实验内容:
爬取斗鱼视频某一板块的内容
采集字段:房间名、主播名、分类信息、热度
流程图:
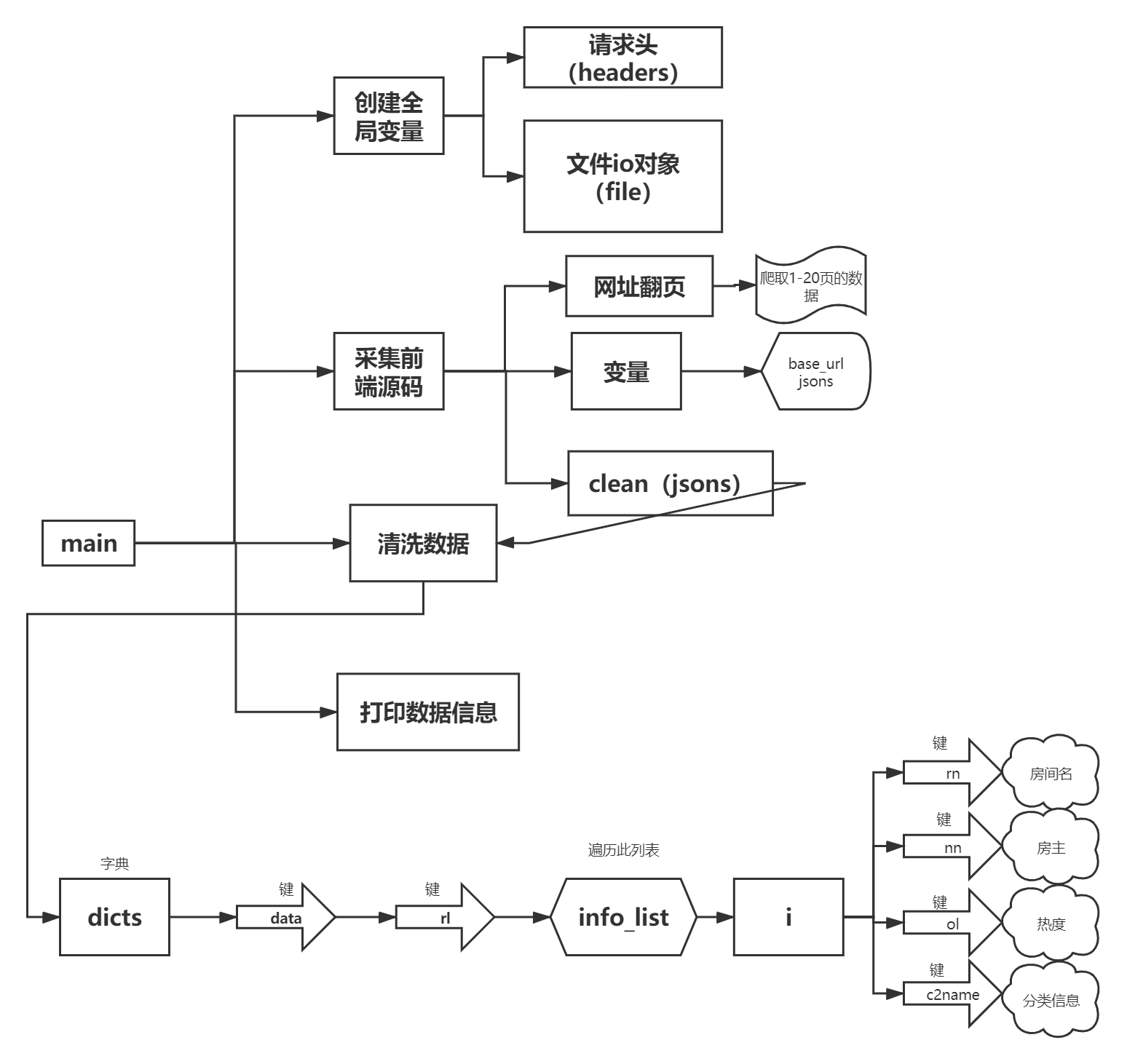
源码:


1 import requests 2 from lxml import etree 3 from urllib import request 4 import json 5 6 # 全局变量(请求头+文件io对象) 7 headers = { 8 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36 Edg/85.0.564.44'} 9 file = open('./斗鱼.txt', 'w', encoding='utf-8') 10 11 12 # 采集前端源码 13 def index(): 14 for num in range(1, 21): 15 base_url = 'https://www.douyu.com/gapi/rkc/directory/mixList/2_181/{}'.format(num) # 翻页 16 print('正在写入', base_url, '中的数据信息...') 17 response = requests.get(base_url, headers=headers) 18 response.encoding = 'uft-8' # 解码 19 jsons = response.text 20 # print(type(jsons))#jsons的数据类型是str 21 clean(jsons) # 清洗数据函数 22 23 24 # 清洗数据 25 def clean(jsons): 26 dicts = json.loads(jsons) # 将jsons的数据类型由字符型转换成字典型 27 # print(dicts) 28 info_list = dicts['data']['rl'] # 提取主要信息 29 printt(info_list) 30 31 32 # 打印数据信息 33 def printt(info_list): 34 for i in info_list: 35 room_number = i['rn'] 36 # print(room_number) 37 homeowner = i['nn'] 38 # print(homeowner) 39 heat = i['ol'] 40 # print(heat) 41 C2name = i['c2name'] 42 # 整合数据信息 43 full_info = C2name + '房间号:' + room_number + ' ' + '房主:' + homeowner + ' ' + '热度:' + str(heat) 44 # 写入文件 45 file.write(full_info + ' ') 46 47 48 if __name__ == '__main__': 49 index() 50 file.close()
实验过程中的部分截图:
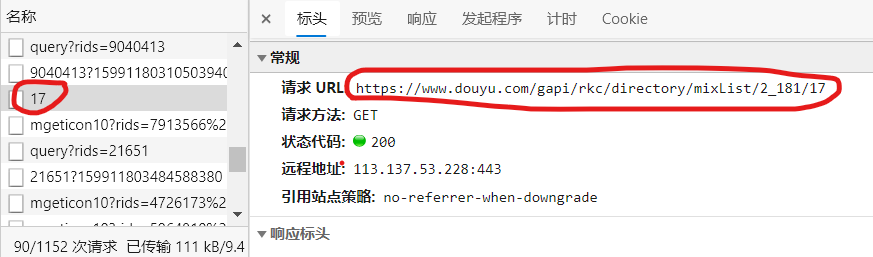

