1.主题
Kafka将一组消息抽象归纳为一个主题(Topic),也就是说,一个主题就是对消息的一个分类。
生产者将消息发送到特定主题,消费者订阅主题或主题的某些分区进行消费。
2.消息
消息是Kafka通信的基本单位,由一个固定长度的消息头和一个可变长度的消息体构成。
在老版本中,每一条消息称为Message;在由Java重新实现的客户端中,每一条消息称为Record。
3.分区和副本
Kafka将一组消息归纳为一个主题,而每个主题又被分成一个或多个分区(Partition)
每个分区在物理上对应为一个文件夹,分区的命名规则为主题名称后接“—”连接符
之后再接分区编号,分区编号从0开始,编号最大值为分区的总数减1
每个分区又有一至多个副本(Replica)
分区的副本分布在集群的不同代理上,以提高可用性
Kafka只能保证一个分区之内消息的有序性,并不能保证跨分区消息的有序性
Kafka提供两种删除老数据的策略,一是基于消息已存储的时间长度,二是基于分区的大小
4.Leader副本和Follower副本
Leader副本只有一个,Follower副本有多个
只有Leader副本才负责处理客户端读/写请求,Follower副本从Leader副本同步数据
实际上使用的只有Leader副本,Follower副本只是作为备份使用
