概述
文章将介绍分布式在redis中的运用,介绍了 RedLock 实现的思路还有功能的实现。
分布式锁的动机
当有多个 client 但是只有一个有执行权的分布式结构就可以考虑使用分布式锁。我们首先要知道锁的目的是为了达到执行的顺序性。
RedLock 的设计
两个必须达到的目标 : 安全和活性保障
- 安全属性 : 互斥,保证了同一个时刻只有一个 client 获得到锁。
- 活性属性A : 死锁释放,客户端crash 或是集群分区获取的锁可以释放
- 活性属性B : 错误容忍,只要大部分的 redis 节点都存活,客户端就有可能获取和释放锁。
为什么只有 failover-base 的实现是不够的
这是因为我们一般会使用 master-slave 实现主从复制达到高可用,然而有可能会出现以下情况 :
- Client A acquires the lock in the master.(clientA 在master 中获取到了锁)
- The master crashes before the write to the key is transmitted to the slave.(在master 复制写入到slave的时候,master down掉了)
- The slave gets promoted to master.(此时 slave 从原来masster继承,成为了新的master)
- Client B acquires the lock to the same resource A already holds a lock for. SAFETY VIOLATION!(由于旧的master down掉了,那么写入的请求没能复制成功,clientB在新的master中获取了锁,此时已有两个客户端拿到了锁)
RedLock 的实现
基于单Redis节点的分布式锁
获取锁
SET resource_name my_random_value NX PX 30000
我们看到这里运用的主要有两个东西 :my_randow_value 和 过期时间。 my_random_value 对于每一个 client 都是唯一的,是用来顺序释放锁在一个安全的方式,下面用lua 来表示这个过程 : 假如这个锁存在,且当中的 my_random_value 正是和我的一样,那么就可以安全的删除。
而关于过期时间
当一个客户端获取锁成功之后,假如它崩溃了,或者由于发生了网络分割(network partition)导致它再也无法和Redis节点通信了,那么它就会一直持有这个锁,而其它客户端永远无法获得锁了
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
为什么要使用上这 my_random_value 呢?每一个client 的 my_random_value 都是相同的可以吗?考虑下面的情况。
- 客户端1获取锁成功。
- 客户端1在某个操作上阻塞了很长时间。
- 过期时间到了,锁自动释放了。
- 客户端2获取到了对应同一个资源的锁。
- 客户端1从阻塞中恢复过来,释放掉了客户端2持有的锁
其实这种情况就像 CAS 中的 ABA 问题一样,后一个的操作并不知道资源被其他客户端持有了。
ok,我们接下来看一下 RedLock 实现的分布式情况的分布式锁。
RedLock 分布式锁过程简述
以下描述来自参考资料 :
它基于N个完全独立的Redis节点。
-
获取当前时间(毫秒数)。
-
按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。
-
计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
-
如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
-
如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
可以看到纪录的时间没有一个统一的标准,假如存在某个节点时间流逝得比较快,
实例 restart 的注意事项
