一、疑问
二、知识点
1. 损失函数可视化
损失函数一般都是定义在高维度的空间中,这样要将其可视化就很困难。然而办法还是有的,在1个维度或者2个维度的方向上对高维空间进行切片,例如,随机生成一个权重矩阵,该矩阵就与高维空间中的一个点对应。然后沿着某个维度方向前进的同时记录损失函数值的变化。换句话说,就是生成一个随机的方向
并且沿着此方向计算损失值,计算方法是根据不同的
值来计算
。这个过程将生成一个图表,其x轴是
值,y轴是损失函数值。同样的方法还可以用在两个维度上,通过改变
来计算损失值
,从而给出二维的图像。在图像中,
可以分别用x和y轴表示,而损失函数的值可以用颜色变化表示:
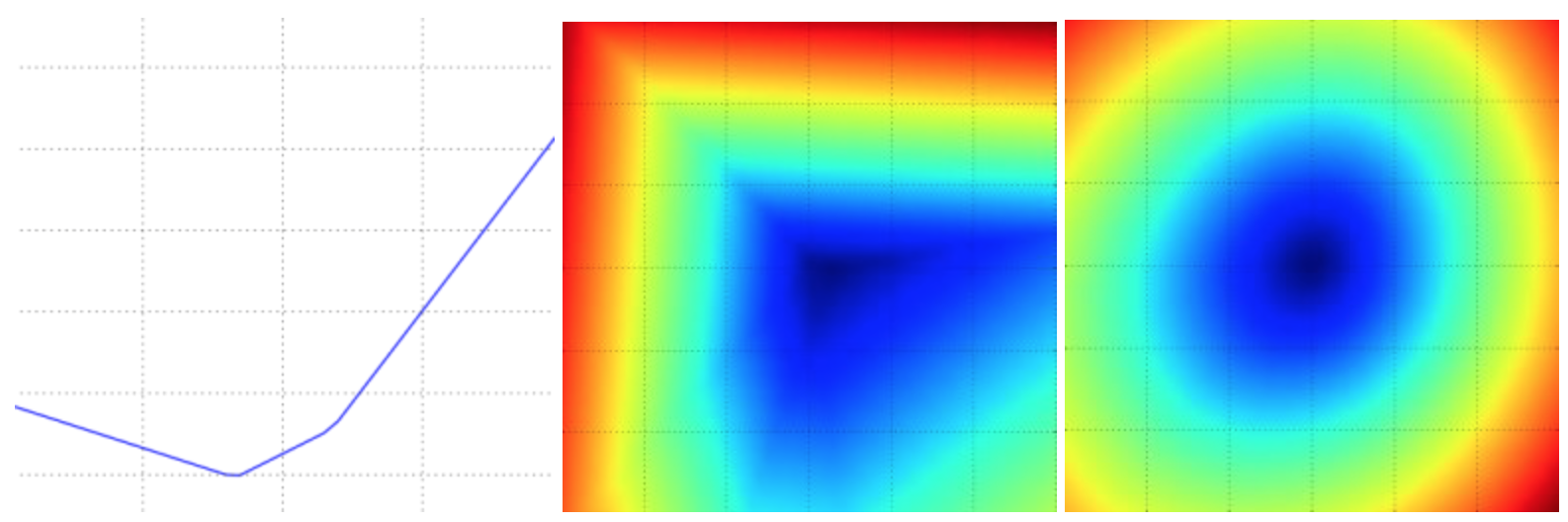
- 过低的学习率导致算法的改善是线性的。高一些的学习率会看起来呈几何指数下降,更高的学习率会让损失值很快下降,但是接着就停在一个不好的损失值上(绿线)。这是因为最优化的“能量”太大,参数在混沌中随机震荡,不能最优化到一个很好的点上。
- 损失值的震荡程度和批尺寸(batch size)有关,当批尺寸为1,震荡会相对较大。当批尺寸就是整个数据集时震荡就会最小,因为每个梯度更新都是单调地优化损失函数(除非学习率设置得过高)。
2. 梯度检查
- 使用中心化公式。 用泰勒展开式,该公式的误差近似(O(h^2))。
-
使用相对误差比较数值梯度和解析梯度的不同。若使用绝对值进行比较:当差值为1e-4,若梯度值在1.0左右,则差值较为合适;若梯度值为1e-5或更低时,则1e-4为非常大的差距,梯度实现就会被当成失败的。
-
在实践中:
相对误差>1e-2:通常就意味着梯度可能出错。
1e-2>相对误差>1e-4:要对这个值感到不舒服才行。
1e-4>相对误差:这个值的相对误差对于有不可导点的目标函数是OK的。但如果目标函数中没有kink(使用tanh和softmax),那么相对误差值还是太高。
1e-7或者更小:结果很好。
-
使用双精度。
-
目标函数的不可导点。例如在ReLU或SVM损失中,由于max函数的使用,导致某些数据在x = 0时为不可导点。这会使得解析梯度和数值梯度的计算结果出现一定的差距。
-
谨慎设置步长h。在实践中h并不是越小越好,因为当
特别小的时候,就可能就会遇到数值精度问题。有时候如果梯度检查无法进行,可以试试将
-
在操作的特性模式中梯度检查。梯度检查是在参数空间中的一个特定(往往还是随机的)的单独点进行的。即使是在该点上梯度检查成功了,也不能马上确保全局上梯度的实现都是正确的。因此为了安全起见,最好让网络学习(“预热”)一小段时间,等到损失函数开始下降的之后再进行梯度检查。在第一次迭代就进行梯度检查的危险就在于,此时可能正处在不正常的边界情况,从而掩盖了梯度没有正确实现的事实。
-
不要让正则化吞没数据。 正则化损失可能吞没掉数据损失,在这种情况下梯度主要来源于正则化部分(正则化部分的梯度表达式通常简单很多)。这样就会掩盖掉数据损失梯度的不正确实现。因此,推荐先关掉正则化对数据损失做单独检查,然后对正则化做单独检查。
-
关闭随机失活(dropout)和数据扩张(augmentation)。
-
检查少量的维度。在实际中,梯度可以有上百万的参数,在这种情况下只能检查其中一些维度然后假设其他维度是正确的。
3. 合理性检查的提示与技巧
- 寻找特定情况的正确损失值。在使用小参数进行初始化时,确保得到的损失值与期望一致。最好先单独检查数据损失(让正则化强度为0)。例如,对于Softmax分类器,一般期望它的初始损失值是2.302;对于SVM,假期望损失值是9(因为对于每个错误分类,边界值是1)。
