OpenSTA 基于CORBA的分布式软件测试构架。使用OpenSTA,测试人员可以模拟大量的虚拟用户。OpenSTA的结果分析包括虚拟用户响应时间、web服务器的资源使用情况、数据库服务器的使用情况,可以精确的度量负载测试的结果。详细官方文档:OpenSTA教程
总括

本文内容
本文针对OpenSTA中的几个重要部分进行详细介绍,关于其他部分的内容请查看官方文档。本文中,将重点介绍:
- Collector方面:
- NT Performance的配置
- Script方面:
- Script基本介绍
- Script变量实现参数化
- DOM对象实现关联
- Test方面
- 如何添加Task Group
- Task Group各个参数选项说明
- Monitoring、Results简单介绍
- Name Server方面
- 设置负载生成器
1. NT Performance的配置
NT Performance调用的是操作系统自带的Perfmon工具,如何设置添加Windows性能监视这里就不介绍了。
2. Script基本介绍
首先声明一 下,OpenSTA的脚本使用的是其专有的SCL(Script Control Language)语言,语法比较复杂,使用起来相当的困难。所以,我对OpenSTA的定位是:脚本以录制为主,小部分修改,参数设置为辅。我们现在录 制一个最基本的脚本,看看是什么样,比如:访问一个静态页面(最简单的一个页面,输出几个字符),录制脚本如下:

我 们只是录制一个简单的访问一个静态页面的脚本,竟然自动生成了那么多代码!不要慌,让我们在仔细看看上图。其实,我们把代码分解一下,可以将脚本分为三个 部分:Environment, Definitions, Code。通过上图也知道了各部分的大致内容和作用,因此,如果我们撇开其他部分不看,而只看Code部分的PRIMARY GET URI 语句,是不是简单了很多呢?!
在PRIMARY GET URI语句后面我们看到了“ON 1”的代码,而且在而且在脚本最后几行有“DISCONNECT FROM 1”语句。这里的“ON 1”是用来标示TCP连接,“DISCONNECT FROM 1”用来关闭TCP连接。这都是OpenSTA根据Http协议下的真实情况录制出来的。
在对脚本的结构有了大致了解后,让我们来看看如何在Definitions中定义变量并在Code中使用我们的变量。
3. Script变量实现参数化
3.1 创建变量
通过Script Modeler的菜单 Variables - Create 来创建变量,如下图:
-

-
Name -- 变量名称
-
Scope 变量范围,非常重要的一个属性!!有以下几种范围:
- Local
- 某变量范围设置为Local后,虚拟用户只能在自己当前运行的脚本内使用该变量,而无法使用其他用户或其他脚本内的该变量。可能刚开始不好理解,让我们用下面的图来表示虚拟用户(Virtual User)、脚本(Script)、变量访问范围(Scope)的关系:

- Script
- 变量范围设置为Script,则表示运行时所有虚拟用户共用同一个Script里的变量。比如4个用户虚拟用户一起运行脚本A,假设脚本A中有一个设置为Script范围的变量B,则4个虚拟用户共用变量B,如果有人对变量B进行修改,则会影响到其他人。如下图:

- Thread
- OpenSTA 中,每个虚拟用户是一个单独的线程,单变量范围设置为Thread后,则表示该变量在单个虚拟用户的线程内共享,很奇妙的是它定义在Script中却能够 跨越Script共享同一变量。因此,如果要设置Thread范围多个Script共享同一变量,必须在每个Script中定义它。通常我们会把这样的变 量定义在Global_Variables.INC文件中。这是一个全局变量文件,我们的每个脚本都会在中引用它,如:
Thread范围的变量范围使用如下图:
Include "GLOBAL_VARIABLES.INC"
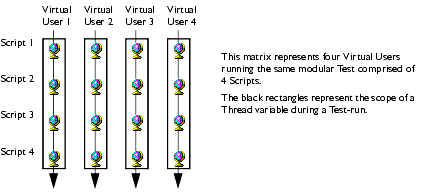
- OpenSTA 中,每个虚拟用户是一个单独的线程,单变量范围设置为Thread后,则表示该变量在单个虚拟用户的线程内共享,很奇妙的是它定义在Script中却能够 跨越Script共享同一变量。因此,如果要设置Thread范围多个Script共享同一变量,必须在每个Script中定义它。通常我们会把这样的变 量定义在Global_Variables.INC文件中。这是一个全局变量文件,我们的每个脚本都会在中引用它,如:
- Global
- 设置为Global的变量可想而知范围最大,即变量在所有虚拟用户,所有脚本中共享。同样,变量必须在每个脚本中定义或是在Global_Variables.INC中定义。如下图:

- Local
-
Value -- 设置值的来源,可以是自己输入的数值(Variable)、数组(Value List)、文件中的数据(File)、数据库中的数据(Database)等。
-
Order -- 变量取值的顺序,分为:按顺序取(Sequential)和随机取(Random)。注意,当数据取完时,会从头开始取数据。
-
Type -- 变量类型,分为字符串(Character)和数字(Integer)。
-
3.2 使用定义好的变量
假如我们在刚才的步骤中创建了USERNAME和PASSWORD两个变量,Scope定义为SCRIPT,再创建MY_USERNAME和MY_PASSWORD两个Local变量。在Definitions中的定义如下:
-
CHARACTER*512 USERNAME ( "phillip", "allan", "david", "robert", "donna" ), SCRIPT
CHARACTER*512 PASSWORD ( "pillihp", "nalla", "divad", "trebor", "annod" ), SCRIPT
CHARACTER*512 MY_USERNAME, LOCAL
CHARACTER*512 MY_PASSWORD, LOCAL
为了让所有用户在同一个脚本中使用同一个变量,解决并发的问题,我们必须在使用变量前使用互斥锁(MUTEXLocking)。如下:
-
ACQUIRE MUTEX "LOGIN"
NEXT USERNAME
NEXT PASSWORD
SET MY_USERNAME = USERNAME
SET MY_PASSWORD = PASSWORD
RELEASE MUTEX "LOGIN"
过 程:首先,加锁(ACQUIRE MUTEX),并取名为LOGIN,然后使用NEXT语句获取USERNAME、PASSWORD变量的下一个数据,然后使用SET语句将取出的值赋值给 本地变量MY_USERNAME、MY_PASSWORD,然后释放锁(RELEASE MUTEX)。
有了上面的四种不同范围的变量,相信要实现不同类型的参数化就变的相当的简单和方便了。
4. DOM对象实现关联
DOM是Document Object Model文档对象模型的缩写。DOM是一种与浏览器,平台,语言无关的接口,使得你可以访问页面其他的标准组件。通过DOM,我们可以动态的获取返回的 HTML或XML,并方便的取出里面相应节点的内容进行检查或他用。OpenSTA在录制时会把这些信息记录在一个后缀为.ALL的文件中,光标定位到 PRIMARY POST URI 或是 PRIMARY GET URI处,点击工具栏黄色右箭头按钮,如图:
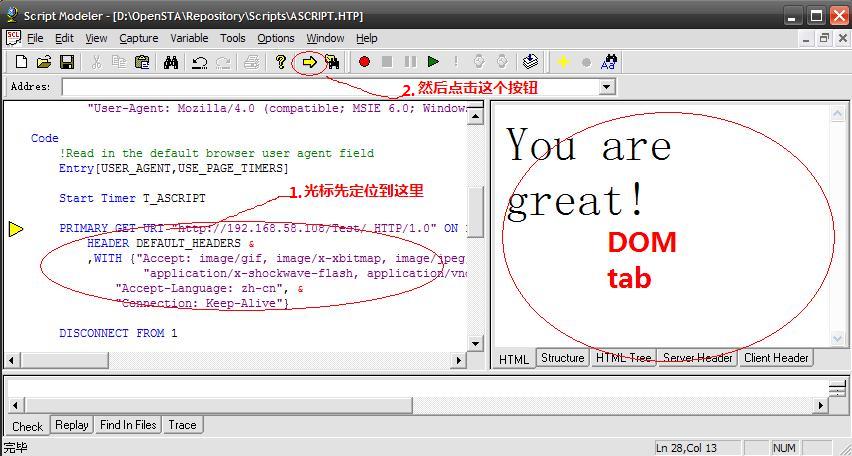
现在我们要动态的获取页面的返回值:“You are Great!”,我们选中DOM tab中的HTML Tree,找到“You are Great!”,选中,右键点击“Address”,如图:
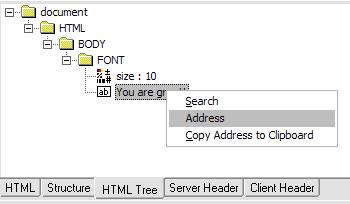
在弹出的对话框中输入变量的名字,比如:ReturnText,确定后,代码中添加了如下内容:
-
LOAD RESPONSE_INFO BODY ON 1 &
INTO ReturnText &
WITH "HTML(0)/BODY(0)/FONT(0):TEXT:(0)"
然后就可以直接使用ReturnText变量了,我们可以用REPORT函数输出ReturnText来检查是否正确。
-
REPORT ReturnText
每次访问页面的时候Cookie的值都会不一样,OpenSTA自动为我们处理了这个需要动态获取的东西,处理的方式和刚才的ReturnText是一样的。
5. 如何添加Task Group
在Commander中添 加一个Task Group比较变态,首先点击Tests右键创建一个Test,然后在左边的目录树中把要运行的Script或是Collector拖动拖到Task Group的TaskX(1,2,3...)列,可以看到,一个Task Group可以有多个Task,这里要注意的是:
- Collector不允许和Script放在同一个Taks Group
- Task Group有多个Task时,执行顺序是按Task编号执行,比如有四个Task,执行顺序是:Task1 → Task2 → Task3 → Task4
- 如果是多用户执行多个Task,某个用户先执行完Task1,不会等待其他用户执行完Task1,而是直接执行后面的Task2。即,用户不会集合,都是单独执行。
6. Task Group各个参数选项说明
首先看看Task Group有哪些列:
-

