转载链接:https://www.jianshu.com/p/4e5b3e652639
Szegedy在2015年发表了论文Rethinking the Inception Architecture for Computer Vision,该论文对之前的Inception结构提出了多种优化方法,来达到尽可能高效的利用计算资源的目的。作者认为随意增大Inception的复杂度,后果就是Inception的错误率很容易飙升,还会成倍的增加计算量,所以必须按照一套合理的规则来优化Inception结构,具体如下:
一、基本规则
规则1:要防止出现特征描述的瓶颈(representational bottleneck)。所谓特征描述的瓶颈就是中间某层对特征在空间维度进行较大比例的压缩(比如使用pooling时),导致很多特征丢失。虽然Pooling是CNN结构中必须的功能,但我们可以通过一些优化方法来减少Pooling造成的损失。
规则2:特征的数目越多收敛的越快。相互独立的特征越多,输入的信息就被分解的越彻底,分解的子特征间相关性低,子特征内部相关性高,把相关性强的聚集在了一起会更容易收敛。这点就是Hebbin原理:fire together, wire together。规则2和规则1可以组合在一起理解,特征越多能加快收敛速度,但是无法弥补Pooling造成的特征损失,Pooling造成的representational bottleneck要靠其他方法来解决。
规则3:可以压缩特征维度数,来减少计算量。inception-v1中提出的用1x1卷积先降维再作特征提取就是利用这点。不同维度的信息有相关性,降维可以理解成一种无损或低损压缩,即使维度降低了,仍然可以利用相关性恢复出原有的信息。
规则4:整个网络结构的深度和宽度(特征维度数)要做到平衡。只有等比例的增大深度和维度才能最大限度的提升网络的性能。
二、优化方法
以下优化方法就是根据前面的规则总结出的:
方法1:可以将大尺度的卷积分解成多个小尺度的卷积来减少计算量。比如将1个5x5的卷积分解成两个3x3的卷积串联,从图1左侧可以看出两级3x3的卷积的覆盖范围就是5x5,两者的覆盖范围没有区别。假设5x5和两级3x3卷积输出的特征数相同,那两级3x3卷积的计算量就是前者的(3x3+3x3)/5x5=18/25。

方法2:可以使用非对称卷积。将nxn的卷积分解成1xn和nx1卷积的串联,例如n=3,分解后就能节省33%的计算量(图1右侧)。作者通过测试发现非对称卷积用在网络中靠中间的层级才有较好的效果(特别是feature map的大小在12x12~20x20之间时)。
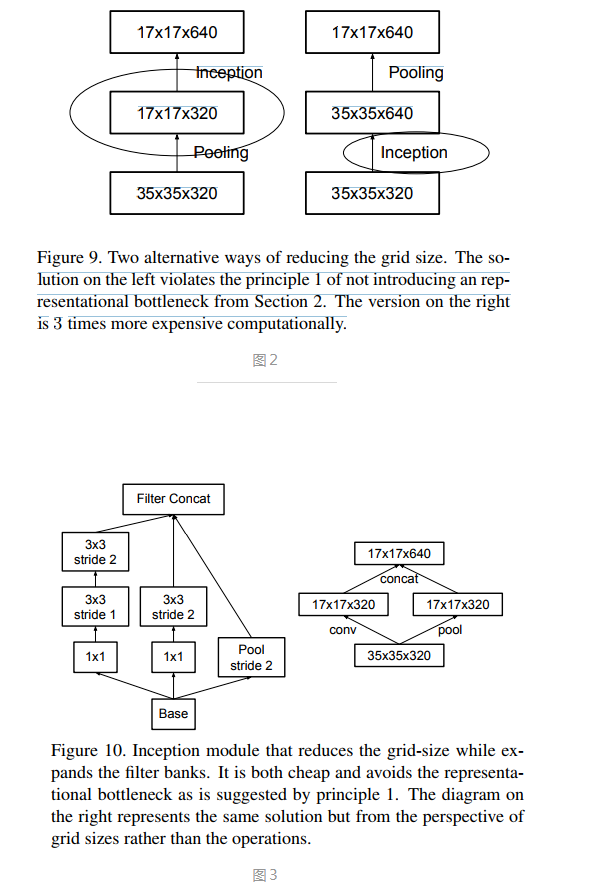
方法3:可以使用并行结构来优化Pooling。前面的规则1提到Pooling会造成represtation bottleneck,一种解决办法就是在Pooling前用1x1卷积把特征数加倍(见图2右侧),这种加倍可以理解加入了冗余的特征,然后再作Pooling就只是把冗余的信息重新去掉,没有减少信息量。这种方法有很好的效果但因为加入了1x1卷积会极大的增大 计算量。替代的方法是使用两个并行的支路,一路1x1卷积,由于特征维度没有加倍计算量相比之前减少了一倍,一路是Pooling,最后再在特征维度拼合到一起(见图3)。这种方法即有很好的效果,又没有增大计算量。
方法4:使用Label Smoothing来对网络输出进行正则化。
Softmax层的输出可以用下面图4公式表示,损失loss可以用图5表示。假设分类的标签是独热码表示(正确分类是1,其他类别是0),从公式4可以反推出整个训练过程收敛时Softmax的正确分类的输入Zk是无穷大,这是一种极其理想的情况,如果让所有的输入都产生这种极其理想的输出,就会造成overfit(回想一下overfit的概念:能对所有的输入进行最理想的分类,鲁棒性差)。所以为了克服overfit,防止最终出来的正确分类p(k)=1,在输出p(k)时加了个参数delta(图6),生成新的q'(k),再用它替换公式5中的q(k)来计算loss。

者还对自己在GoogLeNet论文中提出的 分支分类器(Auxiliary Classifiers)效果进行了纠正。Szegedy认为自己当时的结论就是错误的,特别是靠近输入侧的那个Auxiliary Classifier,加不加完全没区别,但如果在靠近输出的那个Auxiliary Classifier的全连接层后加个BN,会起到正则化的作用,所有 第二个Auxiliary Classifier还是可以保留。起正则化作用的原因Szegedy完全没解释。。。
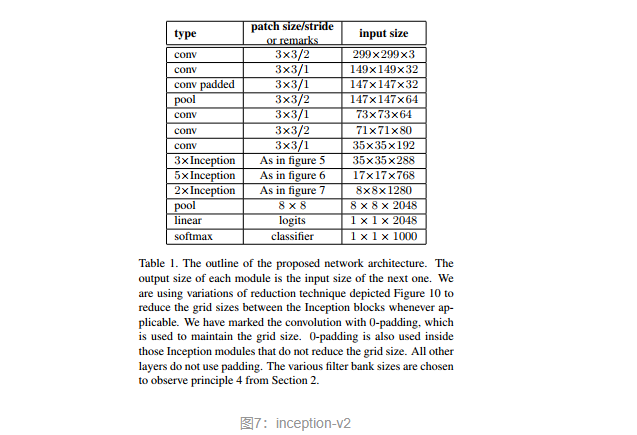
把上述的方法1~方法4组合到一起,就有了inceptio-v2结构(图7),图7中的三种inception模块的具体构造见图8。inception-v2的结构中如果Auxiliary Classifier上加上BN,就成了inception-v3。