- 提高正则化强度时导致损失值变大。
- 对小数据子集过拟合。最后也是最重要的一步,在整个数据集进行训练之前,尝试在一个很小的数据集上进行训练(比如20个数据),然后确保能到达0的损失值。进行这个实验的时候,最好让正则化强度为0,不然正则化会阻止让损失为0。
4. 权重更新比例
权重中更新值的数量和全部值的数量之间的比例应该在1e-3左右。如果更低,说明学习率可能太小,如果更高,说明学习率可能太高。
5. 可视化
如果数据是图像像素数据,那么把第一层特征可视化会有帮助:
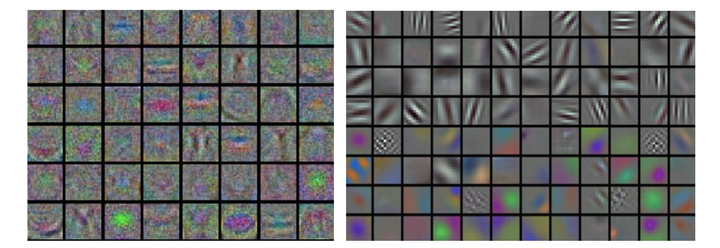
左图中的特征充满了噪音,这暗示了网络可能出现了问题:网络没有收敛,学习率设置不恰当,正则化惩罚的权重过低。右图的特征不错,平滑,干净而且种类繁多,说明训练过程进行良好。
6. 局部最小值
在使用梯度下降等方法更新权重参数的时候,有时候参数可能会收敛于局部最小值。在小的神经网络中,不同的局部最小值对于模型的影响确实很大,但是在大的神经网络中,随着时间的推移,最优的局部最小值和最差的局部最小值之间的差异会越来愈小。因此在大的神经网络中,通常认为收练的局部最小值等同于全局最小值。
7. 学习率的选择以及退火
在开始阶段,应选择较高的lr,这样loss就会较快得下降。但是下降到某一节点之后可能无法达到最小值,此时需要降低lr,以用更低的学校效率到达最低的loss点。
- 随步数衰减:每进行几个周期就根据一些因素降低学习率。典型的值是每过5个周期就将学习率减少一半,或者每20个周期减少到之前的0.1。这些数值的设定是严重依赖具体问题和模型的选择的。在实践中可能看见这么一种经验做法:使用一个固定的学习率来进行训练的同时观察验证集错误率,每当验证集错误率停止下降,就乘以一个常数(比如0.5)来降低学习率。
- 指数衰减。数学公式是
,其中
是超参数,
是迭代次数(也可以使用周期作为单位)。
- 1/t衰减的数学公式是
,其中
在实践中,发现随步数衰减的随机失活更受欢迎,因为它使用的超参数(衰减系数和以周期为时间单位的步数)比更有解释性。最后,如果有足够的计算资源,可以让衰减更加缓慢一些,让训练时间更长些。
三. 参数更新规则
1. SGD
沿着负梯度方向改变参数(因为梯度指向的是上升方向,但是我们通常希望最小化损失函数)。假设有一个参数向量x及其梯度dx,那么最简单的更新的形式是:
# 普通更新
x += - learning_rate * dx
其中learning_rate是一个超参数,它是一个固定的常量。当在整个数据集上进行计算时,只要学习率足够低,总是能在损失函数上得到非负的进展。
2. Momentum
如果把梯度下降法想象成一个小球从山坡到山谷的过程,那么前面几篇文章的小球是这样移动的:从A点开始,计算当前A点的坡度,沿着坡度最大的方向走一段路,停下到B。在B点再看一看周围坡度最大的地方,沿着这个坡度方向走一段路,再停下。确切的来说,这并不像一个球,更像是一个正在下山的盲人,每走一步都要停下来,用拐杖来来探探四周的路,再走一步停下来,周而复始,直到走到山谷。而一个真正的小球要比这聪明多了,从A点滚动到B点的时候,小球带有一定的初速度,在当前初速度下继续加速下降,小球会越滚越快,更快的奔向谷底。momentum 动量法就是模拟这一过程来加速神经网络的优化的。
# 动量更新
v = mu * v - learning_rate * dx # 与速度融合
x += v # 与位置融合
A为起始点,首先计算A点的梯度∇a ,然后下降到B点, 到了B点需要加上A点的梯度,这里梯度需要有一个衰减值 ,推荐取0.9。这样的做法可以让早期的梯度对当前梯度的影响越来越小,如果没有衰减值,模型往往会震荡难以收敛,甚至发散。这样一步一步下去,带着初速度的小球就会极速的奔向谷底。

