它来扩充P0以获得〜P0,然后可以反转3D→2D投影。 然后,如果将这一点投影到另一个图像中,则可以得到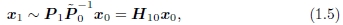
其中H10是一般的3×3单应矩阵,x1和x0是2D齐次坐标。 这证明了使用8参数单应性作为平面场景镶嵌的通用对齐模型[17,27]。
更为有趣的情况是相机进行纯旋转时(相当于假设所有点都远离相机)。 在这种情况下,我们得到了更为严格的3×3单应性
实际上,我们通常设置Kk = diag(fk,fk,1)。 因此,我们得到与焦距f 已知,固定或可变的情况相对应的3、4或5参数3D旋转运动模型,而不是与一对图像相关的一般8参数单应性。 30]。 估计与每个图像相关联的3D旋转矩阵(以及可选的焦距)本质上比估计完整的8 d.f.f稳定得多。 单应性,这使其成为大规模图像拼接算法的选择方法[30,25,6]。
使用单应性或3D旋转的另一种方法是先将图像扭曲为圆柱坐标,然后使用纯平移模型对齐它们[9]。 不幸的是,这仅在所有图像均使用水平摄像机或已知倾斜角度拍摄的情况下才有效。 在[30,28]中可以找到在平面坐标与圆柱/球形坐标之间映射的方程式。
3 直接和基于特征的对齐
一旦我们选择了合适的运动模型来描述一对图像之间的对准,就需要设计某种方法来估计其参数。一种方法是使图像彼此相对移动或扭曲,并查看像素的一致性。与稍后介绍的基于特征的方法相反,此类方法通常称为直接方法。
3.1直接方法
要使用直接方法,必须首先选择合适的误差度量来比较图像。一旦确定了这一点,就必须设计一种合适的搜索技术。最简单的搜索技术是穷举尝试所有可能的比对,即进行完整搜索。在实践中,这可能太慢,因此已经开发了基于图像金字塔的分层粗到细技术[4]。或者,可以使用傅立叶变换来加快计算速度[28]。为了获得对准中的亚像素精度,通常使用基于图像函数的泰勒级数展开的增量方法[16]。这些也可以应用于参数运动模型[16,4]。这些技术中的每一种在[28]中有更详细的描述,并在下面进行了概述。
在两个图像之间建立对齐的最简单方法是相对于另一个图像移动一个图像。 给定在离散像素位置{xi =(xi,yi)}上采样的模板图像I0(x),我们希望找到它在图像I1(x)中的位置。 解决此问题的最小二乘方法是找到平方差和(SSD)函数的最小值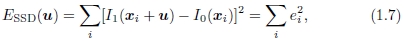
其中u =(u,v)是位移矢量,而ei = I1(xi + u)-I0(xi)称为残差。
通常,位移u可以是分数,因此必须将合适的插值函数应用于图像I1(x)。 实际上,通常使用双线性插值法,但是双三次插值法可能会产生更好的结果。
通过用鲁棒函数p(ei)代替平方误差项,可以使上述误差度量对离群值更鲁棒[26]。我们还可以对被比较图像之间的潜在偏差和增益变化进行建模,并关联空间变化的权重 具有不同像素的像素,这是处理部分重叠和已从其中一幅图像[2,28]中“切除”的区域的原则方法。 本章[28]的扩展版本还讨论了相关性(和相位相关性),以替代鲁棒的像素差异匹配。 它还讨论了如何从粗到精(分层)技术[4]和傅立叶变换来加快搜索速度,以实现最佳对齐。 (不幸的是,傅立叶变换仅适用于纯平移和一组非常有限的(小运动)相似变换。)
增量优化
为了获得更好的子像素估计,我们可以使用以下几种技术之一。一种可能是评估(u, v)的几个离散(整数或小数)值,以迄今发现的最佳值为准,并内插匹配分数以找到解析最小值。卢卡斯和卡纳德[16]首次提出的一种更常用的方法是使用图像函数的泰勒级数展开对SSD能量函数(1.7)进行梯度下降,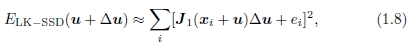
其中
是xi + u处的图像梯度。
通过求解相关的正规方程,可以使上述最小二乘问题最小化。
其中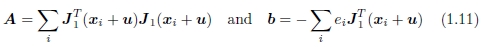
分别称为Hessian和梯度加权残差向量。
可以与估计I1(xi + u)所需的图像扭曲同时评估J1(xi + u)所需的梯度,实际上,通常将其计算为图像插值的副产品。 如果您担心效率问题,可以将这些渐变替换为模板图片中的渐变,
由于接近正确的对齐方式,因此模板和目标图像应该看起来相似。 这具有允许对Hessian和Jacobian图像进行预计算的优势,这可以节省大量计算时间[2]。
参数运动
