https://blog.csdn.net/tg229dvt5i93mxaq5a6u/article/details/78422216,这篇讲的非常好,解决了我的好多疑问。
1.机器翻译中计算权重和概率
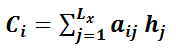
其中aij是通过si-1和hj计算得到的,也就相当于qk,那么上式中的hj也就是v,在这里k=v的。这厮soft 注意力,相当于一个软寻址的过程,硬寻址只从存储内容里面找出一条内容,而软是尽可能从每个Key地址都会取出内容,取出内容的重要性根据Query和Key的相似性来决定,之后对Value进行加权求和。
2.Attention机制本质思想
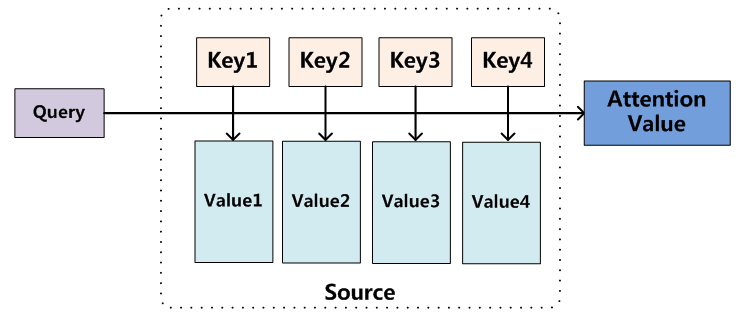
其中source在机器翻译中就是源语言。首先是根据q和k计算权重,然后再和v加权求和获取到概率分布。
第一步中相似性的计算可以通过:

之后经过softmax归一化,转换为权重和为1的概率分布,
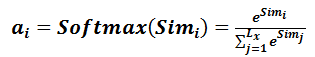
下面是加权求和:
由上图我们可以知道,在transformer的encoder中,qkv来源都相同的,而在解码中,q是来自前一个预测的word,kv来自编码的输出!
3.self-attention机制
自注意力是source=target,那么问题来了,在机器翻译这样source≠target中,attention模拟的是翻译中的对齐过程,那么source=target的物理意义是什么呢?
答:它可以学习到句子单词之间的句法特征和语义特征,比如远距离的一些单词的指代关系,如果实在RNN或LSTM中远距离的信息被捕获的可能性就相对小。
Self Attention在计算过程中会直接将句子中任意两个单词的联系通过一个计算步骤直接联系起来,所以远距离依赖特征之间的距离被极大缩短,有利于有效地利用这些特征。除此外,Self Attention对于增加计算的并行性也有直接帮助作用。
4.应用
除了在机器翻译中,还有图片转换为文字及语音转换为文字中,都可以建立起target和source的注意力关系。