转自:https://towardsdatascience.com/avoid-data-leakage-split-your-data-before-processing-a7f172632b00
https://towardsdatascience.com/data-splitting-for-model-evaluation-d9545cd04a99
1.数据泄露
数据泄漏是指训练数据集和测试数据集之间偶然的信息共享。 这种信息共享将给模型一个关于测试数据集的“提示”,并生成看起来最优的评估分数。 然而,由于模型对测试数据拟合过度,无法准确预测未来未见数据集。
一个比较常见的数据泄露的原因:在数据预处理后才进行训练-测试集的划分。
2.例子
给出由于在数据预处理后才进行训练-测试集的划分,导致数据泄露给测试集的问题。
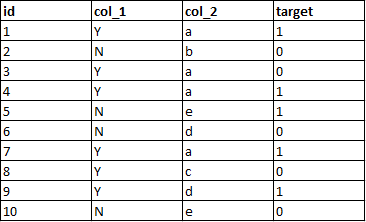
针对上述训练集,由列1和列2预测target, 如果先对列进行预处理:
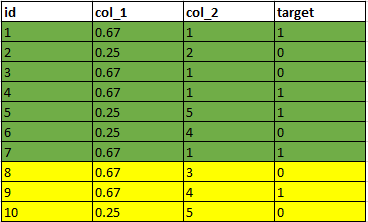
列1中Y的值是通过其中有多少个为1的target来替换,即4/6=0.67;列2是按字母顺序编码。
将前7个样本作为训练集,后3个作为测试集,但是从测试集中来看,它能够期望,2个Y,并且其中有一个target为1,这将导致对模型性能的期望过于乐观。
类似地,对于步骤2,第5行的字母' e '被编码为5,因为它理解完整数据集有' a ', ' b ', ' c '和' d '。 这种信息也会在训练和测试数据之间泄露。
2.1解决办法
在预处理之前将数据集划分,这样test集以及未见过的数据都会一视同仁地被处理。
先划分: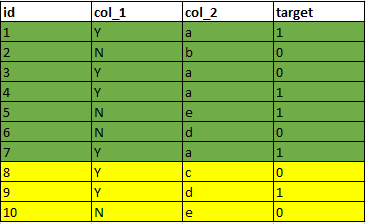
再预处理:

这样做的好处是:
- 降低数据泄露风险
- 未来看不见的数据将以与测试数据完全相同的方式处理,从而确保模型性能的一致性。
3.随机划分数据集存在的问题
3.1 不平衡数据集
如果我们随机分割一个包含99%负类和1%正类的数据集,会出现什么问题?
可以通过scikit-learn’s train_test_split()进行分层采样。
3.2 小数据集(有限的数据集)
使用k折交叉验证。

3.3 特征工程泄露
也就是上述提到的例子。
3.4 组泄露Group Leakage
主要是针对train和test中有同个人的样本overlap的情况。
3.5 时序泄露

比如在预测出售的房价时,如果针对数据集随即划分,那么就忽略了时间的因素,可能会导致模型表现比期望更好。