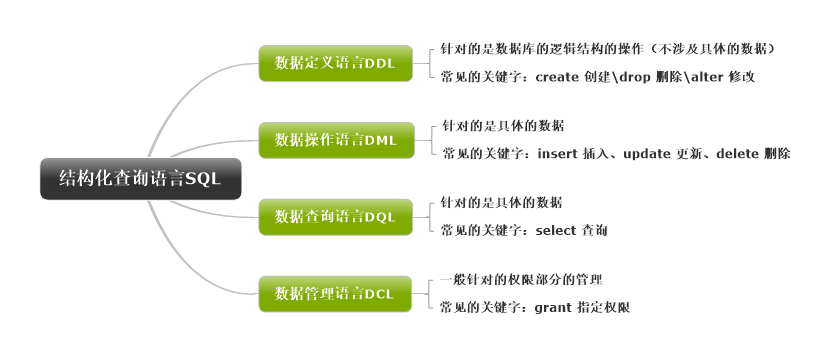
一、数据定义语言DDL
1.创建表空间:CREAT TABLESPACE lyy DATAFILE 'C:/app/lyy.dbf' SIZE 10M;(创建一个10M的表空间,存放在C盘app文件夹中)
删除表空间:DROP TABLESPACE lyy;
2.创建用户和赋权:CREAT USER lyy PROFILE DEFAULT IDENTIFIED BY 123456 DEFAULT TABLESPACE lyy TEMPORARY TABLESPACE temp ACCOUNT UNLOCK; (创建用户lyy,默认密码为123456,默认表空间为lyy,临时表空间为temp,账号开启状态)
GRANT CONNECT TO lyy;
GRANT RESOURCE TO lyy;(赋予用户lyy connect和resource权限)
3.创建表
语法格式:CREAT TABLE 表名(属性名1 数据类型(长度),属性名2 数据类型......属性名n 数据类型);
例:创建以下三个表:
--学生表 student:学号 sid、姓名 sname、性别 ssex、年龄 sage、电话 sphone
--课程表 course: 课程编号 cid、课程名称 cname、老师名称 tname、课时 chour
--成绩表 score: 成绩编号 scid、学号 sid、课程编号 cid、分数 grade
在Oracle中,表的全名是:方案名.表名;方案名就是用户名,方案名不写,表示方案名就是当前用户自己;
——创建学生表
CREAT TABLE student(
sid CHAR(10),
sname VARCHAR2(50) NOT NULL,
ssex CHAR(1),
sage NUMBER,
sphone INTEGER
);
——创建课程表
CREAT TABLE course(
cid CHAR(10),
cname VARCHAR2(50),
tname VARCHAR2(50),
chour NUMBER
);
——创建成绩表
CREAT TABLE score(
scid CHAR(10),
sid CHAR(10),
cid CHAR(10),
grade NUMBER
);
删除表: DROP TABLE student;
4.约束条件
约束是由用户添加,用来保证存储到数据库的数据的实体完整性和参照完整性;
约束种类一般有五种:
--主键约束:Primary key,要求被定义为主键的字段的值具有唯一性和非空性;
constraint p1_sid primary key(sid) --定义sid为主键。
--外键约束:Foreign key,要求被定义为外键的字段的值必须来源于所引用字段的值, 外键字段和所引用的字段,名称可以不一样,但是两者的数据类型和长度必须一致;
constraint f1_sid foreign key(sid) references student(sid) --定义sid为外键,值来源于student表的sid
--唯一约束:Unique ,要求具有唯一性;
unique(sid,cid) --定义sid和cid的组合有唯一性。
--非空约束:not null,要求必须有值;
sname varchar2(50) not null --定义sname字段非空
--检查约束:check,用户可以根据业务的需要,对字段的值进行自定义限制。
constraint c1_ssex check(ssex in ('M','F')) --定义检查约束,要求ssex字段的取值必须为M或者F
5.修改表ALTER
ALTER TABLE SCOTT.TEST RENAME TO TEST1--修改表名
ALTER TABLE SCOTT.TEST RENAME COLUMN NAME TO NAME1 --修改表列名
ALTER TABLE SCOTT.TEST MODIFY NAME1 NUMBER(20) --修改字段类型
ALTER TABLE SCOTT.TEST ADD ADDRESS VARCHAR2(40) --添加表列
ALTER TABLE SCOTT.TEST DROP NAME CASCADECONSTRAINTS --删除表列
二、数据操作语言DML
DML是数据操作语言,主要可以完成三个操作:insert插入、update更新、delete删除;DML语句是一种事务操作语句,需要做commit确认、rollback回滚操作才能最终完成的。如果不做确认或者回滚操作,则会锁定当前的表,导致针对该表的DDL等操作都会失败。
1.insert插入数据
语法格式1: insert into 表名 values(值1,值2......,值n);