许多图像对齐任务,例如使用手持摄像机进行图像拼接,都需要使用更复杂的运动模型。由于这些模型通常比纯转换具有更多的参数,因此无法在可能的值范围内进行全面搜索。相反,可以将增量Lucas-Kanade算法通用化为参数运动模型,并与分层搜索算法结合使用[16、4、2]。
对于参数运动,我们使用一个由低维向量p参数化的空间变化运动场或对应图x'(x; p),而不是使用单个常数平移矢量u,其中x'可以是任何运动模型在第2节中介绍。现在,参数增量运动更新规则变为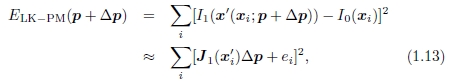
其中Jacobian现在是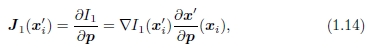
即图像梯度 与对应字段的雅可比矩阵的乘积Jx'=∂x'/∂p。
与对应字段的雅可比矩阵的乘积Jx'=∂x'/∂p。
计算雅可比行列式所需的导数可以直接从表1.1中得出,并在[28]中给出。
与平移情况相比,用于参量运动的Hessian和残差矢量的计算可能要昂贵得多。 对于具有n个参数和N个像素的参量运动,A和b的累加需要O(n2N)运算[2]。 减少此数量的一种方法是将图像分成较小的子块(块)Pj,并仅在像素级别[25、2、28]上累积更简单的2×2量(1.11)。
对于诸如单应性的复杂参量运动,运动雅可比行列式的计算变得复杂,并且可能涉及按像素划分。 Szeliski和Shum [30]观察到,可以通过首先根据当前运动估计x'(x; p)对目标图像I1进行变形,然后将该变形图像与模板I0(x)进行比较来简化此操作。 Baker和Matthews [2]将其称为正向合成算法,因为目标图像正在重新变形,并且最终运动估计值也正在合成,并且还提出了一种效率更高的逆合成算法。
3.2基于功能的注册
如前所述,直接匹配像素强度只是图像配准的一种可能方法。另一个主要方法是首先从每幅图像中提取独特的特征,匹配各个特征以建立全局对应关系,然后估计图像之间的几何变换。从立体声匹配的早期开始就使用这种方法,最近在图像拼接应用中也越来越流行[8,6]。
Schmid等人 [24]调查有关兴趣点检测的大量文献,并进行一些实验比较以确定特征检测器的可重复性。它们还测量每个检测到的特征点上可用的信息内容。在他们调查的技术中,他们发现Harris算子的改进版本效果最好。
最近,已经提出了尺度不变的特征检测器[15]和精细转换。当匹配具有不同比例或不同方面的图像时(例如,用于3D对象识别),这些功能非常有用。
在检测到特征(兴趣点)之后,我们必须对它们进行匹配,即确定哪些特征来自不同图像中的相应位置。 在某些情况下,例如,对于视频序列或已校正的立体声对,围绕每个特征点的局部运动可能大部分是平移的。 在这种情况下,先前介绍的误差度量可用于直接比较每个特征点周围小补丁中的强度。 (下面讨论的Mikolajczyk和Schmid [19]的比较研究使用互相关。)
如果在较长的图像序列上跟踪特征,则它们的外观可能会发生较大的变化。 在这种情况下,使用仿射运动模型比较外观是有意义的。 因为特征可以以不同的方向或比例出现,所以必须使用更多的视图不变类型的表示形式。 Mikolajczyk和Schmid [19]回顾了一些最近开发的视图不变的局部图像描述符,并通过实验比较了它们的性能。
补偿平面内旋转的最简单方法是在对补丁进行采样或以其他方式计算描述符之前,在每个特征点位置找到主导方向。 Mikolajczyk和Schmid使用平均梯度方向的方向,该方向是在每个特征点的较小邻域内计算的。 通过仅选择尺度空间中局部最大值的特征点,可使描述符按尺度不变。 在Mikolajczyk和Schmid比较的局部描述符中,David Lowe的尺度不变特征变换(SIFT)[15]表现最好。
查找图像对中所有相应特征点的最简单方法是使用一个上述本地描述符将一个图像中的所有特征与另一图像中的所有特征进行比较。 不幸的是,这在预期的功能数量上是二次的,这对于某些应用程序来说是不切实际的。 可以使用不同种类的索引方案来设计更有效的匹配算法,其中许多索引方案都基于在高维空间中找到最接近的邻居的想法。
一旦计算出一组初始的特征对应关系,我们需要找到一个将产生高精度对齐的集合。一种可能的方法是简单地计算最小二乘估计,或使用最小二乘的稳健版本。但是,在许多情况下,最好先找到一个良好的初始内联点集,即所有与某个特定运动估计一致的点。解决此问题的两种广泛使用的解决方案是随机抽样共识(RANSAC)和最小平方中位数(LMS)[26]。两种技术均始于选择k个对应关系的随机子集,然后将其用于计算运动估计p。然后,RANSAC技术计算在其预测位置的ε内的内部数目。最小二乘方中位数是 || ri || 的中位数价值观。重复随机选择过程S次,并保留具有最多内部数(或最小中位数残差)的样本集作为最终解决方案。
