有时候会遇到这种情况:想从某个网站下载一批东西,目标URL是比较规整的,而且结构都一样(仅某些字段不同)。但又懒得开IDE专门写个脚本去弄,今天就和大家分享一下,如何利用手边常用的软件和工具,不用写一行代码或者脚本,就能完成这项工作。
需要的软件工具有:正则表达式工具、WGET(或者CURL)、EXCEL、记事本。
你看,并没有用到任何开发语言和脚本语言嘛。
一、获取下载索引页代码
首先需要分析一下下载索引页URL的规律,其点两页就能发现,仅有最后的PAGE参数内容不同,单调递增。然后再找到最后一页的页面(本例里是71)。

现在把前面固定的部分提取出来(直到末尾的”page=“),复制到EXCEL里的第一列,然后把参数值放到第二列。
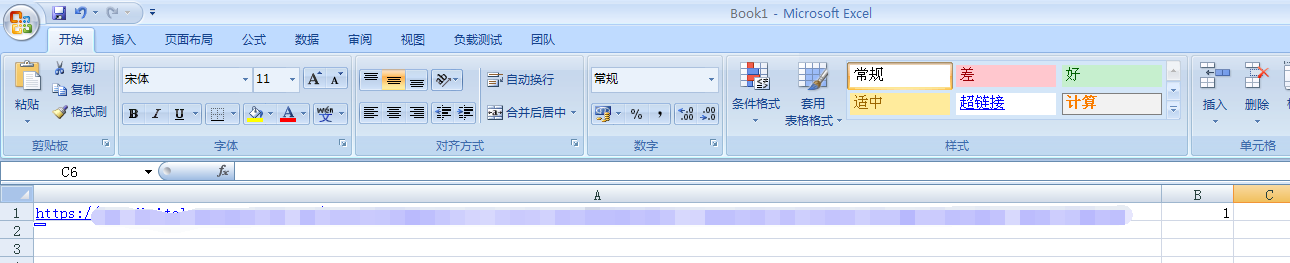
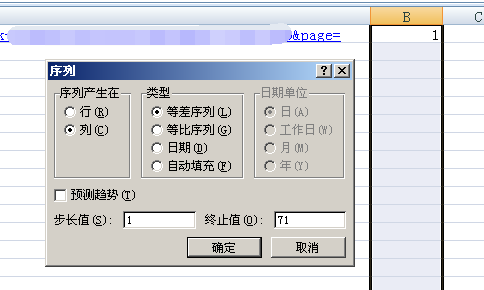
然后对第二列向下进行填充,规律是单调递增,直到最末页码。然后把左边复制成同样数量。