-
Task Group列是Task Group的名称和说明信息。
-
Start列 中可以设置Task Group的开始时间(Start Task Group),分为:立即开始(Immediately)、某个时间开始(Scheduled)、从现在开始计时多久后开始(Delay)。结束Task Group的条件(Stop Task Group),分为:设置整个Task Group循环执行多少次后完成(On Completion),手动控制完成(Manually),固定多长时间后完成(After fixed time)。
-
Status列表示当前Task Group的状态,执行前状态为:有效(Enabled),执行后会出现:运行中(Running)、失败(Fail)等状态。
-
Host列是负载生成器的主机名称或IP,这里可以设置其他远程机器运行负载,后面会介绍如何设置。
-
VUs列是虚拟用户设置相关的内容。界面上有些内容显示不全,因此使用Spy++取出完整的内容,看下图:
-
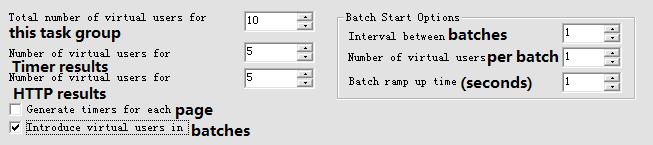
- Total number of virtual users for this task group -- 指定task group的总虚拟用户数
- Number of virtual users for Timer results -- 指定需要进行Timer计时统计的虚拟用户数,因为执行过程中,统计事务执行时间等操作也会造成一定的消耗,因此,可以指定只有部分的虚拟用户收集进行自 己的时间统计数据,这个和”抽样统计“的思路差不多。
- Number of virtual users for HTTP results -- 指定需要统计HTTP results的虚拟用户数,和上面意思差不多,抽样统计。
- Generate timers for each page -- 为脚本中每个页面进行时间统计,这个我没有理解,试了各种情况似乎都没什么作用。如果你知道的话告诉我吧~、
- Introduce virtual users in batches -- 设置是否将虚拟用户分成几批来执行,选中的话会在右边出现一个Batch Start Options
- Interval between batches -- 设置每批用户执行的间隔时间
- Number of virtual users per batch -- 设置每批用户的数量
- Batch ramp up time (seconds) -- 设置每批执行的时间
-
关于按批执行,执行的规律是比较奇怪的,比如虚拟用户总数设置为20,每批间隔时间设置为2秒,每批用户数为5,每批运行时间为10秒,则相对于每批Batch来看,运行情况如下:
-