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
- 客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。
- 节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
- 节点C重启后,客户端2锁住了C, D, E,获取锁成功。
上面分析的由于节点重启引发的锁失效问题,总是有可能出现的。为了应对这一问题,antirez又提出了延迟重启(delayed restarts)的概念。也就是说,一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,这段时间应该大于锁的有效时间(lock validity time)。这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
释放锁的注意事项
在最后释放锁的时候,antirez在算法描述中特别强调,客户端应该向所有Redis节点发起释放锁的操作。也就是说,即使当时向某个节点获取锁没有成功,在释放锁的时候也不应该漏掉这个节点。这是为什么呢?设想这样一种情况,客户端发给某个Redis节点的获取锁的请求成功到达了该Redis节点,这个节点也成功执行了SET操作,但是它返回给客户端的响应包却丢失了。这在客户端看来,获取锁的请求由于超时而失败了,但在Redis这边看来,加锁已经成功了。因此,释放锁的时候,客户端也应该对当时获取锁失败的那些Redis节点同样发起请求。实际上,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。
Martin的分析
Martin Kleppmann在2016-02-08这一天发表了一篇blog,名字叫”How to do distributed locking “,地址如下: https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html 他对redlock提出了几点质疑 :
- RedLock有可能会由于GC导致锁失效
- RedLock强依赖时间,本身的安全性是不够的。
GC 对分布式锁的影响
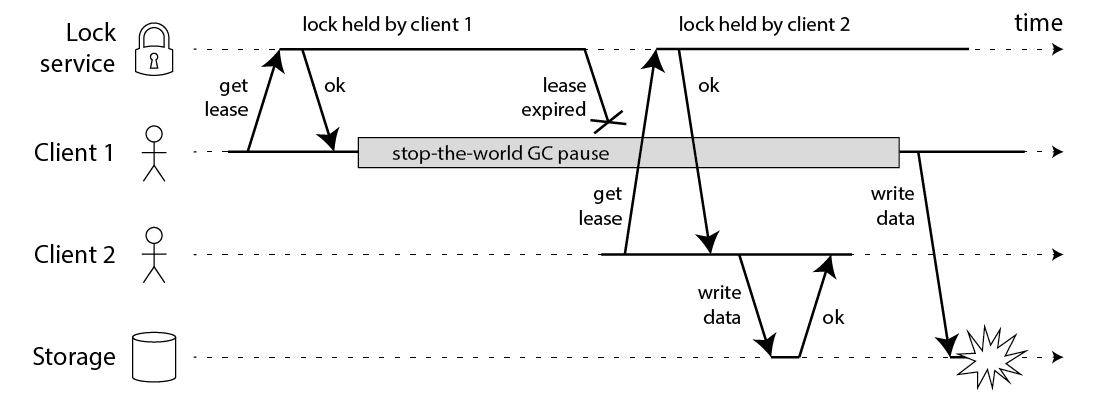
可以看到当GC时执行的线程会阻塞从而导致锁过期,当客户端1从GC pause中恢复过来的时候,它不知道自己持有的锁已经过期了,它依然向共享资源(上图中是一个存储服务)发起了写数据请求,而这时锁实际上被客户端2持有,因此两个客户端的写请求就有可能冲突(锁的互斥作用失效了)。
那既然GC是破坏锁互斥的重要因素,那不用GC环境可以了吗。M在文章也提出了电脑系统复杂,例如内存缺页等等都有可能导致这样的现象发生,M 提出了fencing token 的东西用于避免这类事件。
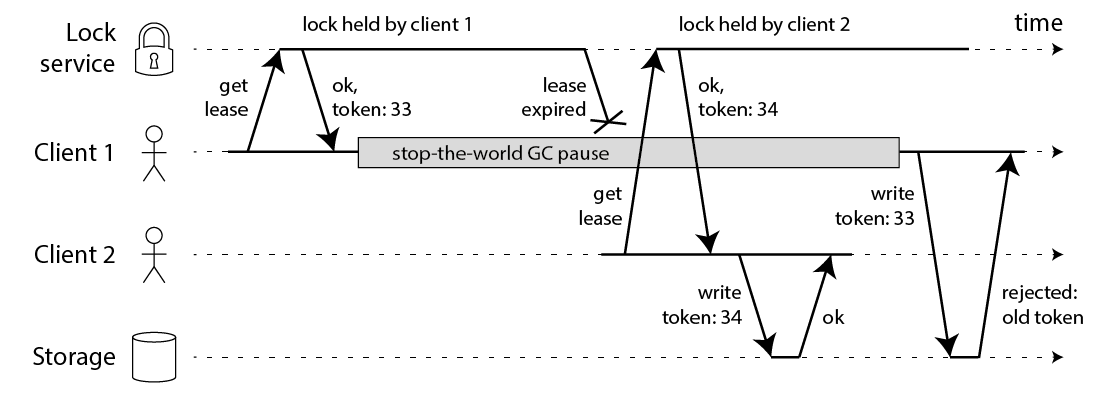
个人觉得很奇怪,这个fencing token 和 RedLock 中 my_random_value 的作用不是一样的吗,虽然 token 保持有顺序可是就是为了识别该资源已被其他客户端锁定。
时间性强依赖导致的安全性
来自参考资料的描述 :
Martin在文中构造了一些事件序列,能够让Redlock失效(两个客户端同时持有锁)。为了说明Redlock对系统记时(timing)的过分依赖,他首先给出了下面的一个例子(还是假设有5个Redis节点A, B, C, D, E):
- 客户端1从Redis节点A, B, C成功获取了锁(多数节点)。由于网络问题,与D和E通信失败。
- 节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
- 客户端2从Redis节点C, D, E成功获取了同一个资源的锁(多数节点)。