几何配准
一旦我们计算出一组匹配的特征点对应关系,我们仍然需要估计最能记录两个图像的运动参数p。通常的方法是使用最小二乘,即最小化由给出的残差平方和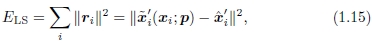
其中〜xi‘是估计的(映射的)位置,而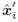 是与另一个图像中的点xi对应的感测(检测)特征点位置。
是与另一个图像中的点xi对应的感测(检测)特征点位置。
第2节介绍的许多运动模型,即平移,相似和仿射,在运动和未知参数p之间具有线性关系。 在这种情况下,使用正态方程的简单线性回归(最小二乘)效果很好。
上面的最小二乘公式假定所有特征点都以相同的精度匹配。 通常不是这种情况,因为某些点可能会落在比其他点更多的纹理区域中。 如果我们将方差估计值σi2与每个对应关系相关联,那么我们可以最小化加权最小二乘,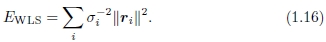
如[28]中讨论的,可以通过将Hessian的逆与每个像素的噪声估计值相乘来获得基于补丁的匹配的协方差估计值。 通过逆协方差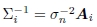 (称为信息矩阵)对每个平方残差进行加权,得到
(称为信息矩阵)对每个平方残差进行加权,得到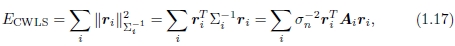
其中Ai是黑森州的补丁。
如果在基于特征的对应关系中存在离群值,则最好使用最小二乘的可靠版本,即使已使用初始RANSAC或MLS阶段来选择合理的离群值也是如此。 则鲁棒最小二乘法成本度量为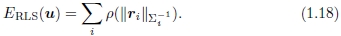
对于运动参数不是线性的运动模型,必须改用非线性最小二乘法。 一旦选择了合适的参数化,就可以推导相对于运动参数的每个残差方程的雅可比行列[28]。
3.3直接与基于功能
假设有这两种对齐图像的替代方法,哪个更可取?
我最初从事图像拼接的工作是在直接的(基于图像的)阵营中完成的[27,30,25]。早期基于特征的方法似乎在纹理过多或纹理不足的区域中感到困惑。这些特征通常会在图像上不均匀地分布,从而无法匹配应该对齐的图像对。此外,建立对应关系依赖于围绕特征点的面片之间的简单互相关,当图像旋转或由于单应性而缩短时,这种互相关不能很好地工作。
如今,特征检测和匹配方案非常健壮,甚至可以用于从广泛分离的视图中进行已知的对象识别[15]。因为它们在比例空间中操作并使用主导方向(或方向不变的描述符),所以它们可以匹配比例,方向甚至是透视缩短的图像。我自己最近的经验是,如果特征均匀地分布在图像上,并且为重复性合理设计了描述符,通常可以找到足以进行图像拼接的对应关系。
我以前喜欢直接方法的另一个主要原因是,它们可以最佳利用图像对齐中可用的信息,因为它们可以测量图像中每个像素的贡献。此外,假设是高斯噪声模型(或其稳健版本),它们可以适当地加权不同像素的贡献,例如,通过强调高梯度像素的贡献。 (见Baker等人[2],他们建议在强梯度上增加更多的权重是可取的,因为在梯度估计中会有噪声。)
直接技术的最大缺点是它们的收敛范围有限。即使采用分层(粗到细)技术也可以帮助实现,但是在重要细节开始变得模糊之前,很难使用两个或三个以上的金字塔等级。为了匹配视频中的顺序帧,通常可以使直接方法起作用。但是,为了匹配基于照片的全景图中的部分重叠的图像,它们经常失败而无用。
那时没有直接注册的角色吗?我相信有。一旦使用基于特征的方法对齐了一对图像,我们就可以将两个图像扭曲到一个公共参考系,并使用基于补丁的对齐方式重新计算出更准确的对应关系。请注意,基于补丁的直接对齐近似与反协方差加权特征最小二乘误差度量(1.17)之间存在紧密的对应关系。
实际上,如果我们将模板图像分成多个小块,并在每个小块的中心放置一个假想的“特征点”,则这两种方法将返回完全相同的答案(假设在每种情况下都找到正确的对应关系)。但是,要使此方法成功,我们仍然必须处理“异常值”,即由于视差或运动物体而无法适应所选运动模型的区域。虽然基于特征的方法可能更容易推断出异常值(可以将特征分类为异常值或离群值),但基于补丁的方法由于可以更加密集地建立对应关系,因此对于消除局部配准错误可能更有用(视差)。
4全球注册
