1.理论
https://zhuanlan.zhihu.com/p/25928551
关键是你要总结住啊。任何技术都有它关键的点,创新点吧或者有效点,这点你要知道你要掌握。
2.论文《Bag of Tricks for Efficient Text Classification》
概览:模型直接学习句子的表示,我们表明,通过合并其他统计信息(例如使用n-gram袋),我们可以减小线性模型与深度模型之间的准确性差距,而数量级的速度更快。

将句子中的词向量取均值,然后softmax得到句子的label进行文本分类,这样虽然没有考虑词序,说明句子和句意之间也许没有那么复杂的非线性关系。
上图中所示的是d维的一层隐层结构,那hidden里到底是什么结构呢???论文中有提到它has 10 hidden units,也就是10个神经元的意思吧,hidden也取了50和200。
3.fasttext官方教程学习
https://fasttext.cc/docs/en/supervised-tutorial.html,我觉得还是能从这里学到很多内容的!
但是这个它的底层使用C写的,所以就很快,然后很难看懂啊!
总体的意思是说不必要进行那么多的非线性转换。
4.层次softmax
https://arxiv.org/pdf/1411.2738.pdf,这是原论文讲解softmax的推理过程,https://blog.csdn.net/imsuhxz/article/details/82115681,给出了精简的过程。

叶子节点是单词V,非叶子节点有V-1,是为了计算叶子结点的概率。
这是一颗哈夫曼树,也就是最小权重编码二叉树,从根往左走或者往右走的概率,

目标词w的概率为:
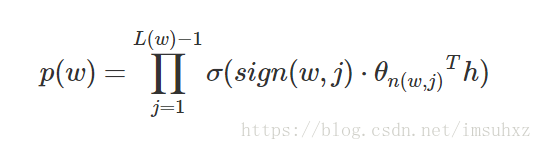
所有叶子节点的p的和为1.
那么对于fasttext来说,对于文本分类任务,它的叶子节点是类别,而不是词向量中的vocab。下面是theta的更新公式:

//我还不太明白这里θ具体计算时是什么内容,论文中是像下面这么说的,是内部节点的向量表示,
![]()
博客中提到:“在层次Softmax模型中,叶子节点的词没有直接输出的向量,而非叶子节点其实都有响应的输出向量。”也就是内部节点都有输出向量,而它的更新公式上面也已经给出了,明白了。对于上面的h,论文中这么说:
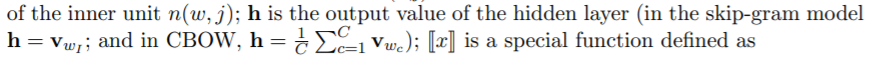
如果对于skip-gram,它是通过当前词预测上下文,那么已知的h就是当前词的词向量;如果对于CBOW,以上下文来预测当前词,那么已知的就是上下文单词的词向量,通过它们来预测当前词。(似乎有一点明白了,但让我写公式我还是会卡壳。)
http://qiancy.com/2016/08/17/word2vec-hierarchical-softmax/
5.关于实现
https://zhuanlan.zhihu.com/p/32965521,这篇讲的也非常好。(点醒了我一直想不通的hidden层。)
下面是给出来的简版实现:
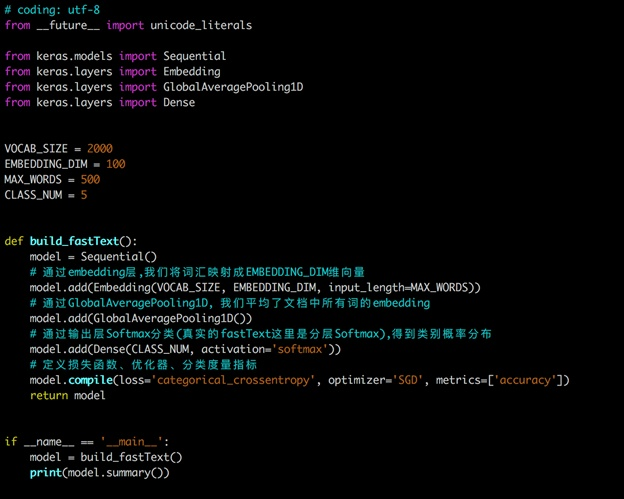
可以看到它经过了平均池化之后,也就是所有词的词向量相+,然后平均,(其实就是非常地简单啊),之后就是一个激活函数为softmax的Dense层,
https://www.jianshu.com/p/ccb5b6bee75d,Dense层就是全连接层,给出输入维度,输出class_num。
6.n-gram优点
它涉及到的n-gram就更好理解了。增大了词汇表的量,而且使用的是字符集别的n-gram这样就缓解了oov的问题。
https://blog.csdn.net/feilong_csdn/article/details/88655927:

主要的点:①为少见单词生成更好的词向量,因为它可以通过字符来生成;②缓解oov问题;③可以考虑局部单词的顺序问题,如果是unigram那么就捕获不到顺序信息,即上下文信息。
7.多标签
我认为教程里表述的是:依旧使用softmax设置不同的阈值来选择预测多标签;另一种方便的方法是对每个label都训练一个二分类器。
5-6日更新————————
关于多标签这里提到了 多标签二分类:https://blog.csdn.net/tsyccnh/article/details/79163834
多标签时,标签之间不用softmax计算,和不为1,因为它们之间是独立分布的,每个标签都可以视为一个二项分布,
针对每一个类单独计算交叉熵损失, 然后对不同标签的相加。
5-10更新——
1.fasttext所需文件格式
所给的教程中的文件格式:

没有header,列用空格分隔的。
并且后缀是txt的,说明不是csv的?那么我还是严格按照它的格式来做训练数据吧。
fasttext真是又快效率也不错!
https://fasttext.cc/docs/en/supervised-tutorial.html,官方教程,
https://zhuanlan.zhihu.com/p/66739066,这个知乎例子也很好,学到了。