安装
下载安装包
https://www.pipelinedb.com/download
创建系统文件目录和日志目录

pipelinedb安装
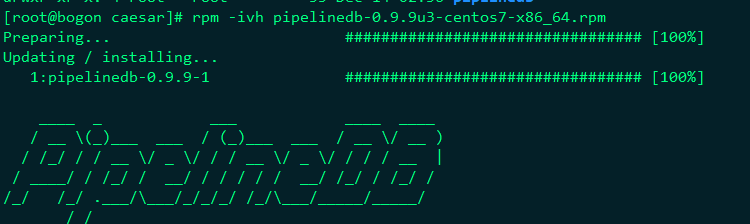
使用非root用户,初始化pipelinedb
修改配置文件
vim pipelinedb.conf
vim pg_hba.conf
启动pipelinedb

进入pipelinedb客户端
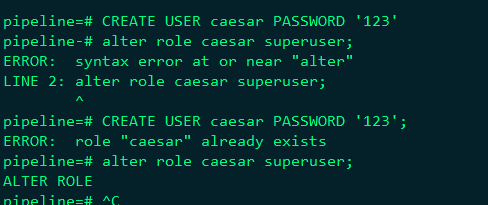
添加用户
初步使用
创建stream,供数据insert到stream后,各个视图获取数据。如下创建一个三个字段x,y,z 的stream。x 为interger,y为interger,z为text

创建一个continuous view 视图,该视图从stream_test1 流中,统计x+y的和
create continuous view v_sum as select sum(x+y) from stream_test1; 其中 as 之后是对流中数据处理,通过select ..(字段处理分析函数)...from后表示处理的流名称

对stream_test1插入数据,insert into stream_test1 values (1,2,'A'),(3,4,'B'),(5,6,'C'),(7,8,'D'),(1,2,'A');

查询视图中数据:select * from v_sum;
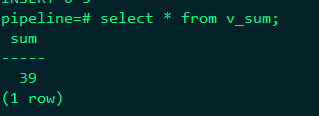
创建一个original 视图,对流过的原始数据保存
create continuous view orginal as select x,y,z from stream_test1;

插入数据

查询视图中数据
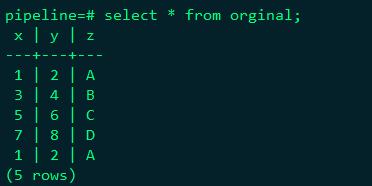
删除stream,报错,需要使用cascade删除相关联的视图


查询指定数量数据 limit

从上面可以看出,pipelinedb对数据只保存数据中关心的数据进行处理,其他不关心的数据直接丢弃。对一些统计,比如网站流量和top 问题比较有用,如果只是存储数据,则可能性能并不很好