到目前为止,我已经讨论了如何使用直接方法和基于特征的方法注册图像对。在大多数应用中,给我们提供的图像不止一对。目的是找到一组全局一致的对齐参数,以最大程度减少所有图像对之间的配准错误[30、25、23]。为了做到这一点,我们需要将成对匹配标准扩展到涉及所有基于图像的姿势参数的全局能量函数。计算完全局对齐后,我们需要执行局部调整,例如去除视差,以减少双重图像和由于局部配准错误而造成的模糊。最后,如果给我们提供了一组无序的图像进行配准,则需要发现哪些图像一起形成一个或多个全景图。
4.1捆绑包调整
注册大量图像的一种方法是一次向全景图中添加新图像,将最新图像与集合中已有的先前图像对齐[30],并在必要时发现其重叠的图像[ 23]。 对于360度全景图,累积的误差可能会导致全景图两端之间出现间隙(或过度重叠),可以通过使用称为间隙闭合[ 30]。 但是,更好的选择是使用最小二乘法框架将所有图像同时对齐,以均匀分布任何配准错误。
在摄影测量学领域中,同时为大量重叠图像同时调整姿态参数的过程在摄影测量学领域被称为捆绑调整[31]。在计算机视觉中,它首先从运动问题应用于一般结构[29],然后专门用于全景图像拼接[25,23]。
在本节中,我将使用基于特征的方法来阐述全局对齐的问题,因为这会导致系统更简单。通过将图像划分为小块并为每个图像创建虚拟特征对应关系,可以获得等效的直接方法[25]。
考虑(1.15)中给出的基于特征的对齐问题。 对于多图像对齐,我们没有n个特征的集合,而是仅具有成对特征对应关系{(xi,ˆxi')}的集合,其中第j个特征点在第j个图像中的位置由xij及其标量表示 由cij表示的置信度(逆方差)。 每个图像还具有一些关联的姿势参数。
在本节中,我假设此姿势由旋转矩阵Rj和焦距fj组成,尽管也可以根据单应性进行公式化[30,23]。 可以从(1.4–1.6)重写将3D点xi映射到帧j 中的点xij的等式为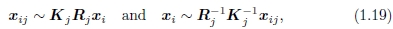
其中Kj = diag(fj,fj,1)是校准矩阵的简化形式。 类似地,将帧j的点xij映射到帧k中的点xik的运动由下式给出: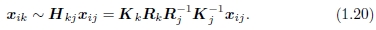
给定从成对的成对比对获得的{{Rj,fj)}估计值的初始集合,我们如何优化这些估计值?
一种方法是将成对能量直接扩展为多视图公式,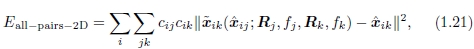
其中〜xik函数是特征i在由(1.20)给出的帧k中的预测位置,, xij是观察到的位置,下标中的“ 2D”表示图像平面误差正在被最小化。
尽管此方法在实践中效果很好,但存在两个潜在的缺点。 首先,由于对具有相应特征的所有对进行求和,因此多次观察到的特征在最终解决方案中会变得过重。 第二,〜xik w.r.t.的导数。 {(Rj,fj)}有点麻烦。
制定优化方案的另一种方法是使用真正的包调整,即,不仅要求解姿态参数{(Rj,fj)},还要求解3D点位置{xi},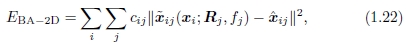
其中〜xij(xi; Rj,fj)由(1.19)给出。 完全束调整的缺点是要解决的变量更多,因此每次迭代和整体收敛都可能较慢。 但是,可以使用稀疏矩阵技术来降低每个线性高斯-牛顿步的计算复杂度[29、25、31]。
另一种替代方法是使3D投影射线方向的误差最小化[25],即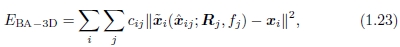
其中〜xij(xi; Rj,fj)由(1.19)的后一半给出。
但是,如果我们消除3D射线xi,则可以导出在3D射线空间中公式化的成对能量[25],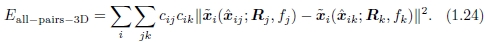
这导致更新方程组最简单[25],因为可以将fk折叠到齐次坐标向量的创建中。 因此,即使该公式对出现频率较高的特征进行了加权,它还是Shum和Szeliski [25]以及我当前基于特征的对齐器中使用的方法。 为了减少对更长焦距的偏见,我将每个残差(3D误差)乘以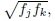 ,这类似于将3D射线投射到中等焦距的“虚拟相机”中。
,这类似于将3D射线投射到中等焦距的“虚拟相机”中。
4.2视差消除
一旦我们估计了相机的整体方向和焦距,我们可能会发现图像仍未完全对准,即,合成的缝合图像在某些地方看起来模糊或重影。 这可能是由多种因素引起的,包括未建模的径向畸变,3D视差(无法使相机绕其光学中心旋转),较小的场景运动(例如,挥舞着树枝)和大规模的场景运动(例如,人们进入和移动)。 没有图片。
