使用ChainMapReduce处理文件,现有某电商一天商品浏览情况数据goods_0,功能为在第一个Mapper里面过滤掉点击量大于600的商品,在第二个Mapper中过滤掉点击量在100~600之间的商品,Reducer里面进行分类汇总并输出,在Reducer后的Mapper里过滤掉商品名长度大于或等于3的商品
实验数据如下:
表goods_0,包含两个字段(商品名称,点击量),分隔符为"\t"。


商品名称 点击量 袜子 189 毛衣 600 裤子 780 鞋子 30 呢子外套 90 牛仔外套 130 羽绒服 7 帽子 21 帽子 6 羽绒服 12
package mapreduce10; import java.io.IOException; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.chain.ChainMapper; import org.apache.hadoop.mapreduce.lib.chain.ChainReducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.io.DoubleWritable; //09.Mapreduce实例——ChainMapReduce public class ChainMapReduce { private static final String INPUTPATH = "hdfs://192.168.51.100:8020/mymapreduce10/in/goods_0"; private static final String OUTPUTPATH = "hdfs://192.168.51.100:8020/mymapreduce10/out"; public static void main(String[] args) { try { Configuration conf = new Configuration(); FileSystem fileSystem = FileSystem.get(new URI(OUTPUTPATH), conf); if (fileSystem.exists(new Path(OUTPUTPATH))) { fileSystem.delete(new Path(OUTPUTPATH), true); } Job job = new Job(conf, ChainMapReduce.class.getSimpleName()); FileInputFormat.addInputPath(job, new Path(INPUTPATH)); job.setInputFormatClass(TextInputFormat.class); ChainMapper.addMapper(job, FilterMapper1.class, LongWritable.class, Text.class, Text.class, DoubleWritable.class, conf); ChainMapper.addMapper(job, FilterMapper2.class, Text.class, DoubleWritable.class, Text.class, DoubleWritable.class, conf); ChainReducer.setReducer(job, SumReducer.class, Text.class, DoubleWritable.class, Text.class, DoubleWritable.class, conf); ChainReducer.addMapper(job, FilterMapper3.class, Text.class, DoubleWritable.class, Text.class, DoubleWritable.class, conf); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(DoubleWritable.class); job.setPartitionerClass(HashPartitioner.class); job.setNumReduceTasks(1); job.setOutputKeyClass(Text.class); job.setOutputValueClass(DoubleWritable.class); FileOutputFormat.setOutputPath(job, new Path(OUTPUTPATH)); job.setOutputFormatClass(TextOutputFormat.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } catch (Exception e) { e.printStackTrace(); } } public static class FilterMapper1 extends Mapper<LongWritable, Text, Text, DoubleWritable> { private Text outKey = new Text(); private DoubleWritable outValue = new DoubleWritable(); @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, DoubleWritable>.Context context) throws IOException,InterruptedException { String line = value.toString(); if (line.length() > 0) { String[] splits = line.split("\t"); double visit = Double.parseDouble(splits[1].trim()); if (visit <= 600) { outKey.set(splits[0]); outValue.set(visit); context.write(outKey, outValue); } } } } public static class FilterMapper2 extends Mapper<Text, DoubleWritable, Text, DoubleWritable> { @Override protected void map(Text key, DoubleWritable value, Mapper<Text, DoubleWritable, Text, DoubleWritable>.Context context) throws IOException,InterruptedException { if (value.get() < 100) { context.write(key, value); } } } public static class SumReducer extends Reducer<Text, DoubleWritable, Text, DoubleWritable> { private DoubleWritable outValue = new DoubleWritable(); @Override protected void reduce(Text key, Iterable<DoubleWritable> values, Reducer<Text, DoubleWritable, Text, DoubleWritable>.Context context) throws IOException, InterruptedException { double sum = 0; for (DoubleWritable val : values) { sum += val.get(); } outValue.set(sum); context.write(key, outValue); } } public static class FilterMapper3 extends Mapper<Text, DoubleWritable, Text, DoubleWritable> { @Override protected void map(Text key, DoubleWritable value, Mapper<Text, DoubleWritable, Text, DoubleWritable>.Context context) throws IOException, InterruptedException { if (key.toString().length() < 3) { System.out.println("写出去的内容为:" + key.toString() +"++++"+ value.toString()); context.write(key, value); } } } }
结果:
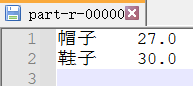
原理:
一些复杂的任务难以用一次MapReduce处理完成,需要多次MapReduce才能完成任务。Hadoop2.0开始MapReduce作业支持链式处理,类似于工厂的的生产线,每一个阶段都有特定的任务要处理,比如提供原配件——>组装——打印出厂日期,等等。通过这样进一步的分工,从而提高了生成效率,我们Hadoop中的链式MapReduce也是如此,这些Mapper可以像水流一样,一级一级向后处理,有点类似于Linux的管道。前一个Mapper的输出结果直接可以作为下一个Mapper的输入,形成一个流水线。
链式MapReduce的执行规则:整个Job中只能有一个Reducer,在Reducer前面可以有一个或者多个Mapper,在Reducer的后面可以有0个或者多个Mapper。
Hadoop2.0支持的链式处理MapReduce作业有一下三种:
(1)顺序链接MapReduce作业
类似于Unix中的管道:mapreduce-1 | mapreduce-2 | mapreduce-3 ......,每一个阶段创建一个job,并将当前输入路径设为前一个的输出。在最后阶段删除链上生成的中间数据。
(2)具有复杂依赖的MapReduce链接
若mapreduce-1处理一个数据集, mapreduce-2 处理另一个数据集,而mapreduce-3对前两个做内部连结。这种情况通过Job和JobControl类管理非线性作业间的依赖。如x.addDependingJob(y)意味着x在y完成前不会启动。
(3)预处理和后处理的链接
一般将预处理和后处理写为Mapper任务。可以自己进行链接或使用ChainMapper和ChainReducer类,生成得作业表达式类似于:
MAP+ | REDUCE | MAP*
如以下作业: Map1 | Map2 | Reduce | Map3 | Map4,把Map2和Reduce视为MapReduce作业核心。Map1作为前处理,Map3, Map4作为后处理。ChainMapper使用模式:(预处理作业),ChainReducer使用模式:(设置Reducer并添加后处理Mapper)
本实验中用到的就是第三种作业模式:预处理和后处理的链接,生成得作业表达式类似于 Map1 | Map2 | Reduce | Map3