xml文档的格式:
xml文档的操作
1.读取
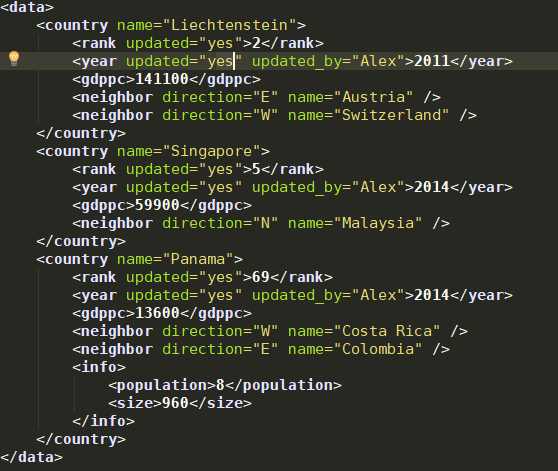
整个文档:
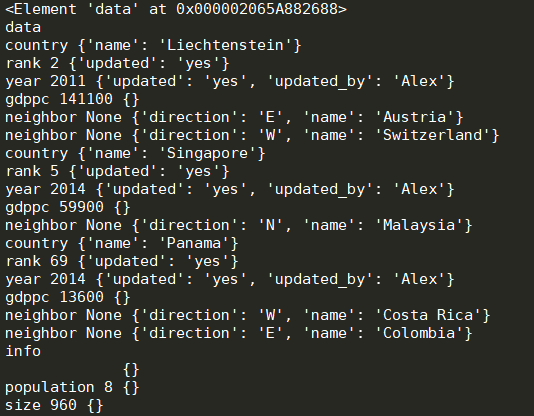
1 import xml.etree.ElementTree as xET 2 3 4 tree=xET.parse('xml_test.xml') 5 root=tree.getroot() #返回内存地址 6 print(root) 7 print(root.tag) #显示标签名 8 9 #遍历xml文档 10 for child in root: #child:内存对象 11 print(child.tag,child.attrib)#child.tag:标签名,child.attrib:属性 12 13 for i in child: #每个标签下还有东西,再遍历 14 print(i.tag,i.text,i.attrib) 15 16 for j in i:#显示下一层的东西 17 print(j.tag,j.text,j.attrib) 18 19 #如果下一层还有信息就再继续写
运行结果:
只读取部分文档:
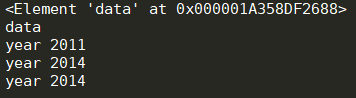
1 import xml.etree.ElementTree as xET 2 3 4 tree=xET.parse('xml_test.xml') 5 root=tree.getroot() #返回内存地址 6 print(root) 7 print(root.tag) #显示标签名 8 9 #只遍历year 节点 10 for node in root.iter('year'): 11 print(node.tag,node.text)
运行结果:
2.xml文档的修改
1 #修改 2 3 import xml.etree.ElementTree as xET 4 5 tree=xET.parse('xml_test.xml') 6 root=tree.getroot() 7 8 for node in root.iter('year'): 9 new_year=int(node.text)+1#把每一年都加1 10 node.text=str(new_year) 11 node.set('updated','yes')#加属性yes 12 tree.write('xml_test.xml') 13 14 #删除node 15 16 for country in root.findall('country'): 17 rank=int(country.find('rank').text) 18 19 if rank>50:#将rank大于50的country删除 20 root.remove(country) 21 22 tree.write('removexml.xml')
运行结果:
原xml文件:
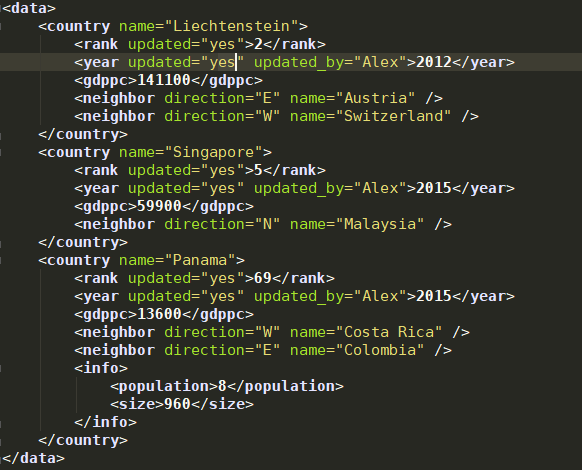
输出country之后生成的xml文件:

3.新建xml文件
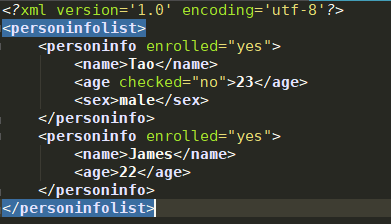
1 #自己创建一个新的xml文件 2 3 import xml.etree.ElementTree as xET 4 5 new_xml=xET.Element('personinfolist') 6 personinfo=xET.SubElement(new_xml,'personinfo',attrib={'enrolled':'yes'}) 7 name=xET.SubElement(personinfo,'name') 8 name.text='Tao' 9 age=xET.SubElement(personinfo,'age',attrib={'checked':'no'}) 10 age.text='23' 11 sex=xET.SubElement(personinfo,'sex') 12 sex.text='male' 13 personinfo2=xET.SubElement(new_xml,'personinfo',attrib={'enrolled':'yes'}) 14 name=xET.SubElement(personinfo2,'name') 15 name.text='James' 16 age=xET.SubElement(personinfo2,'age') 17 age.text='22' 18 19 et=xET.ElementTree(new_xml) 20 et.write('setupxml.xml',encoding='utf-8',xml_declaration=True)#xml_declaration声明是xml格式的 21 22 xET.dump(new_xml)
新建的xml文件: