类别不平衡问题指分类任务中不同类别的训练样本数目差别很大的情况。一般来说,不平衡样本会导致训练模型侧重样本数目较多的类别,而“轻视”样本数目较少类别,这样模型在测试数据上的泛化能力就会受到影响。一个例子,训练集中有99个正例样本,1个负例样本。在不考虑样本不平衡的很多情况下,学习算法会使分类器放弃负例预测,因为把所有样本都分为正便可获得高达99%的训练分类准确率。
下面将从“数据层面“和”算法层面“两个方面介绍不平衡样本问题。
数据层面处理办法
数据层面处理方法多借助数据采样法使整体训练集样本趋于平衡,即各类样本数基本一致。
1、欠采样
即去除多余的样本,使得正负样本数目基本一致。
注意:(1)由于丢弃了一些样本,训练速度相对加快了。
(2)但是简单的随机丢失样本,会造成信息丢失。欠采样的代表算法是EasyEnsemble,是利用集成学习机制,将数目多的一类划分成若干个集合供不同学习器使用,这样虽然对每个学习器丢失了一部分信息,但全局上看不会丢失重要信息。
2、过采样
即增加少的一类的样本数目,使得正负样本数目基本一致。
注意:(1)由于多了一些样本,训练速度相对减慢了。
(2)但是简单的重采样会带来严重的过拟合,过采样的代表性算法是SMOTE,是通过对少的一类进行插值得到额外的样本。
3、类别均衡采样
把样本按类别分组,每个类别生成一个样本列表,训练过程中先随机选择1个或几个类别,然后从各个类别所对应的样本列表里选择随机样本。这样可以保证每个类别参与训练的机会比较均等。
上述方法需要对于样本类别较多任务首先定义与类别相等数量的列表,对于海量类别任务如ImageNet数据集等此举极其繁琐。海康威视研究院提出类别重组的平衡方法。
类别重组法只需要原始图像列表即可完成同样的均匀采样任务,步骤如下:
首先按照类别顺序对原始样本进行排序,之后计算每个类别的样本数目,并记录样本最多那个类的样本数目。之后,根据这个最多样本数对每类样本产生一个随机排列的列表, 然后用此列表中的随机数对各自类别的样本数取余,得到对应的索引值。接着,根据索引从该类的图像中提取图像,生成该类的图像随机列表。之后将所有类的随机列表连在一起随机打乱次序,即可得到最终的图像列表,可以发现最终列表中每类样本数目均等。根据此列表训练模型,在训练时列表遍历完毕,则重头再做一遍上述操作即可进行第二轮训练,如此往复。 类别重组法的优点在于,只需要原始图像列表,且所有操作均在内存中在线完成,易于实现。