最终结果:
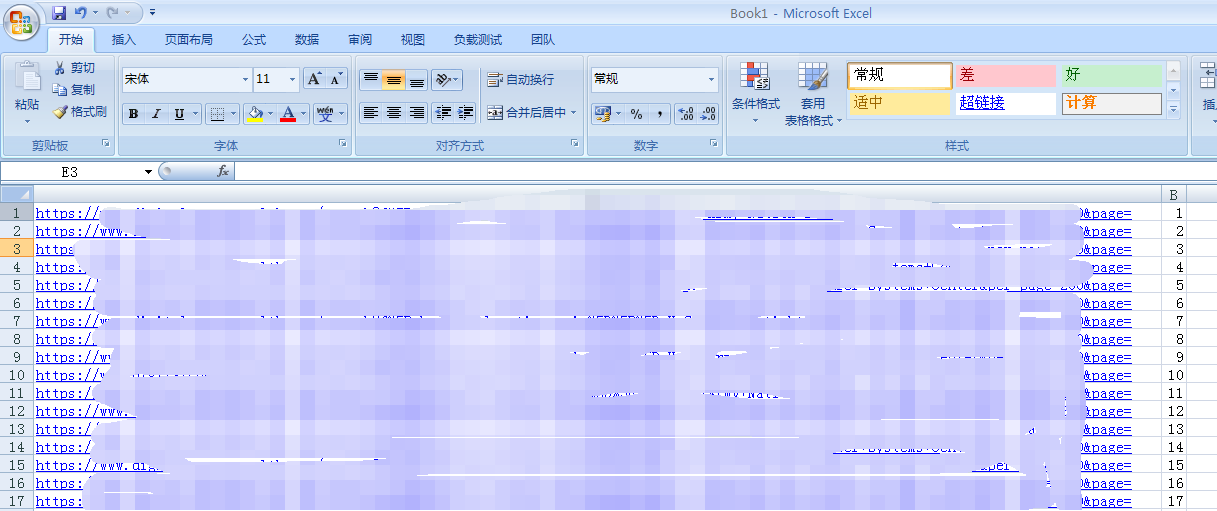
然后把这个表格全部复制到记事本(notepad.exe)里。

字段(原本的表格列)之间会被 (tab)分隔,只要替换成空字符(删除)就行了。
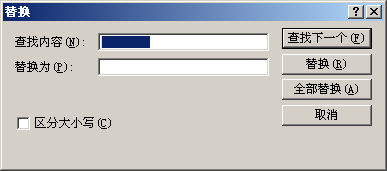
这样我们就得到了完整的索引页下载列表。如果变量部分在链接的中间也不怕,反正URL参数顺序是可以调换的,挪到最后即可。实在不行也可以在表格后面补一列来补全。人要学会举一反三嘛。

把它丢给wget去搞定就行了。
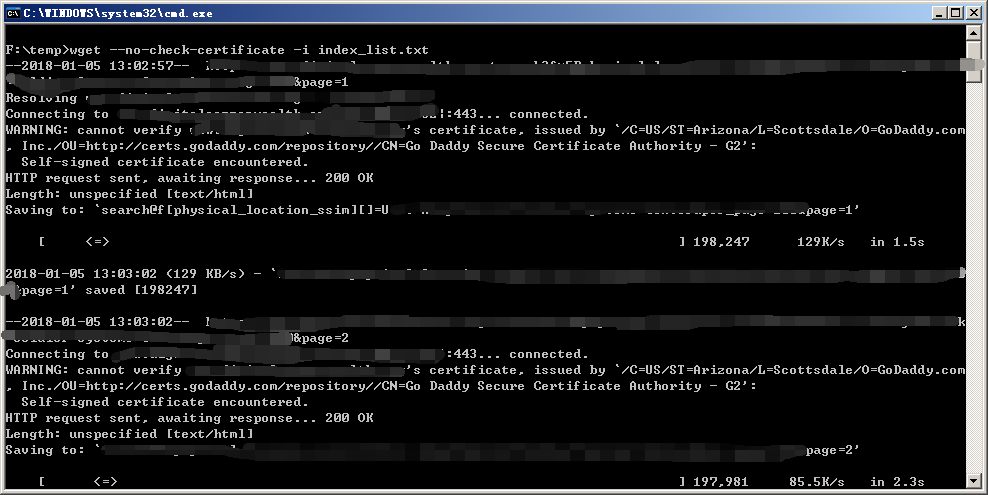
这样我们就得到了包含了最终下载目标的所有的索引页的网页内容。
二、分析、提取并构造最终下载目标列表
有了索引页的代码,我们下一步的工作就是将最终下载目标从索引页代码里批量提取出来。
