栈(stack)
定义:
数据集合,只能在一端(首尾)进行删除和插入的列表。
特点:
后进先出(LIFO)
典型作用:
括号匹配:左括号进栈,右括号跟左括号对应则出栈,例如:(({{[]}}))匹配
队列(queue)
定义:
线性表,只能在表的一端进行插入,在另一端进行删除操作。
特点:
先进先出(FIFO)
栈和队列的比较:
1遍历速度方向:栈只能从头部取数据,如果要取第一个数据则需要遍历整个栈,队列则可以从头部或尾部遍历,但不能同时遍历
2遍历空间:栈遍历时需要另行开辟临时空间,保持数据在遍历前的一致性,队列则是基于地址指针进行遍历,无需临时空间则可保持一致性
3两者均是线性表,即数据元素之间的关系相同,但是由因为对插入和删除的限定条件,则成为有限定的线性表。
下面时对队列和栈的一个对比应用:迷宫(maze)
假设有这么一个迷宫地图:
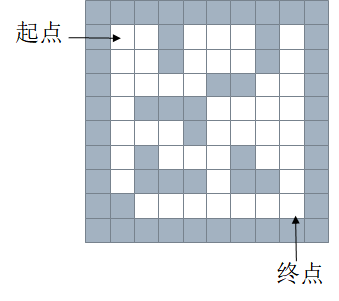
嘉定灰色为0,白色为1,用一个列表来表示为:
maze = [ [1,1,1,1,1,1,1,1,1,1], [1,0,0,1,0,0,0,1,0,1], [1,0,0,1,0,0,0,1,0,1], [1,0,0,0,0,1,1,0,0,1], [1,0,1,1,1,0,0,0,0,1], [1,0,0,0,1,0,0,0,0,1], [1,0,1,0,0,0,1,0,0,1], [1,0,1,1,1,0,1,1,0,1], [1,1,0,0,0,0,0,0,0,1], [1,1,1,1,1,1,1,1,1,1] ]
首先使用栈的方法,指定一个方向优先级,比如下,右,左,上的顺序,向栈中不断push数据,直到到达终点的位置为止。
定义四个方向
dirs = [lambda x, y: (x + 1, y), lambda x, y: (x, y + 1), lambda x, y: (x - 1, y), lambda x, y: (x, y - 1), ]
主程序:
def map_path(x1,y1,x2,y2): stack=[] stack.append((x1,y1))#添加起始点 while len(stack)> 0: #如果栈中有数据的话 curNode=stack[-1] #取最外面一个栈值 if curNode[0]==x2 and curNode[1]==y2: #如果到达终点 print('found path') for p in stack: print(p) return True for dir in dirs: #循环四个方向,注意优先级 nextNode=dir(curNode[0],curNode[1]) #定义下一个点 if maze[nextNode[0]][nextNode[1]]==0: #如果下一个点可以走通 stack.append(nextNode) #添加进栈中 maze[nextNode[0]][nextNode[1]] = -1 #改变值使不重复添加 break else: stack.pop() print('found failed') return False map_path(1,1,8,8)
最后的结果输出为:


found path (1, 1) (2, 1) (3, 1) (4, 1) (5, 1) (5, 2) (5, 3) (6, 3) (6, 4) (6, 5) (7, 5) (8, 5) (8, 6) (8, 7) (8, 8)
在这里注意到如果更改dir的顺序,即可调整走出迷宫的优先级,路径就会不一样,我在这里只能根据相对位置(左下方)进行一个寻位的排序。如果有大神知道如何在此基础上能找到绝对的最有路径,还望赐教。
讲完了栈,下面使用队列来实现同样的功能:
def print_p(path): curNode = path[-1] #包含了所有的路径 realpath=[] #只记录走到终点的真实路径 while curNode[2]!=-1: #只要不是第一个 realpath.append(curNode[0:2]) curNode=path[curNode[2]] #继续找下一个 realpath.append(curNode[0:2]) #拿到最后一个源头 realpath.reverse() print(realpath) def map_path(x1,y1,x2,y2): queue = deque() path=[] #创建列表记录路径 queue.append((x1,y1,-1)) #-1是设置用于路径来源搜搜索 while len(queue)>0: curNode=queue.popleft() path.append(curNode) if curNode[0]==x2 and curNode[1]==y2: print_p(path) return True for dir in dirs: nextNode = dir(curNode[0],curNode[1]) if maze[nextNode[0]][nextNode[1]]==0: #如果找到有空 queue.append((*nextNode,len(path)-1)) #len用于记录产生这个新node的来源 maze[nextNode[0]][nextNode[1]] = -1 #如果没有空 print('found failed') return False map_path(1,1,8,8)
最后结果为:
[(1, 1), (2, 1), (3, 1), (4, 1), (5, 1), (5, 2), (5, 3), (6, 3), (6, 4), (6, 5), (7, 5), (8, 5), (8, 6), (8, 7), (8, 8)]
根据两种不同的方法实现迷宫的解答凸显了两种查找方式:深度查找和广度查找,栈体现的就是深度,一直到底然后再返回查询,队列则体现的是广度查找,把每个点的可能性都列出来,然后找到最后一个可以到达重点的,再通过反向溯源找到路径。