上篇已经介绍了 图片的爬取,后来觉得不太好,每次爬取的图片 都在一个文件下,不方便区分,且数据库中没有爬取的时间标识,不方便后续查看 数据时何时爬取的,所以这里进行了局部修改
修改一:修改爬虫执行方式
之前爬虫的执行 是通过在终端输入命令:scrapy crawl spiderName 执行
缺点:
1、需要记住并输入命令;
2、需要在终端切换到爬虫上一级目录下执行。
创建执行入口
如图
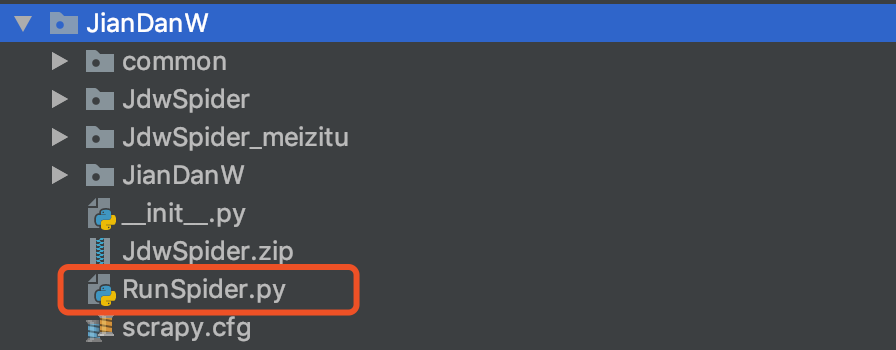
代码如下
# FileName : RunSpider.py # Author : Adil # DateTime : 2018/12/4 2:51 PM # SoftWare : PyCharm from scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings process = CrawlerProcess(get_project_settings()) # 此处添加 执行爬虫 名字,具体可以查看 源码 process.crawl('JdwSpider') process.start()
修改二:修改图片存放路径
之前是在执行路径下依照spiderName 创建了一个文件夹,用来存放图片。
缺点:
1、每次执行爬虫所有图片都会存放在该文件下,日积月累,图片会越来越多,不方便查找和归类
创建新的文件路径
根据爬取日期创建文件进而分类,方便查看不同时间对应的爬取结果
展示结果如下:

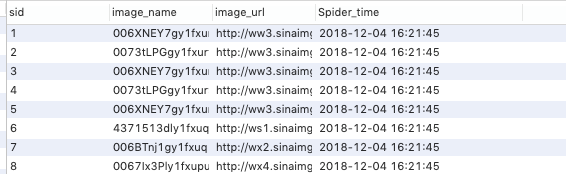
修改三:数据增加爬取时间
如图,方便以爬取时间进行区分爬取内容。
最后修改后代码如下:
# -*- coding: utf-8 -*- # Define your item pipelines here # # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html import os import urllib import time import common.DBHandle as DBHandle class JiandanwPipeline(object): def __init__(self): ''' 初始化文件路径及 爬取时间 ''' # 获取当前路径 currentPath = os.getcwd() # 拼接图片存放路径 file_path = os.path.join(currentPath, 'JdwSpider') # 增加 按日期创建文件 localTime = time.localtime(time.time()) localTimeStrs = time.strftime("%Y-%m-%d %H:%M:%S", localTime) # 再次拼接路径 file_path = os.path.join(file_path, localTimeStrs) if not os.path.exists(file_path): os.makedirs(file_path) # 初始化 两个 变量,方便 后面的 方法使用 self.file_path = file_path self.localTimeStrs = localTimeStrs # 数据库连接 这里的 数据库信息,因为是本地数据库,后面如果是公司数据库 不方便透露的话,可以存放到配置文件中 host = '127.0.0.1' username = 'adil' password = 'helloyyj' database = 'AdilTest' port = 3306 # 实例化 数据库 连接 self.DbHandle = DBHandle.DataBaseHandle(host, username, password, database, port) def process_item(self, item, spider): ''' 爬虫文件数据处理函数 ''' # 这里是一页 算一个 item ,所以如果 将 文件信息 写在这里,会导致一页创建一次,所以 放在初始化函数内进行 # # 获取当前路径 # currentPath = os.getcwd() # # 拼接图片存放路径 # file_path = os.path.join(currentPath, spider.name) # # # 增加 按日期创建文件 # localTime = time.localtime(time.time()) # localTimeStrs = time.strftime("%Y-%m-%d %H:%M:%S", localTime) # # 再次拼接路径 # file_path = os.path.join(file_path, localTimeStrs) # # if not os.path.exists(file_path): # os.makedirs(file_path) for image_url in item['image_urls']: # 截图图片链接 list_name = image_url.split('/') # 获取图片名称 file_name = list_name[len(list_name) - 1] # 图片名称 # 补全图片路径 path_name = os.path.join(self.file_path,file_name) # 获取有效的url 因为 image_url = //wx4.sinaimg.cn/mw600/66b3de17gy1fxo6jis4iej21ma0u0x6r.jpg image_url = 'http:' + image_url # 此处执行 数据库插入,将 图片名称、url 插入到数据库 注意 这里的 values('占位符 一定要用 引号引起来,要不然执行不成功,血的教训') sql = "insert into JdwSpider(image_name,image_url,Spider_time) values ('%s','%s','%s')" % (file_name,image_url,self.localTimeStrs) # 如果不执行插入,可以注释改该行代码 self.DbHandle.insertDB(sql) # 图片保存 with open(path_name, 'wb') as file_writer: conn = urllib.request.urlopen(image_url) # 下载图片 # 保存图片 file_writer.write(conn.read()) file_writer.close() return item def close_spider(self,spider): ''' 定义爬虫结束处理函数 此处会在 爬虫结束后执行该方法 ''' # 关闭数据库, print('****'*50) print('数据库关闭') self.DbHandle.closeDb()