- RabbitMQ就是消息队列(Message Queue)
- 在Python中使用pika库和RabbitMQ相连,再通过RabbitMQ查看队列和消息
- RabbitMQ消息发送采用轮询方式,即一个接收完再到下一个接收,最后回到第一个consumer,依次循环
一、简单生产者和消费者实现
1、生产者
import pika #RabbitMQ 采用轮询方式 connection=pika.BlockingConnection(pika.ConnectionParameters('localhost'))#建立连接 channel=connection.channel()#声明一个管道 channel.queue_declare(queue='hello')#声明一个队列并命名 channel.basic_publish(exchange='', routing_key='hello',#队列名 body='hello there~', ) )#发送的消息 print('send message...') connection.close()
首先使用pika库建立连接,声明一个管道,再声明一个队列,发送消息,最后关闭连接
2、消费者
import pika connection=pika.BlockingConnectison(pika.ConnectionParameters('localhost',5672))#RabbitMQ默认端口 channel=connection.channel() channel.queue_declare(queue='hello',durable=True)#队列名,和produser的一致 def callback(ch,method,propotities,body): print("receive >>",body) ch.basic_ack(delivery_tag=method.delivery_tag)#no_ack=False的话要手动确认 channel.basic_consume(callback,#如果收到消息就调用回调函数 queue='hello', # no_ack=True ) print(' [*] Waiting for messages. To exit press CTRL+C') channel.start_consuming()#是channel开始不是connection开始,不用关闭连接
二、RabbitMQ交换模式
RabbitMQ交换模式有fanout、direct和topic
注:三种交换模式中信息的发送都是即时的,即错过了消息就接收不到了
1、fanout广播
- fanout即广播模式,也是发布订阅
publisher实现
- fanout模式中publisher和一般publisher差不多,但不需要声明queue即routing_key为空,但要指明exchange_type


import pika #不需要声明queue,广播是实时的即订阅发布 connection=pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel=connection.channel() channel.exchange_declare(exchange='logs',exchange_type='fanout') message='message...' channel.basic_publish(exchange='logs', routing_key='', body=message) print('send...') connection.close()
consumer实现
- consumer中也不需要指明queue名,rabbitmq会随机分配,但要进行对分配的queue绑定的动作
- consumer中的exchange_type要与publisher中的一致,否则接收不到消息
- consumer可以接收publisher广播的任何消息
import pika #发送端和接收端均不用声明queue connection=pika.BlockingConnection(pika.ConnectionParameters('localhost')) channel=connection.channel() channel.exchange_declare(exchange='logs', exchange_type='fanout') result=channel.queue_declare(exclusive=True) #不指定queue名字,rabbitmq会随机指定queue,exclusive=True会在消息接收完后删除 queue_name=result.method.queue def callback(ch,method,properties,body): print('receive>>',body) channel.queue_bind(exchange='logs',queue=queue_name)#绑定queue channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
2、direct过滤特定消息
- direct模式可以进行简单过滤,客户端可以选择接收什么类型的消息,如info、warning、error等
publisher实现
- direct模式与fanout不同的是direct中routing_key是必须的,即消息的级别
- direct中要定义消息级别(通过命令行实现不同消息级别的定义),默认级别为info
- 生产者消费者exchange名字要一致
import pika,sys #不需要声明queue,广播是实时的即订阅发布 connection=pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel=connection.channel() channel.exchange_declare(exchange='direct_logs',exchange_type='direct') severity=sys.argv[1] if len(sys.argv)>1 else 'info'#定义消息级别,默认为info #sys.argv为获取命令行参数 message=''.join(sys.argv[2:])or 'HELLO!'#获取消息 channel.basic_publish(exchange='direct_logs',#exchange名字可以随便起,但消费端exchange名字一定要和生产端一致,否则收不到消息!!! routing_key=severity,#direct模式中routing_key是必须的,生成和消费端都是 body=message) print('send...') connection.close()
consumer实现
- 消费者要在命令行模式下指明接收的消息级别(可以接收多个级别的消息),否则会报错
- 指明routing_key即消息级别
#direct可以实现接收特定消息或指定消息 import pika,sys #发送端和接收端均不用声明queue connection=pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel=connection.channel() channel.exchange_declare(exchange='direct_logs', exchange_type='direct') result=channel.queue_declare(exclusive=True) queue_name=result.method.queue #定义级别,不指定级别会报错 severities=sys.argv[1:] if not severities: sys.stderr.write('Usage:%s [info] [warning] [error]'%sys.argv[0]) sys.exit(1) for s in severities: channel.queue_bind(exchange='direct_logs', queue=queue_name,routing_key=s) # 绑定queue,要指定routing_key!! def callback(ch,method,properties,body): print('receive>>',body) channel.basic_consume(callback, queue=queue_name, #no_ack=True ) channel.start_consuming()
