一、类型
1、从样例中学习:
1.符号主义学习:决策树
2.连接主义学习:神经网络---深度学习
(深度学习的第二春原因:数据大了、计算能力强了。)
2、统计学习:
支持向量机(核方法)
二、模型评估与选择
我们希望的是,在新样本上能表现很好的学习器。为了达到这个目的,应该从训练样本中尽可能学出适用于所有潜在样本的“普遍规律”,这样才能在遇到新样本时做出正确的判断。然而,当学习器把训练样本学得“太好”了的时候,很可能已经把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,这样就会导致泛化能力下降。这种现象在机器学习中成为“过拟合”,与此相对的是“欠拟合”,这是指对训练样本的一般性质尚未学好。
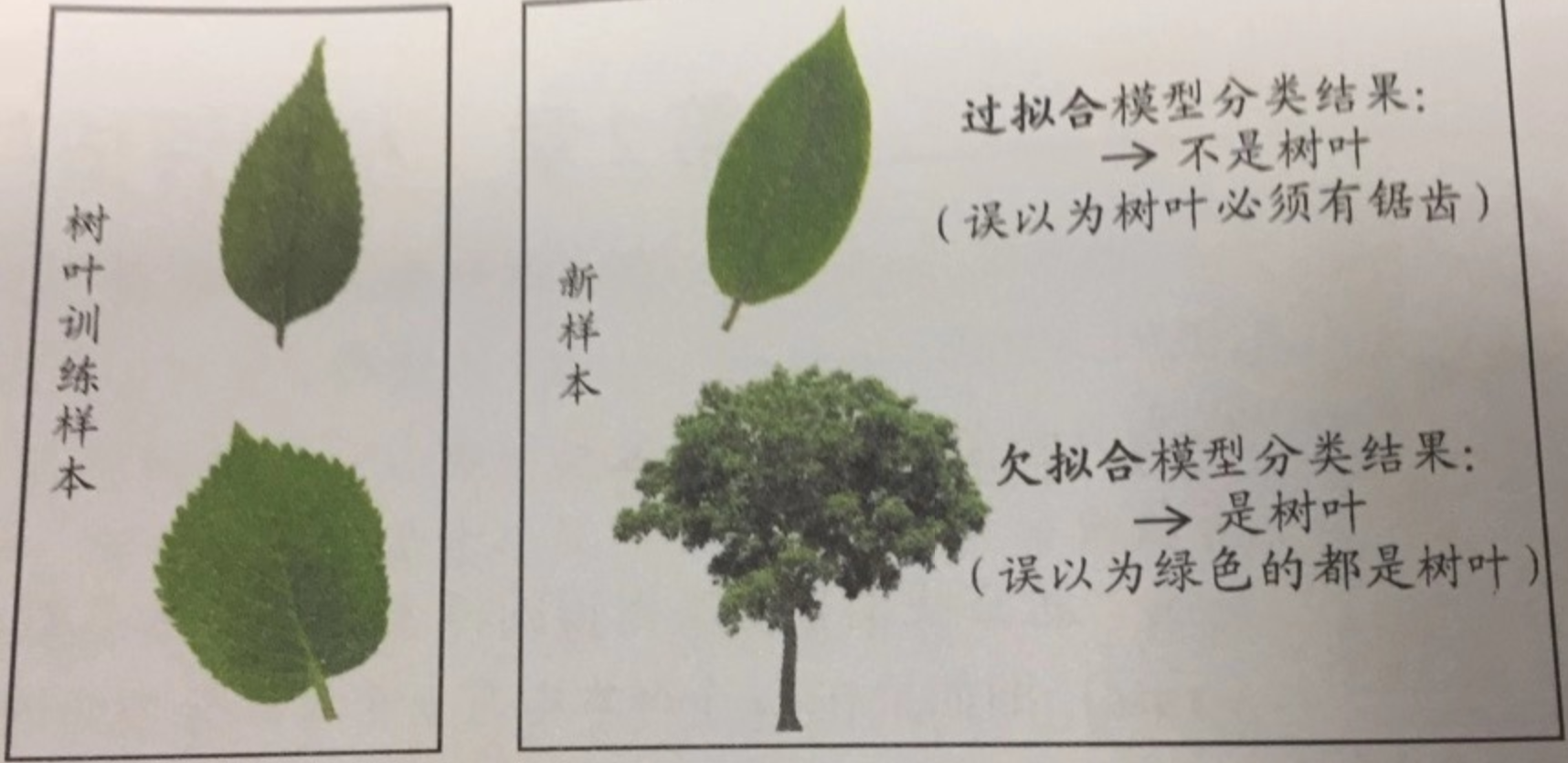
(过拟合是机器学习面临的关键障碍)
1
在现实任务中,我们往往有多种学习算法可以选择,甚至同一个算法,使用不同的参数配置时,也会产生不同的模型,那么我们该选择算法,使用哪一种参数的配置呢?这就是机器学习中“模型选择”的问题。
训练集
测试集
交叉验证法
调参
2
对学习器的泛化能力进行评估,不仅需要有效可行的实验估计方法,还需要有衡量模型泛化能力的评价标准,这就是性能度量。
3
有了实验评估方法和性能度量,看起来就能对机器学习的性能进行评估了,但是如何比较呢?实际上,机器学习中性能比较这件事要比我们想象复杂的多。那么有没有适当的方法对学习器的性能进行比较呢?
统计假设检验为我们进行学习器性能比较提供了重要依据。
4
对学习算法除了通过实验估计其泛化能力,我们还想了解它为什么具有这样的性能,“偏差-方差分解”是解释学习算法泛化性能的一种重要工具。