这些问题中的每一个都可以用不同的方法来处理。可以使用几种经典的校准技术之一来估计径向变形。可以通过进行完整的3D捆绑调整来攻击3D视差。匹配的特征点和摄像机的3D位置可以同时恢复,尽管与无视差的图像配准相比,这可能会贵得多。
当场景中的运动非常大时,即当物体完全消失时,明智的解决方案是一次仅从一张图像中选择像素作为最终合成图像的来源[10,1],如 第6节。但是,当运动相当小(几个像素的数量级)时,可以使用称为局部对齐的过程在混合之前使用常规的二维运动估计(光学流)执行适当的校正[25]。 。 尽管此过程使用的运动模型比显式地建模误差源的模型要弱,但该过程也可以用于补偿径向变形和3D视差,因此可能会更频繁地失败。
4.3识别全景
完成全自动图像拼接所需的最后一块是一种确定哪些图像实际组合在一起的技术,Brown和Lowe称之为识别全景图[6]。如果用户按顺序拍摄图像,以使每个图像都与其前身重叠,则可以使用捆绑调整与拓扑推断过程结合起来自动组装全景图[23]。但是,用户在拍摄全景图时经常会四处走动,例如,他们可能在上一个全景图的顶部开始新的一行,或者跳回以进行重复拍摄,或者创建360°全景图,其中需要发现端到端的重叠。此外,自动发现用户拍摄的多个全景图的能力可能会带来很大的便利。

图2.一组图像和在其中发现的全景图
为了识别全景图,Brown和Lowe [6]首先使用基于特征的方法找到所有成对的图像重叠,然后在重叠图中找到相连的分量以“识别”单个全景图(图2)。 首先,他们使用Lowe的尺度不变特征变换(SIFT特征)[15],然后进行最近邻居匹配。 然后,使用配对对来假设相似性运动估计,然后使用RANSAC查找一组内线。 一旦计算出成对对齐,就使用全局配准(捆绑调整)阶段为所有图像计算全局一致的对齐。 最后,使用两级拉普拉斯金字塔无缝融合图像[6]。
5选择复合曲面
一旦我们将所有输入图像相互注册,我们就需要决定如何产生最终的拼接(马赛克)图像。这涉及选择最终的复合表面,例如平坦,圆柱形或球形。它也可能涉及计算最佳参考视图,以确保场景看起来是直立的,如[28]中所述。
如果仅将几幅图像缝合在一起,那么自然的方法是选择其中一幅图像作为参考,然后将所有其他图像扭曲到参考坐标系中。 最终的合成物称为平面全景图,因为到最终表面的投影仍然是透视投影,因此直线保持笔直。
但是,对于较大的视野,我们不能在不过度拉伸图像边界附近的像素的情况下保持平面表示。 (实际上,一旦视野超过90º左右,平坦的全景图就会开始出现严重失真。)合成较大全景图的通常选择是使用圆柱[9]或球形[30]投影。实际上,可以使用在计算机图形学中用于环境映射的任何表面,包括一个立方体图,该立方体图表示具有框的六个正方形面的完整查看范围[30]。
参数化的选择在某种程度上取决于应用程序,并且涉及在保持局部外观不失真(例如,使直线保持直线)与提供合理均匀的环境采样之间的权衡。根据全景图的范围自动进行选择并在制图表达之间平滑过渡是未来研究的有趣话题。
6 接缝选择和像素融合
将源像素映射到最终的合成表面后,我们必须决定如何混合它们以创建美观的全景图。如果所有图像均已完美配准并完全曝光,这将是一个简单的问题(任何像素组合都可以)。但是,对于真实图像,可能会出现可见的接缝(由于曝光差异),模糊(由于配准错误)或重影(由于移动的物体)。
创建干净,令人愉悦的全景图既需要决定使用哪些像素,又要如何加权或融合它们。这两个阶段之间的区别很小,因为每个像素的加权可能是选择和混合的结合。在本节中,我将讨论空间变化的权重,像素选择(接缝放置),然后是更复杂的混合。
羽化和中央重点

图3.通过多种算法计算的最终复合材料:(a)平均值,(b)羽化平均值,(c)带有羽化的加权ROD顶点覆盖,(d)具有泊松混合的图样接缝。 请注意,规则平均线如何在图像边缘附近切断移动的人,而羽状平均线则将它们缓慢融合。顶点覆盖和图割算法产生相似的结果。
创建最终合成图像的最简单方法是简单地对每个像素取一个平均值。但是,由于曝光差异,配准错误和场景移动都非常明显,因此这通常效果不佳(图3a)。如果快速移动的物体是唯一的问题,则通常可以使用中值滤波(这是一种像素选择运算符)将其移除[12]。
更好的方法是对图像中心附近的像素进行更重的加权,而对边缘附近的像素进行权重降低。当图像具有一些剪切区域时,最好对剪切边缘和边缘的边缘均进行加权。 这可以通过计算距离图或草火变换来完成,其中,每个有效像素都用其到最近无效像素的欧几里德距离来标记。 距离图的加权平均通常被称为羽化[30,32],并且可以很好地融合曝光差异。 但是,模糊和重影仍然是问题(图3b)。