然而,在同一批内的五个虚拟用户是如何执行的呢? 是在10秒内同时并发执行一次?多次?还是10秒内按顺序执行?经过试验,发现同一批内的五个虚拟用户是按顺序来执行的,因为每批用户数是5,每批运行时 间是10秒,因此,按顺序执行平均分下来每个用户需要执行10/5=2秒,在2秒内,虚拟用户只执行一次,然后2秒后,下一个用户开始执行。同一批内用户 执行情况如下图: 
-
-
-
Task列是设置当天列的Task的一些基本信息,界面上有些字也不全,补全后如图:
-

- Task Termination -- Task 结束方式,分为两种:循环执行指定次数后停止(On Completion)、循环执行指定时间后停止(After Fixed Time)。当选择On Completion时,在下面的文本框中输入需要循环的次数,当选择After Fixed Time时,在下面的文本框中输入需要循环执行的时间。
- Delay between each iteration -- 设置相邻两次迭代之间的时间间隔,分为两种:固定时间(Fixed Delay)、可变时间(Variable Delay)。当选中Fixed Delay时,在下面的文本框中输入固定的间隔时间(Delay),当选中Variable Delay时,则输入间隔时间范围的最小值(Minimum)和最大值(Maximum)。
-
7. Monitoring、Results简单介绍
- Monitoring只在Test运行期间可用,比较变态,很废的东西。
- Results部分十分简陋,感觉收集的信息太少,图表不能合并,画出的图十分的难看。。。不错的是支持导出数据。。。。
8. 设置负载生成器
负载生成器机器即被控制 执行测试的机器(Loader),必须运行OpenSTA Name Server,右键 - Configure - Repository Host(晕!界面上看只有Repository这个单词,原来这个也显示不全。。。) - 输入运行了OpenSTA Commander的主控机器(Controller)的IP。注意修改了Repository Host后要重启服务。这样,在主控制机器(Controller)的Commander中的设置Host Name - 输入负载生成器机器的IP。搞定。
这样做似乎有一些确定,因为假如我要控制别的机器运行测试案例,需要在别的机器上指定我的机器的IP,当我要用另一台机器做控制端(Controller)时,又需要修改那些机器的设置,不像LoadRunner一样方便,不需要修改什么。
9. 总结
用过了LoadRunner,看过了WebLOAD等其他工具,总体感觉OpenSTA还是不错的,给人的感觉是小巧,简洁。在通过变量实现参数化的过程中感觉非常的灵活,同时,在构建一个场景相对简单的性能测试案例时,OpenSTA是一个不错的选择。然而OpenSTA又有着许多不足:
- 脚本语言过于复杂,自定义脚本相当困难
- 似乎不支持集合点的设置
- 场景设计方面太过于简单,对于构建一些复杂的场景比较麻烦
- 不能收集Linux性能数据
- 使用Repository管理测试脚本、配置等过于简单,保存脚本居然不能自己选择路径
- Results结果报告的图表太简陋,功能太少!
- 负载生成器的被控端设计不合理