通过对比实际链接和索引页代码的内容,我发现最终下载目标的URL里的关键部分已经包含在索引页代码里,提取出来之后前后补全链接其他部分即可。
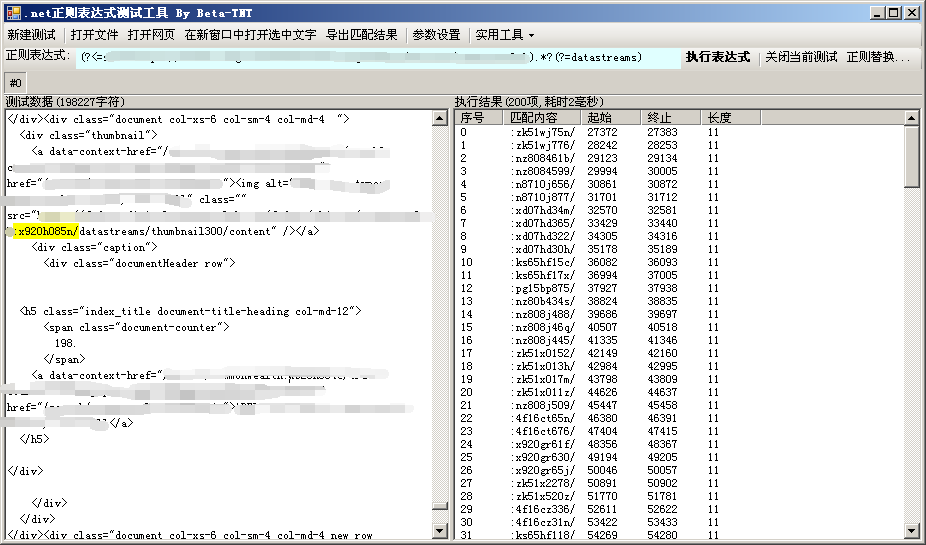
这个工具是我自己写的哈,用正则表达式处理文本用的。以后有空会做一个命令行版本。
这里有一个小技巧,就是提取关键数据的时候前后可以留一点尾巴,补全链接的时候可以用。在本例里我就留了前面的冒号和后面的斜杠。补全链接的时候分别替换成链接前缀和链接后缀就OK了。注意一定不能留前后相同的,也不能和关键内容重复。如果实际情况不允许的话,可以继续用上文介绍的EXCEL表格的方式批量补全链接。
由于所有的索引页代码结构完全一样,所以用相同的正则就能全部提取出来。我开发的这个工具有一个批量提取的功能,我相信其他正则表达式工具也都有类似的功能。
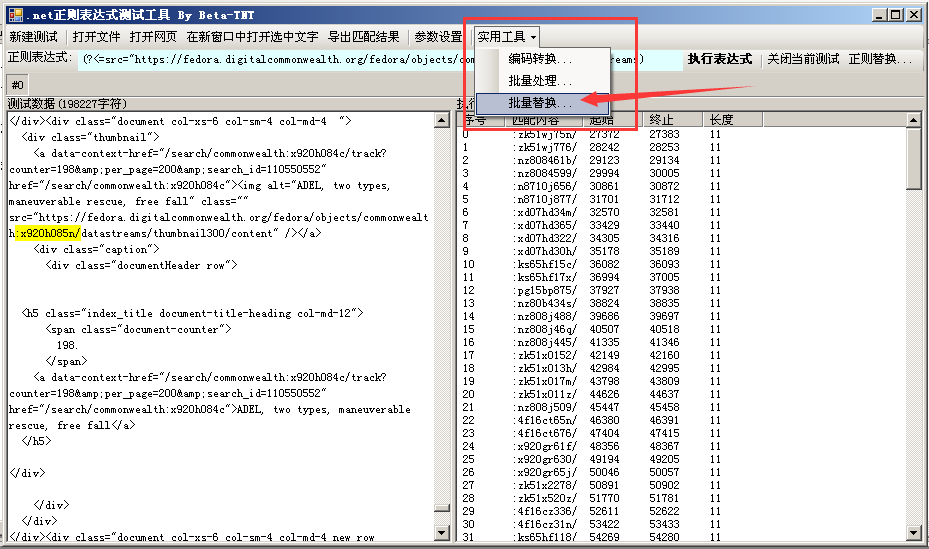
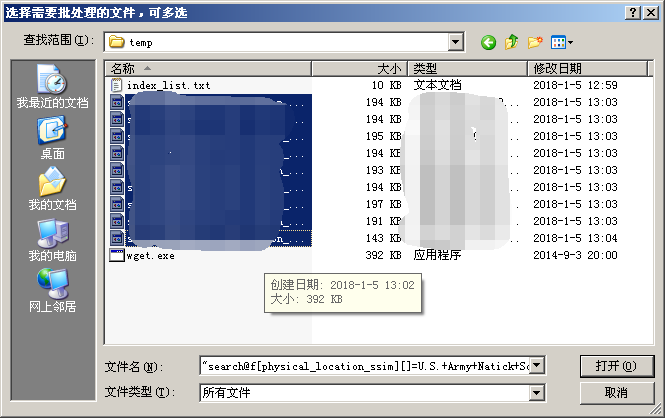