一种改善羽化的方法是将距离贴图值提高一些。加权平均值随即成为较大值的主导,即,它们的作用像p范数。所得的复合材料通常可以在可见的曝光差异和模糊之间提供合理的平衡。
在极限p→∞中,仅选择具有最大距离值的像素,这等效于计算Vornoi图。 所得的合成物虽然可用于艺术指导和在高重叠全景照片(歧管马赛克)中使用,但当曝光变化时,往往具有非常硬的边缘和明显的接缝。
最佳接缝选择
计算Vornoi图是在不同图像有助于最终合成的区域之间选择接缝的一种方法。 但是,Vornoi图像完全忽略了接缝下面的局部图像结构。
更好的方法是将接缝放置在图像一致的区域,以使从一个光源到另一个光源的过渡不可见。 通过这种方式,该算法避免了“切穿”运动对象,在运动对象中接缝看起来不自然[10]。 对于一对图像,此过程可以表述为一个简单的动态程序,该程序从重叠区域的一个边缘开始,在另一个区域结束[20,10]。 不幸的是,当合成多幅图像时,动态程序的思想并不能一概而论。
为了克服这个问题,Uyttendaele等人 [32]观察到,对于配准良好的图像,运动的物体会产生最明显的伪像,即半透明的鬼影。因此,他们的系统决定保留哪些对象以及删除哪些对象。首先,该算法比较所有重叠的输入图像对,以确定图像不一致的差异区域(ROD)。接下来,用ROD作为顶点构造图,并表示代表最终复合中重叠的ROD对的边。由于边缘的存在指示存在分歧的区域,因此必须从最终复合材料中移除顶点(区域),直到没有边缘跨越一对未移除的顶点为止。可以使用顶点覆盖算法来计算最小的此类集合。由于可能存在多个这样的覆盖,因此可以使用加权的顶点覆盖,而顶点权重是通过将ROD中的羽毛权重求和来计算的。因此,该算法更喜欢删除图像边缘附近的区域,这样可以减少部分可见的对象出现在最终合成图像中的可能性。一旦去除了所需的差异区域,就可以使用羽毛状的混合物创建最终的复合材料(图3c)。
Agarwala等人[1]最近提出了一种不同的像素选择和接缝放置方法。 他们的系统计算标签分配,以优化两个目标函数之和。 首先是每像素图像物镜CD,它确定哪些像素可能产生良好的合成效果。 在他们的系统中,用户可以通过“绘制”具有所需对象或外观的图像来选择要使用的像素。 替代地,可以使用自动选择标准,例如,偏好重复出现的像素的最大可能性(用于对象移除),或不频繁出现的对象的最小可能性(用于最大的对象保留)。
第二项是接缝物镜CS,它会惩罚相邻图像之间的标签差异。 例如,在[1]中使用的基于简单颜色的接缝惩罚可测量接缝两侧相应像素之间的色差。 可以使用多种技术来最小化作为数据和煤层成本之和的全球能源函数[28]。 Agarwala等人 [1]使用图割,它涉及循环通过一组更简单的α扩展重标记,每个标记都可以用图割(最大流)多项式时间算法[5]求解。
对于图3d所示的结果,Agarwala等人 [1]对无效像素使用较大的数据损失,对有效像素使用0。请注意,接缝放置算法如何避免出现差异区域,包括那些与图像接壤的区域,并可能导致物体被切掉。图割[1]和顶点覆盖[32]通常会产生相似的结果,尽管前者的速度明显慢,因为它可以优化所有像素,而后者对用于确定差异区域的阈值更为敏感。
拉普拉斯金字塔融合
放置接缝并清除不需要的物体后,我们仍然需要混合图像以补偿曝光差异和其他未对准情况。Burt和Adelson提出了一个有吸引力的解决方案[7]。代替使用单个过渡宽度,而是通过创建带通(拉普拉斯)金字塔并将过渡宽度作为金字塔等级的函数来使用频率自适应宽度。首先,将每个变形的图像转换为带通(拉普拉斯)金字塔。接下来,将与每个源图像关联的蒙版转换为低通(高斯)金字塔,并用于执行带通图像的每层羽化混合。最后,通过对所有金字塔等级(带通图像)进行插值和求和来重建合成图像。
渐变域融合
多频带图像融合的另一种方法是在梯度域中执行操作。这里,不是使用初始颜色值,而是复制每个源图像的图像梯度;在第二遍中,重建与这些梯度最匹配的图像[1]。接缝放置后直接从源图像复制渐变只是渐变域融合的一种方法。Levin等人 [14]研究了这种方法的几种不同的变体,他们称之为梯度域图像拼接(GIST)。他们研究的技术包括对源图像中的梯度进行羽化(混合),以及使用L1范数从梯度场中重建图像,而不是使用L2范数。他们的首选技术是对原始图像渐变(它们称为GIST1-l1 )进行羽化(混合)成本函数的L1优化。尽管使用线性规划的L1优化可能很慢,但在多网格框架中更快的基于中值的迭代算法在实践中效果很好。他们的首选方法与所谓的最佳接缝(与Agarwala等人的方法[1]等效)之间的视觉比较显示了相似的结果,同时在金字塔混合和羽化算法上有显着改进。