如果Leader失效,通过相应的选举算法将从其他Follower副本中选出新的Leader副本
5.偏移量
每条消息在日志文件中的位置都会对应一个按序递增的偏移量
因此Kafka并没有提供额外索引机制到存储偏移量,也就是说并不会给偏移量再提供索引。
消费者可以通过控制消息偏移量来对消息进行消费,如消费者可以指定消费的起始偏移量。
为了保证消息被顺序消费,消费者已消费的消息对应的偏移量也需要保存
旧版消费者将消费偏移量保存到ZooKeeper当中,而新版消费者是将消费偏移量保存到Kafka内部一个主题当中

Kafka在数据写入及数据同步采用了零拷贝(zero-copy)技术,采用sendFile()函数调用,
sendFile()函数是在两个文件描述符之间直接传递数据,完全在内核中操作,
从而避免了内核缓冲区与用户缓冲区之间数据的拷贝,操作效率极高。
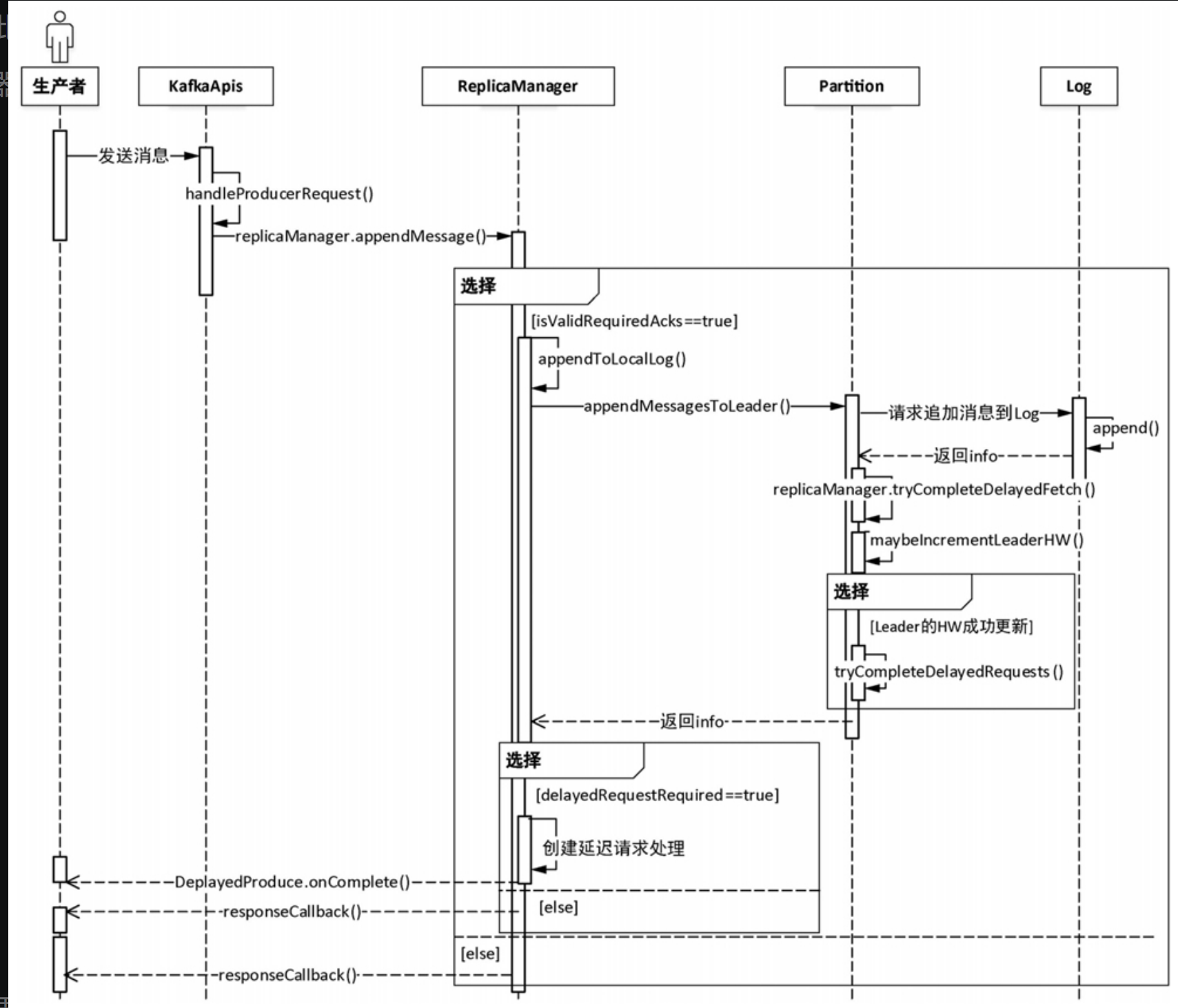
生产者向kafka发送消息
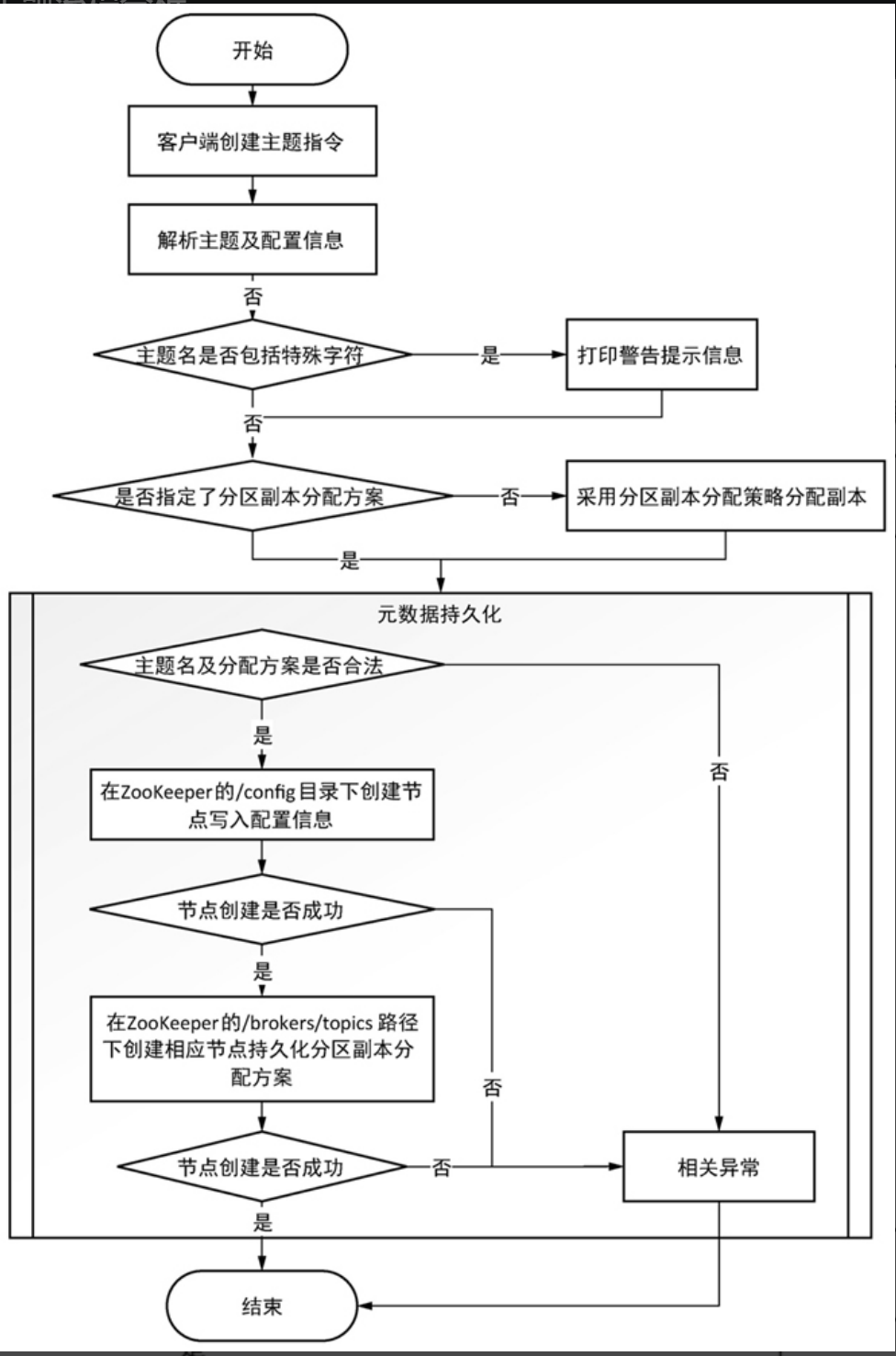
创建主题过程
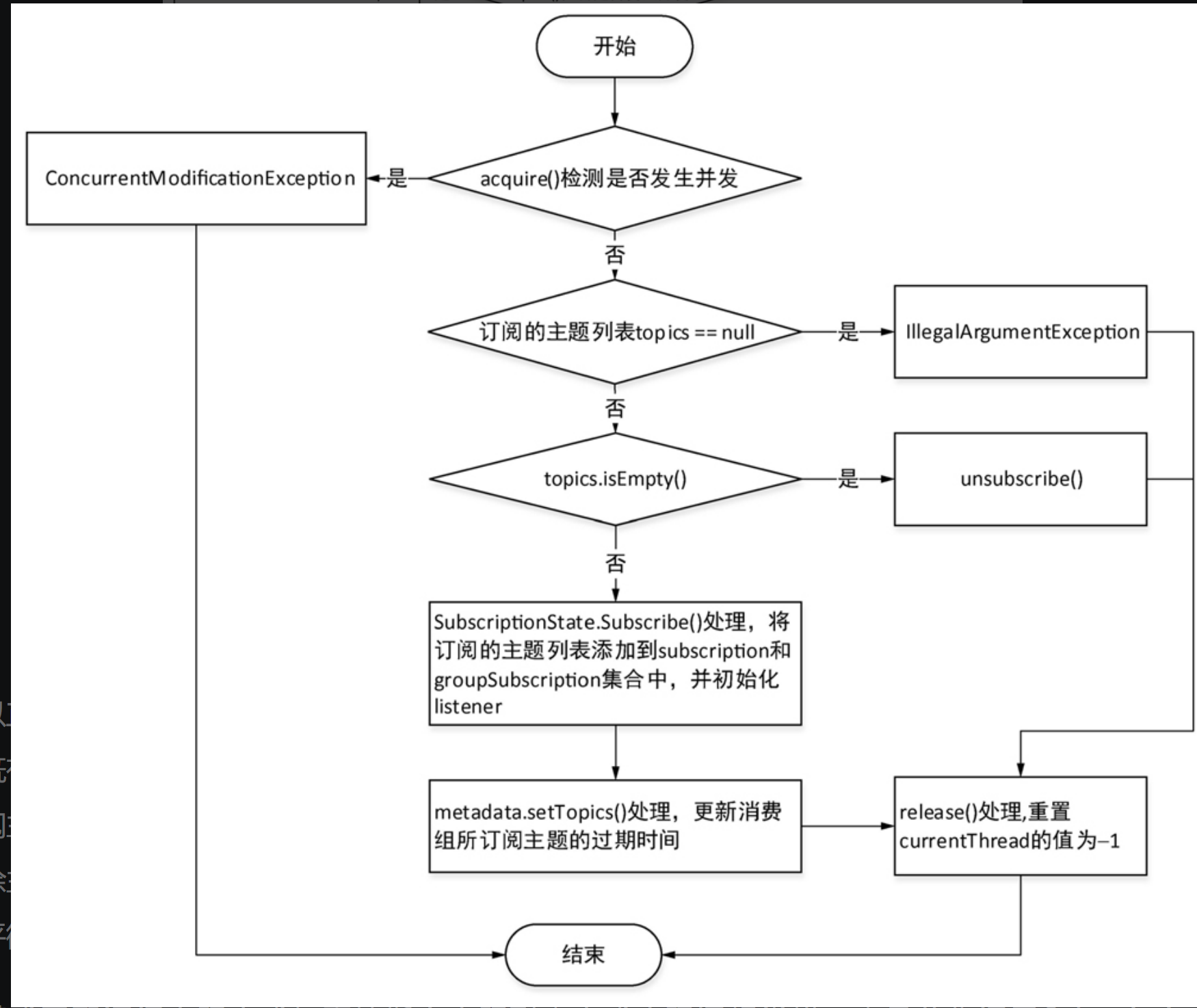
订阅主题流程
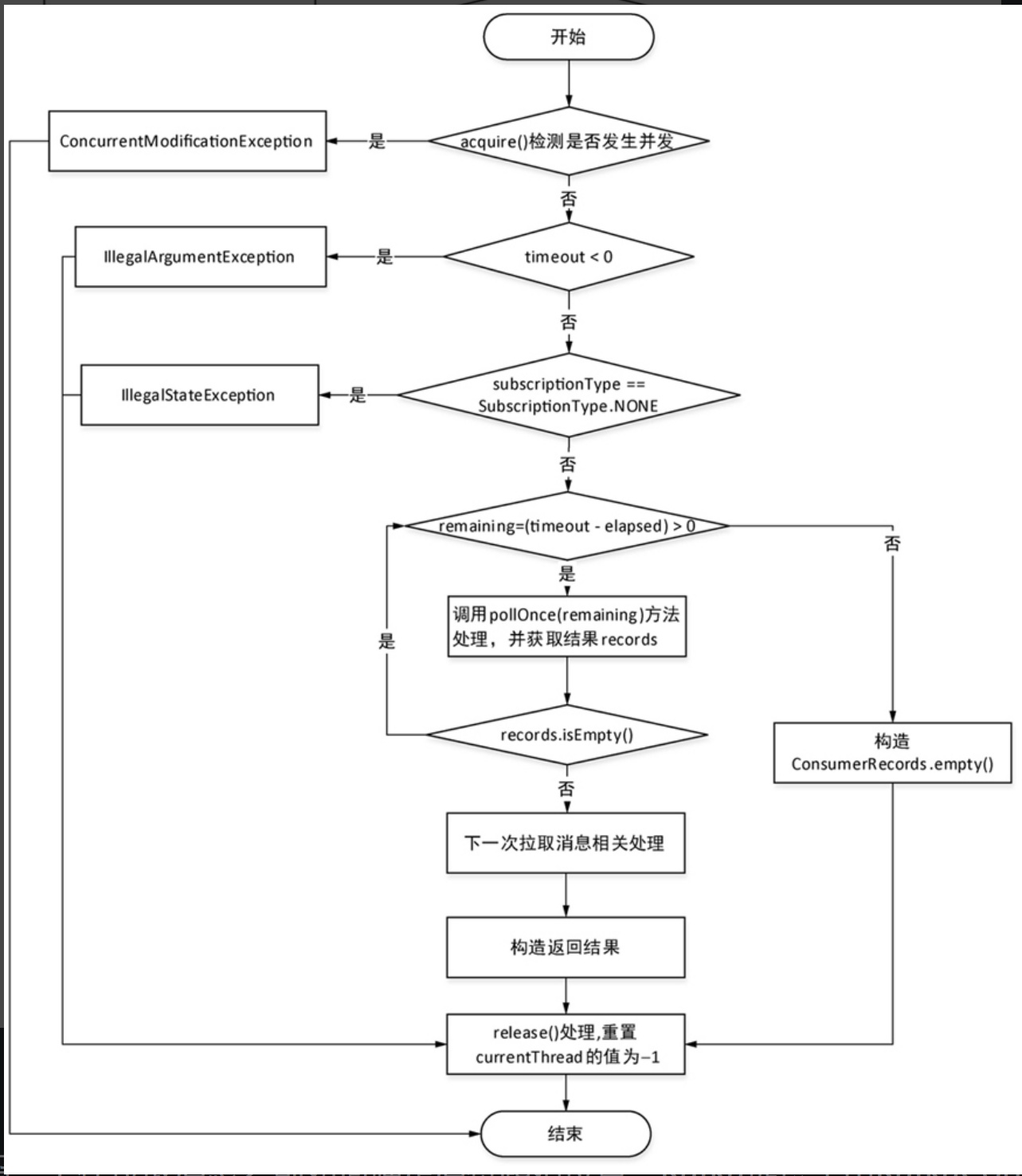
拉取消息流程