4、阈值移动
阈值移动主要是用到“再缩放”的思想,以线性模型为例介绍“再缩放”。
我们把大于0.5判为正类,小于0.5判为负类,即

即令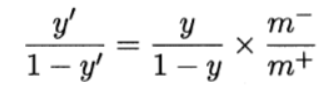 然后代入上上式。这就是“再缩放”。
然后代入上上式。这就是“再缩放”。
阈值移动方法是使用原始训练集训练好分类器,而在预测时加入再缩放的思想,用来缓解类别不平衡的方法。
算法层面的处理方法
对于不平衡样本导致样本数目较少的类别”欠学习“这一现象,一个很自然的解决办法是增加小样本错分的惩罚代价,并将此代价直接体现在目标函数里。这就是代价敏感的方法,这样就可以通过优化目标函数调整模型在小样本上的注意力。算法层面处理不平衡样本问题的方法也多从代价敏感的角度出发。
1、带权重的softmaxLoss
在样本不均衡分类问题中,样本量大的类别往往会主导训练过程,因为其累积loss会比较大。带权重的softmaxloss函数通过加权来决定主导训练的类别。具体为增加pos_mult(指定某类的权重乘子)和pos_cid(指定的某类的类别编号)两个参数来确定类别和当前类别的系数。(若pos_mult=0.5,就表示当然类别重要度减半)。
2、OHEMLoss
OHEM被称为难例挖掘,针对模型训练过程中导致损失值很大的一些样本(即使模型很大概率分类错误的样本),重新训练它们.维护一个错误分类样本池, 把每个batch训练数据中的出错率很大的样本放入该样本池中,当积累到一个batch以后,将这些样本放回网络重新训练。通俗的讲OHEM就是加强loss大样本的训练。
3、focalLoss
A. 总述
Focal loss主要是为了解决one-stage目标检测中正负样本比例严重失衡的问题。该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。
B. 损失函数形式
Focal loss是在交叉熵损失函数基础上进行的修改,首先回顾二分类交叉上损失:
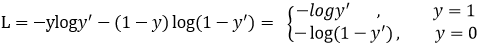
 是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。那么Focal loss是怎么改进的呢?
是经过激活函数的输出,所以在0-1之间。可见普通的交叉熵对于正样本而言,输出概率越大损失越小。对于负样本而言,输出概率越小则损失越小。此时的损失函数在大量简单样本的迭代过程中比较缓慢且可能无法优化至最优。那么Focal loss是怎么改进的呢?

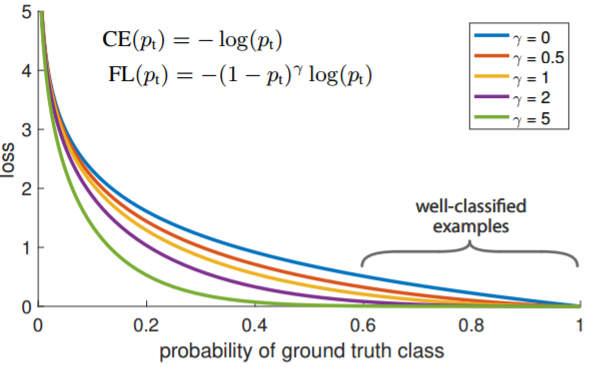
首先在原有的基础上加了一个因子,其中gamma>0使得减少易分类样本的损失。使得更关注于困难的、错分的样本。
例如gamma为2,对于正类样本而言,预测结果为0.95肯定是简单样本,所以(1-0.95)的gamma次方就会很小,这时损失函数值就变得更小。而预测概率为0.3的样本其损失相对很大。对于负类样本而言同样,预测0.1的结果应当远比预测0.7的样本损失值要小得多。对于预测概率为0.5时,损失只减少了0.25倍,所以更加关注于这种难以区分的样本。这样减少了简单样本的影响,大量预测概率很小的样本叠加起来后的效应才可能比较有效。
此外,加入平衡因子alpha,用来平衡正负样本本身的比例不均:
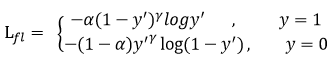
只添加alpha虽然可以平衡正负样本的重要性,但是无法解决简单与困难样本的问题。
lambda调节简单样本权重降低的速率,当lambda为0时即为交叉熵损失函数,当lambda增加时,调整因子的影响也在增加。实验发现lambda为2是最优。
C. 总结
作者认为one-stage和two-stage的表现差异主要原因是大量前景背景类别不平衡导致。作者设计了一个简单密集型网络RetinaNet来训练在保证速度的同时达到了精度最优。在双阶段算法中,在候选框阶段,通过得分和nms筛选过滤掉了大量的负样本,然后在分类回归阶段又固定了正负样本比例,或者通过OHEM在线困难挖掘使得前景和背景相对平衡。而one-stage阶段需要产生约100k的候选位置,虽然有类似的采样,但是训练仍然被大量负样本所主导。
参考文献:
https://blog.csdn.net/siyue0211/article/details/80318999
https://blog.csdn.net/qiu931110/article/details/86560974
https://www.cnblogs.com/king-lps/p/9497836.html