曝光补偿
金字塔和梯度域混合可以很好地补偿图像之间适度的曝光差异。但是,当曝光差异变大时,可能需要其他方法。
Uyttendaele等人 [32]迭代估计每个源图像和混合合成图像之间的局部校正。首先,在每个源图像和初始羽化合成图像之间拟合一个基于块的二次传递函数。接下来,将传递函数与其邻居平均,以获得更平滑的映射,并通过在相邻块值之间进行样条化来计算每个像素的传递函数。一旦对每个源图像进行了平滑调整,就可以计算出新的羽化合成,然后重复该过程(通常3次)。文献[32]中的结果表明,与简单的羽化相比,这可以更好地进行曝光补偿,并且可以处理由于镜头渐晕等效应而导致的局部曝光变化。
高动态范围成像
一种更原则的方法是根据不同曝光的图像估计单个高动态范围(HDR)辐射度图[11,21]。 该方法假定输入图像是使用固定相机拍摄的,其像素值是将参数化的辐射传递函数f(R,p)应用于缩放后的辐射值ckR(x)的结果。 曝光值ck是已知的(通过实验设置或通过相机的EXIF标签),或作为参数估算过程的一部分进行计算。 在估计了传递函数之后,可以组合来自不同曝光的辐射值以强调可靠的像素。
计算出辐射度图后,通常需要将其显示在较低色域(即8位)的屏幕或打印机上。为此已经开发了多种色调映射技术,包括计算空间变化的传递函数或减小图像梯度以适应可用的动态范围。
不幸的是,大多数随便获取的图像可能无法完美配准,并且可能包含运动物体。Kang等人 [13]提出了一种将全局配准与局部运动估计(光流)相结合的算法,以在混合其辐射率估计之前精确对准图像。由于图像可能会有不同的曝光,因此在生成运动估计时必须格外小心,必须自己检查其一致性,以避免产生重影和物体碎片。
7 扩展和未解决的问题
虽然图像拼接现在已经达到了在消费者照片编辑产品中普遍使用的水平,但是仍然存在许多尚待解决的开放研究问题。
首先,这将提高全自动缝合的可靠性。每当图像由于运动的物体而包含少量的重叠,重复的纹理或较大的差异区域时,就很难在意外对齐和正确对齐之间进行歧义消除。有关兼容的一组对应关系的全局推理可能是解决方案,而健壮(部分)特征匹配的改进可能也可以。
处理运动和视差是另一个重要领域,因为通常在高度动态的情况下使用手持相机拍摄照片。在某个时候,可能需要使用移动物体检测和层提取进行完整的3D重建,这在设计快速简便的用户界面以指定所需的最终输出时也引起了有趣的问题。
处理不同分辨率和缩放系数的图像是另一个有趣的领域,尤其是因为可变分辨率的图像表示形式和查看者并不常见。一个相关的问题是超分辨率,即通过组合相同区域的抖动照片来增强图像分辨率[17,8]。不幸的是,由于光学和运动估计的限制,在实践中似乎只能实现非常有限的改进(<2倍)。
随着更多的数码相机开始包含视频拍摄功能,拼接视频是另一个可能增长的领域。拼接视频以获得摘要全景图的示例已经存在了一段时间[12,22]。将来,我们可能会看到“实时”全景图的构建,其中包括运动元素以及静止部分[27]。
最终,图像对齐和拼接将成为计算机视觉算法的一部分,该算法可用于合并多张图像(具有不同的方向,曝光和其他属性),以创建增强的创新合成图像和摄影体验。
8 参考文献
[1] A. Agarwala et al. Interactive digital photomontage. ACM Transactions on Graphics, 23(3):292–300, August 2004.
[2] S. Baker and I. Matthews. Lucas-kanade 20 years on: A unifying framework: Part 1: The quantity approximated, the warp update rule, and the gradient descent approximation. International Journal of Computer Vision, 56(3):221–255, March 2004.
[3] R. Benosman and S. B. Kang, editors. Panoramic Vision: Sensors, Theory, and Applications, New York, 2001. Springer.