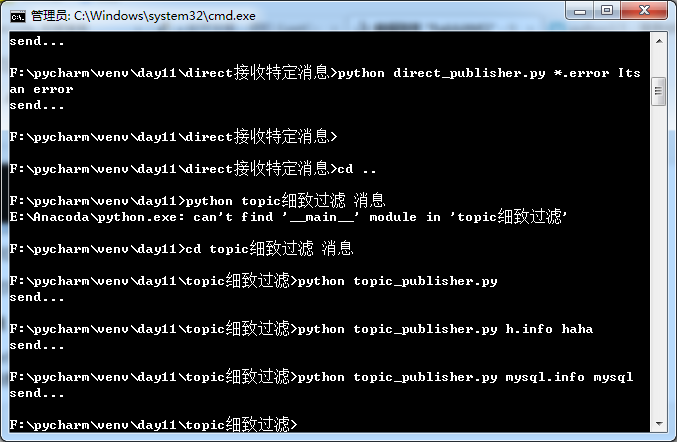
3、topic细致的过滤
- topic模式可以实现接收不同应用程序的所有消息,如MySQL.info,*.info等
publisher实现
- publisher只需要在direct的基础上更改exchange和exchange_type
- 将默认消息级别改为'anonymous.info'
import pika,sys #不需要声明queue,广播是实时的即订阅发布 connection=pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel=connection.channel() channel.exchange_declare(exchange='topic_logs',exchange_type='topic') severity=sys.argv[1] if len(sys.argv)>1 else 'anonymous.info'#定义消息级别,默认为info #sys.argv为获取命令行参数 message=''.join(sys.argv[2:])or 'HELLO!'#获取消息 channel.basic_publish(exchange='topic_logs',#exchange名字可以随便起,但消费端exchange名字一定要和生产端一致,否则收不到消息!!! routing_key=severity,#direct模式中routing_key是必须的,生成和消费端都是 body=message) print('send...') connection.close()
consumer实现
- 消费端接收的消息类型可以以*.开头,如*.info,这样可以接收不同应用的消息
- #表示接收所有消息
#direct可以实现接收特定消息或指定消息 import pika,sys #发送端和接收端均不用声明queue connection=pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel=connection.channel() channel.exchange_declare(exchange='topic_logs', exchange_type='topic') result=channel.queue_declare(exclusive=True) queue_name=result.method.queue #定义级别,不指定级别会报错 severities=sys.argv[1:] if not severities: sys.stderr.write('Usage:%s [指定接收消息的类型]'%sys.argv[0]) #消费端接收的消息类型可以以*.开头,如*.info,这样可以接收不同应用的消息 sys.exit(1) for s in severities: channel.queue_bind(exchange='topic_logs', queue=queue_name,routing_key=s) # 绑定queue,要指定routing_key!! def callback(ch,method,properties,body): print('receive>>',body) channel.basic_consume(callback, queue=queue_name, #no_ack=True ) channel.start_consuming()

- rpc
- rpc可以实现客户-服务器进行双向通信,客户和服务器都将消息发送到rpc中,rpc用不同的队列支持它们通信
- 客户端
import pika import uuid class FibonacciRpcClient(object): def __init__(self): self.connection=pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) self.channel=self.connection.channel() result=self.channel.queue_declare(exclusive=True) self.callback_queue=result.method.queue self.channel.basic_consume(self.callback,no_ack=True,queue=self.callback_queue) def callback(self,ch,method,props,body): if self.corr_id==props.correlation_id: #判断从服务器端接收的UUID和之前发送的是否相等,借此判断是否是同一个消息队列 self.response=body#从服务器端收到的消息 def call(self,n): self.response=None self.corr_id=str(uuid.uuid4())#客户端发送请求时生成一个唯一的UUID self.channel.basic_publish(exchange='', routing_key='rpc_queue', properties=pika.BasicProperties(#消息持久化 reply_to=self.callback_queue, correlation_id=self.corr_id), body=str(n)) while self.response is None: self.connection.process_data_events() #一般情况下channel.start_consuming表示阻塞模式下接收消息 #这里不阻塞收消息,且隔一段时间检查有没有消息 #即非阻塞版的start_consuming print('no message...')#进行到这一步代表没有消息 return int(self.response) fibonacci_rpc=FibonacciRpcClient() response=fibonacci_rpc.call(6) print('get',response)
- 服务器端
import pika connection=pika.BlockingConnection(pika.ConnectionParameters(host='localhost')) channel=connection.channel() channel.queue_declare(queue='rpc_queue') def callback(ch,method,props,body): '''接收消息并返回结果''' n=int(body) print(n) response=fib(n) ch.basic_publish(exchange='', routing_key=props.reply_to,#要返回的队列名 properties=pika.BasicProperties(correlation_id=props.correlation_id),#使correlation_id等于客户端的并发送回去 body=str(response)) ch.basic_ack(delivery_tag=method.delivery_tag)#确认收到 def fib(n): '''斐波那契实现''' if n==0 or n==1: return n else: return fib(n-1)+fib(n-2) channel.basic_consume(callback,queue='rpc_queue') channel.start_consuming()