常见的二分类评估指标都已耳熟不能详,现在来了解一下多分类的评估。
你是否愿闻其详?

Reference webs:
https://www.pythonf.cn/read/124960
https://zhuanlan.zhihu.com/p/59862986
https://toutiao.io/posts/gorhvh/preview
https://www.zhihu.com/question/51470349
1 不加sample_weight
1.1 micro
micro算法是指把所有的类放在一起算,具体到precision,就是把所有类的TP加和,再除以所有类的TP和FN的加和。因此micro方法下的precision和recall都等于accuracy。

使用sklearn计算的结果也是一样:
from sklearn.metrics import precision_score
precision_score(y_true, y_pred, average="micro")
1.2 macro
macro方法就是先分别求出每个类的precision再算术平均。

precision_score(y_true, y_pred, average="macro")
1.3 weighted
前面提到的macro算法是取算术平均,weighted算法就是在macro算法的改良版,不再是取算术平均、乘以固定weight(也就是1/3)了,而是乘以该类在总样本数中的占比。计算一下每个类的占比:
w_neg1, w_0, w_pos1 = np.bincount(y_true+1) / len(y_true)
print(w_neg1, w_0, w_pos1)
然后手算一下weighted方法下的precision:

用sklearn验证一下:
precision_score(y_true, y_pred, average="weighted")
2 加入sample weight
当样本不均衡时,比如本文举出的样本,中间的0占80%,1和-1各占10%,每个类数量差距很大,我们可以选择加入sample_weight来调整我们的样本。
混淆矩阵和评估指标
PRF值分别表示准确率(Precision)、召回率(Recall)和F1值(F1-score)
我们之前评价二分类的时候有混淆矩阵,AUC等评估指标。 在多分类中我们同样有这些指标,只不过计算方式略有不同。 就如混淆矩阵。如有150个样本数据,这些数据分成3类,每类50个。分类结束后得到的混淆矩阵为:

2.多分类[1]Macro F1: 将n分类的评价拆成n个二分类的评价,计算每个二分类的F1 score,n个F1 score的平均值即为Macro F1。Micro F1: 将n分类的评价拆成n个二分类的评价,将n个二分类评价的TP、FP、RN对应相加,计算评价准确率和召回率,由这2个准确率和召回率计算的F1 score即为Micro F1。一般来讲,Macro F1、Micro F1高的分类效果好。Macro F1受样本数量少的类别影响大。
作者:谢为之
链接:https://www.zhihu.com/question/51470349/answer/439218035
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
用from sklearn.metrics import precision_score,recall_scoreprint (precision_score(y_true, y_scores,average='micro'))其中average是参数,不同参数适用不同任务,比如二分类,多分类,多标签
作者:Dhealth
链接:https://www.zhihu.com/question/51470349/answer/328489878
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
https://blog.csdn.net/wf592523813/article/details/95202448
2.1 多分类转化为2vs2问题来评价
准确率:与二分类相同,预测正确的样本占总样本的比例。
精确率: ‘macro’, 对于每个标签,分别计算Precision,然后取不加权平均
查全率: ‘macro’,对于每个标签,分别计算Recall,然后取不加权平均
F1-Score:‘macro’, 对于每个标签,分别计算发,然后取不加权平均
‘micro’, 将n个二分类评价的TP,FP,FN对应相加,计算P和R,然后求得F1
一般macro-f1和micro-f1都高的分类器性能好
2.2 直接定义的多分类指标
2.2.1Kappa系数
kappa系数是用在统计学中评估一致性的一种方法,取值范围是[-1,1],实际应用中,一般是[0,1],与ROC曲线中一般不会出现下凸形曲线的原理类似。这个系数的值越高,则代表模型实现的分类准确度越高。
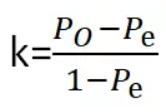
P0表示总体分类精度
Pe表示SUM(第i类真实样本数*第i类预测出来的样本数)/样本总数平方

2.2.2. 海明距离
海明距离也适用于多分类的问题,简单来说就是衡量预测标签与真实标签之间的距离,取值在0~1之间。距离为0说明预测结果与真实结果完全相同,距离为1就说明模型与我们想要的结果完全就是背道而驰。
from sklearn.metrics import hamming_loss
ham_distance = hamming_loss(y_true,y_pred)
from sklearn.metrics import cohen_kappa_score
kappa = cohen_kappa_score(y_true,y_pred,label=None) #(label除非是你想计算其中的分类子集的kappa系数,否则不需要设置)
2.2.3.杰卡德相似系数
它与海明距离的不同之处在于分母。当预测结果与实际情况完全相符时,系数为1;当预测结果与实际情况完全不符时,系数为0;当预测结果是实际情况的真子集或真超集时,距离介于0到1之间。
我们可以通过对所有样本的预测情况求平均得到算法在测试集上的总体表现情况。
from sklearn.metrics import jaccard_similarity_score
jaccrd_score = jaccrd_similarity_score(y_true,y_pred,normalize = default)
normalize默认为true,这是计算的是多个类别的相似系数的平均值,normalize = false时分别计算各个类别的相似系数
2.2.4.铰链损失
铰链损失(Hinge loss)一般用来使“边缘最大化”(maximal margin)。损失取值在0~1之间,当取值为0,表示多分类模型分类完全准确,取值为1表明完全不起作用。
from sklearn.metrics import hinge_loss
hinger = hinger_loss(y_true,y_pred)