[4] J. R. Bergen, P. Anandan, K. J. Hanna, and R. Hingorani. Hierarchical model-based motion estimation. In Second European Conference on Computer Vision, pages 237–252, Santa Margherita Liguere, Italy, May 1992. Springer-Verlag.
[5] Y. Boykov, O. Veksler, and R. Zabih. Fast approximate energy minimization via graph cuts. IEEE Transactions on Pattern Analysis and Machine Intelligence, 23(11):1222–1239, November 2001.
[6] M. Brown and D. Lowe. Recognizing panoramas. In Ninth International Conference on Computer Vision, pages 1218–1225,Nice, France, October 2003.
[7] P. J. Burt and E. H. Adelson. A multiresolution spline with applications to image mosaics. ACM Transactions on Graphics, 2(4):217–236, October 1983.
[8] D. Capel and A. Zisserman. Automated mosaicing with superresolution zoom. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 885–891, Santa Barbara, June 1998.
[9] S. E. Chen. QuickTime VR – an image-based approach to virtual environment navigation. Computer Graphics (SIGGRAPH’95), pages 29–38, August 1995.
[10] J. Davis. Mosaics of scenes with moving objects. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition, pages 354–360, Santa Barbara, June 1998.
[11] P. E. Debevec and J. Malik. Recovering high dynamic range radiance maps from photographs. Proceedings of SIGGRAPH 97, pages 369–378, August 1997.
[12] M. Irani and P. Anandan. Video indexing based on mosaic representations. Proceedings of the IEEE, 86(5):905–921, May 1998.
[13] S. B. Kang et al. High dynamic range video. ACM Transactions on Graphics, 22(3):319–325, July 2003.
[14] A. Levin, A. Zomet, S. Peleg, and Y. Weiss. Seamless image stitching in the gradient domain. In Eighth European Conference on Computer Vision, volume IV, pages 377–389, Prague, May 2004.
[15] D. G. Lowe. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 60(2):91–110, November 2004.
[16] B. D. Lucas and T. Kanade. An iterative image registration technique with an application in stereo vision. In Seventh International Joint Conference on Artificial Intelligence, pages 674–679, Vancouver, 1981.
[17] S. Mann and R.W. Picard. Virtual bellows: Constructing high-quality images from video. In First IEEE International Conference on Image Processing, volume I, pages 363–367, Austin, November 1994.
[18] J. Meehan. Panoramic Photography. Watson-Guptill, 1990.
[19] K. Mikolajczyk and C. Schmid. A performance evaluation of local descriptors. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition, volume II, pages 257–263,Madison,WI, June 2003.
[20] D. L. Milgram. Computer methods for creating photomosaics. IEEE Transactions on Computers, C-24(11):1113–1119, November 1975.
[21] T. Mitsunaga and S. K. Nayar. Radiometric self calibration. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition, volume 1, pages 374–380, Fort Collins, June 1999.
[22] H. S. Sawhney et al. Video Experiences with consumer video mosaicing. In IEEE Workshop on Applications of Computer Vision, pages 56–62, Princeton, October 1998.
[23] H. S. Sawhney and R. Kumar. True multi-image alignment and its application to mosaicing and lens distortion correction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 21(3):235–243, March 1999.
[24] C. Schmid, R. Mohr, and C. Bauckhage. Evaluation of interest point detectors. International Journal of Computer Vision, 37(2):151–172, June 2000.
[25] H.-Y. Shum and R. Szeliski. Construction of panoramic mosaics with global and local alignment. International Journal of Computer Vision, 36(2):101–130, February 2000. Erratum published July 2002, 48(2):151-152.
[26] C. V. Stewart. Robust parameter estimation in computer vision. SIAM Reviews, 41(3):513–537, September 1999.
[27] R. Szeliski. Video mosaics for virtual environments. IEEE Computer Graphics and Applications, 16(2):22–30, March 1996.
[28] R. Szeliski. Image alignment and stitching: A tutorial. Technical Report MSR-TR-2004-92, Microsoft Research, December 2004.
[29] R. Szeliski and S. B. Kang. Recovering 3D shape and motion from image streams using nonlinear least squares. Journal of Visual Communication and Image Representation, 5(1):10–28, March 1994.
[30] R. Szeliski and H.-Y. Shum. Creating full view panoramic image mosaics and texture-mapped models. Computer Graphics (SIGGRAPH’97 Proceedings), pages 251–258, August 1997.
[31] B. Triggs et al. Bundle adjustment — a modern synthesis. In International Workshop on Vision Algorithms, pages 298–372, Kerkyra, Greece, September 1999.
[32] M. Uyttendaele, A. Eden, and R. Szeliski. Eliminating ghosting and exposure artifacts in image mosaics. In IEEE Computer Society Conference on Computer Vision and Pattern Recognition, volume II, pages 509–516, Kauai, Hawaii, December 2001.