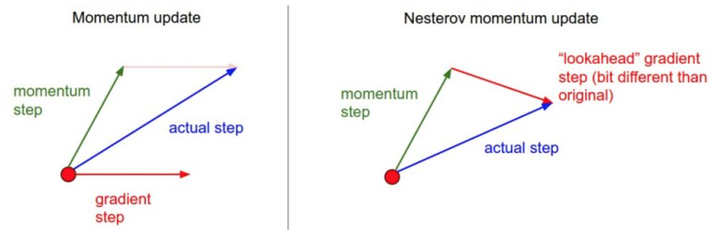
3. Nesterov
动量法每下降一步都是由前面下降方向的一个累积和当前点的梯度方向组合而成。于是一位大神就开始思考,既然每一步都要将两个梯度方向(历史梯度、当前梯度)做一个合并再下降,那为什么不先按照历史梯度往前走那么一小步,按照前面一小步位置的“超前梯度”来做梯度合并呢?如此一来,小球就可以先不管三七二十一先往前走一步,在靠前一点的位置看到梯度,然后按照那个位置再来修正这一步的梯度方向。如此一来,有了超前的眼光,小球就会更加”聪明“, 这种方法被命名为Nesterov accelerated gradient 简称 NAG。
x_ahead = x + mu * v
# 计算dx_ahead(在x_ahead处的梯度,而不是在x处的梯度)
v = mu * v - learning_rate * dx_ahead
x += v
v_prev = v # 存储备份
v = mu * v - learning_rate * dx # 速度更新保持不变
x += -mu * v_prev + (1 + mu) * v # 位置更新变了形式

4. Adagrad
随着算法不断的迭代,cache会越来越大,整体的学习率会越来越小。所以一般来说adagrad算法一开始是激励收敛,到了后面就慢慢变成惩罚收敛,速度越来越慢。Adagrad的一个缺点是,在深度学习中学习率总是单调减小,被证明通常过于激进且过早停止学习。
# 假设有梯度和参数向量x
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
- cache表示前t步梯度dx的累加;
- 用于平滑的式子eps(一般设为1e-4到1e-8之间)是防止出现除以0的情况;
- 平方根的操作非常重要,如果去掉,算法的表现将会糟糕很多;
- cache的累加为梯度的平方,是因为接下去要进行平方根操作,以防平方根内出现负数。
5. RMSprop
RMSprop用一种很简单的方式修改了Adagrad方法,让它不那么激进,单调地降低了学习率。具体说来,就是它使用了一个梯度平方的滑动平均:
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
decay_rate是一个超参数,通常取值为[0.9, 099, 0,999]。RMSpro和Adagrad主要的区别是在于cache的更新方式,可以将其拆为两个部分:其中0.9部分取决于之前的梯度和,剩下0.1部分取决于当前的梯度。如果当前梯度很大,学习率衰减得就会很快;如果当前梯度小,学习率衰减得就会慢点。利用这个特性,有效得解决了Adagrad方法的缺点。
6. Adam
Adam是最近才提出的一种更新方法,它看起来像是RMSProp的动量版。简化的代码是下面这样:
m = beta1*m + (1-beta1)*dx
v = beta2*v + (1-beta2)*(dx**2)
t += 1
#########
# 完整版 #
# 偏置矫正,只有在前几次迭代时(当t较小时)作用比较大
# 主要是一种针对m、v初始为0的补偿措施,将m、v变大
m_bias = m / (1 - beta1**t)
v_bias = v / (1 - beta2**t)
#########
x += - learning_rate * m_bias / (np.sqrt(v_bias) + eps)