- 客户端1和客户端2现在都认为自己持有了锁。 上面这种情况之所以有可能发生,本质上是因为Redlock的安全性(safety property)对系统的时钟有比较强的依赖,一旦系统的时钟变得不准确,算法的安全性也就保证不了了。Martin在这里其实是要指出分布式算法研究中的一些基础性问题,或者说一些常识问题,即好的分布式算法应该基于异步模型(asynchronous model),算法的安全性不应该依赖于任何记时假设(timing assumption)。在异步模型中:进程可能pause任意长的时间,消息可能在网络中延迟任意长的时间,甚至丢失,系统时钟也可能以任意方式出错。一个好的分布式算法,这些因素不应该影响它的安全性(safety property),只可能影响到它的活性(liveness property),也就是说,即使在非常极端的情况下(比如系统时钟严重错误),算法顶多是不能在有限的时间内给出结果而已,而不应该给出错误的结果。这样的算法在现实中是存在的,像比较著名的Paxos,或Raft。但显然按这个标准的话,Redlock的安全性级别是达不到的。
上面描述的这一段使我们想起了 CAP 中的 CP ,为了保持一致性,牺牲的只能是可用性。
补充
SETNX
SETNX 命令的意思是 : [Set if Not exists] 也就说不存在的时候就会设置,SETNX 是不支持过期设置的,所以上文在实现通过Lua来达到执行的原子性。
超时解锁导致并发
当一个客户端获取锁后可能由于时间设置太短从而导致,未执行完锁就由于过期释放了,而其他客户端就可以加锁执行,从而会有两个客户端获得了资源。解决的方法如下 :
- 增加执行时间作为过期时间,也即是增加过期时间
- 增加守护线程,当快过期时增加过期时间
锁可重入性
我们知道java中,可以作为锁重入性判断的数据结构有 : ThreadLocal ,那么Redis是如何实现的呢?我们看一下 Redission 是如何实现的。
// 如果 lock_key 不存在
if (redis.call('exists', KEYS[1]) == 0)
then
// 设置 lock_key 线程标识 1 进行加锁
redis.call('hset', KEYS[1], ARGV[2], 1);
// 设置过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
// 如果 lock_key 存在且线程标识是当前欲加锁的线程标识
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1)
// 自增
then redis.call('hincrby', KEYS[1], ARGV[2], 1);
// 重置过期时间
redis.call('pexpire', KEYS[1], ARGV[1]);
return nil;
end;
// 如果加锁失败,返回锁剩余时间
return redis.call('pttl', KEYS[1]);
可以看到是使用一个 hset的结构来实现的,实际上 ThreadLocal 中也是用散列表来存放对应的数据的。
释放锁的重试
客户端当获取锁失败后会再次重试获取锁,那么重试功能的实现可以这样 :
- 轮询
- 信号通知,使用redis的发布订阅功能,当获取失败时,订阅锁释放的信息。 信号通知的过程如下,图来自 : https://xiaomi-info.github.io/2019/12/17/redis-distributed-lock/

总结
RedLock 的实现需要依赖各节点的时间,这是我们需要关注的一点。文章讲了redLock实现思路和关于 RedLock 的一些争议,最后补充部分总结了几种功能实现的思路。
参考资料
- https://redis.io/topics/distlock (官方文档)
- http://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html (关于RedLock这个分布式锁的问题)
- http://zhangtielei.com/posts/blog-redlock-reasoning.html (必看)
- https://www.one-tab.com/page/Wuz27GojRK6uiiBMgKcbwQ (网页全集)