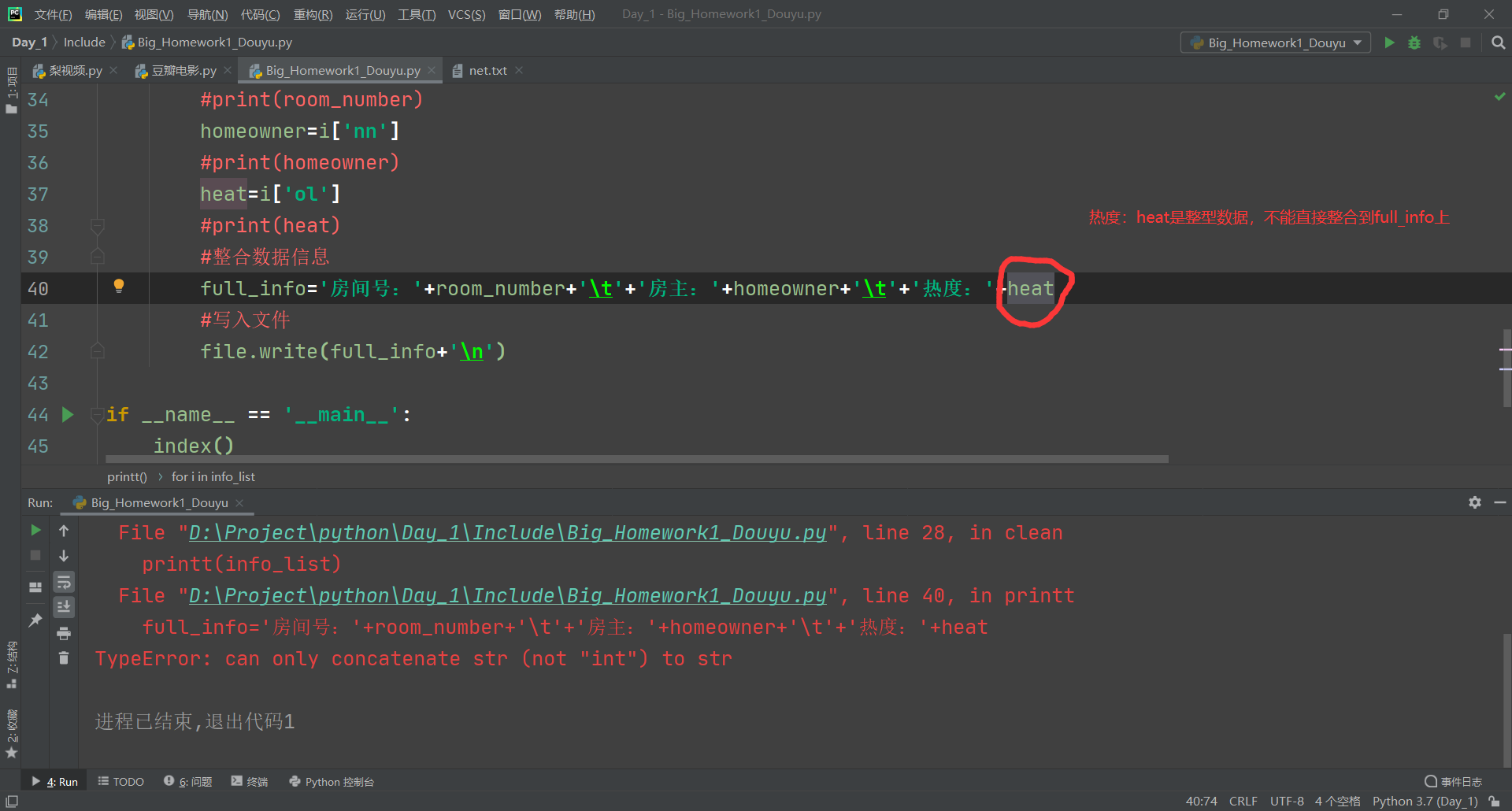

实验心得:
脑子里回忆着今天上午所学的内容,指下却一刻都没停过,找可供翻页的网址,解码,转换,清洗提取信息,整合成自己所乐意看到的信息样式,看到最后run出来的斗鱼.txt文档,真的是满满的成就感。虽然连着搞了2个小时左右叭,却毫无疲惫之意,开心编程莫过于此!