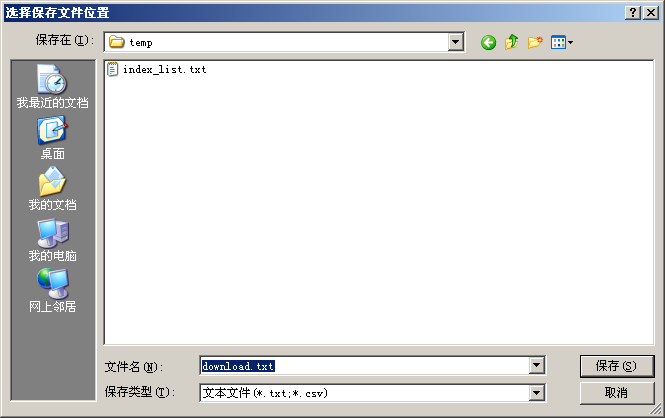
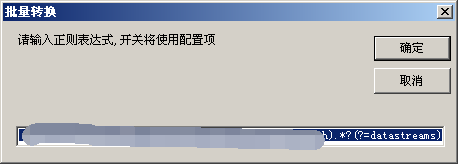

(为了演示,没有拿全部的71个文件)
现在打开刚刚生成的列表文件,将预留的”尾巴“替换成真实URL的前后部分。

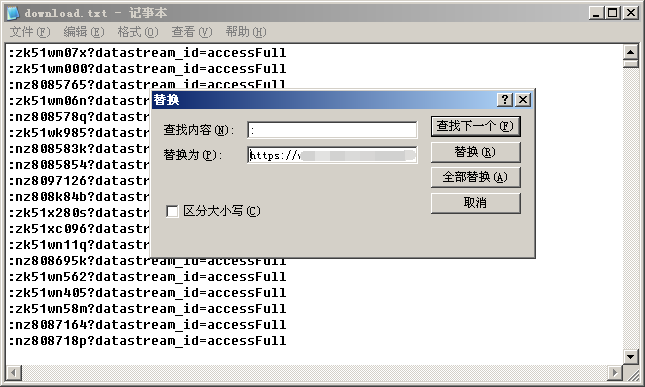
这样,我们就得到了干净的下载列表。

然后你就可以把这个列表拿到一个网速比较好的机器上,继续交给wget就OK了。
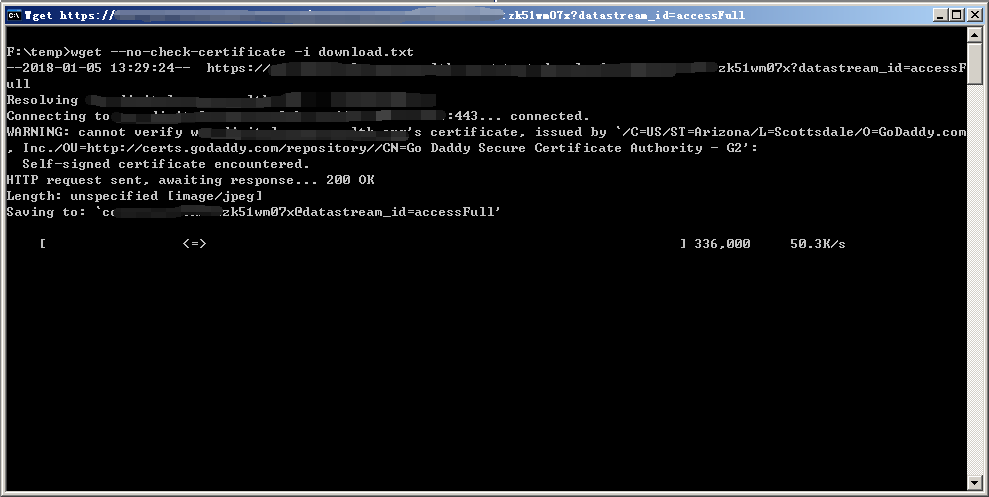
搞定,收工
其实严格来说,这个过程并不复杂。只是对常见工具和软件的灵活应用和组合。但这个思路我个人认为还是值得总结的。
现在很多工具都有提供列表导入以及命令行调用等多种使用方式,在利用它们处理某些具体事项的时候,完全可以用其他手段构造出列表甚至简单的脚本供这些工具调用,从而省去自己实现这些工具功能的工作,何乐不为呢?