原文地址:http://www.cnblogs.com/lzb1096101803/p/4907775.html
一、学会如何读一个JavaWeb项目源代码
步骤:表结构->web.xml->mvc->db->spring ioc->log->代码
-
先了解项目数据库的表结构,这个方面是最容易忘记的,有时候我们只顾着看每一个方法是怎么进行的,却没有去了解数据库之间的主外键关联。其实如果先了解数据库表结构,再去看一个方法的实现会更加容易。
-
然后需要过一遍web.xml,知道项目中用到了什么拦截器,监听器,过滤器,拥有哪些配置文件。如果是拦截器,一般负责过滤请求,进行AOP等;如果是监听器,可能是定时任务,初始化任务;配置文件有如 使用了spring后的读取mvc相关,db相关,service相关,aop相关的文件。
-
查看拦截器,监听器代码,知道拦截了什么请求,这个类完成了怎样的工作。有的人就是因为缺少了这一步,自己写了一个action,配置文件也没有写错,但是却怎么调试也无法进入这个action,直到别人告诉他,请求被拦截了。
-
接下来,看配置文件,首先一定是mvc相关的,如springmvc中,要请求哪些请求是静态资源,使用了哪些view策略,controller注解放在哪个包下等。然后是db相关配置文件,看使用了什么数据库,使用了什么orm框架,是否开启了二级缓存,使用哪种产品作为二级缓存,事务管理的处理,需要扫描的实体类放在什么位置。最后是spring核心的ioc功能相关的配置文件,知道接口与具体类的注入大致是怎样的。当然还有一些如apectj等的配置文件,也是在这个步骤中完成
-
log相关文件,日志的各个级别是如何处理的,在哪些地方使用了log记录日志
-
从上面几点后知道了整个开源项目的整体框架,阅读每个方法就不再那么难了。
-
当然如果有项目配套的开发文档也是要阅读的。


二、爬虫是如何实现的:
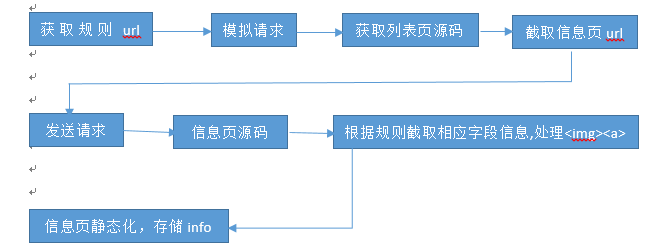
获取规则url(正则表达式) -> 模拟请求(如httpclient get请求)-> 获取列表页html -> 获取信息页 -> 发送请求 -> 信息页html -> 根据规则截取相应的字段信息 -> 对字段进行清理(如图片压缩) -> 静态化(存储到数据库)
三、架构文档
开发项目是需要学会写架构文档,而不是只是做一个码农
包含以下内容:
- 模块分级,各模块关系,各模块负责人
- 各模块时序图
- 各模块表结构
- 协议文档(接口文档)
- 每个负责人工作计划
下发任务后每个模块的负责人用开发工具画出自己的时序图,表结构和接口文档,最后汇总到总项目负责人处。

四、其它
-
数据库是否分表问题:用分表的方式管理表有时并不合理,如果读的压力高是不值得的,可能更慢。如果写并发高就行(以千万级别为准)。 读是按缓存的,缓存密度在95%以上是比较保险的。读的优化:读单条信息,只需搜到这个id,然后直接从缓存中拿,缓存用id做缓存,查id的效率是很高的
-
CMS=模板+数据:可以通过只有一套自己的模板(如用freemarker),发送请求获取json数据填入信息。CMS有模板通过把数据填入模板即形成一个网页。
-
计算机浏览器的网页内容要在手机上查看,需要做到响应式HTML
-
如通过抓取网页内容放到app上显示,需要做的内容:图片大小自适应,内容尽量保真,校验内容是否丢失,链接需要替换的需要进行替换,html标签替换
-
爬虫的核心是多线程的任务管理,抓取分页列表内容。
-
微信公众号上是如何绑定用户让用户只登录一次,下次不用登陆?这个过几天补充。