注意事项:在SQL语句中,一般来说,除了值得部分(数据),其他部分都是不区分大小写的,数据部分,字符类型需要单引号,其他类型不需要单引号;该格式下,要保证值得数量、类型、长度、顺序都要和表的字段保持一致。
示例:SELECT * FROM student;
INSERT INTO student VALUES('S001','张三',‘M’,30,13089247856) ;
语法格式2: insert into 表明(字段名1,字段名2,......,字段名n) values(值1,值2,......,值n);
注意事项:注定值和字段的对应关系(按顺序对应),好处是可以根据自身的值和字段的对应关系,有选择性进行插入操作。
示例: INSERT INTO student(sname,ssex,sid,sage) VALUES('李四','F','s0002',20);
2.update更新数据
语法格式:update 表名 set 赋值表达式 [where 条件]
注意事项:update本身是一个列操作的语句,即不加条件,操作的是表中的整列数据;如果加了条件,因为条件限定是行,则表示操作的是选中的行所对应的列。
示例: SELECT * FROM student;
UPDATE student SET sage=40;
UPDATE student SET sage=(sage+sphone)-sage,sphone=(sage+sphone)-sphone;
UPDATE student SET sage=sage+1;
UPDATE student SET sage=sage+1 where ssec='F';
UPDATE student SET sname=replace(sname,'张','陈');
3.delete删除数据
语法格式:delete from 表 [where 条件]
注意事项:delete是一个行操作,最小操作单位是一条记录,切记delete没有*号;如果不加where条件,则表示删除整个表中的所有记录。
示例:DELETE FROM student WHERE sid='s0002';
INSERT INTO course VALUES('c0001','oracle','teacher 1',32);
INSERT INTO score VALUES('sc0001','s0001','c0001',100);
SELECT * FROM student;
SELECT * FROM course;
SELECT * FROM score;
4.truncate:是DDL语句,但也可以实现删除整表的数据的效果
语法格式:truncate table 表名
示例: truncate table score;
三、数据查询语言DQL
1. select 用来对数据进行查询,获取用户想要的信息。
语法格式:
select : 查询的内容,是必选关键字,后面跟要查询的内容,一般以字段为主、也可以是常量、表达式(包含字段)。
--from: 查询内容的来源,是必选关键字,来源可以是表格、多个表格、其他的查询语句等;
--where:条件,可选关键字,一般用来指定查询的条件,即用来过滤数据;
--group by:字段,可选关键字,用来实现分组查询;
--having:条件,可选关键字,是用来对分组之后的结果进行过滤;
--order by:字段,可选关键字,用来实现排序操作;
注意事项:不带条件的查询,即列查询,查询内容可以是表中的一个字段、多个字段、常量或者表达式。
示例:
--查询学生表的所有内容
SELECT * FROM student;
--查询所有学生的姓名和年龄
SELECT sname,sage FROM student;
--查询常量
SELECT sname,sage,'teacher 1' FROM student;
--查询内容是表达式
SELECT sname,sage,sage+1 FROM student;
2. || 用来实现字符串、变量的拼接操作的
示例:SELECT sname,sage,sage||'岁' FROM student;
SELECT sname,ssex FROM student;
SELECT sname,ssex,case WHEN ssex='M' THEN '男' ELSE '女' END FROM student;
3.条件
加查询条件是用来过滤数据的,过滤的基本单位是行,常见的关键字有:(> /< /= />= /<=/ !=/ <> /between..and.. /like/ in /all /any /exists/not exists等;多个条件的连接符有:andor!
示例:
--查询年龄大于28岁的所有学生的信息
SELECT * FROM student WHERE sage>28;
--查询年龄大于等于28岁的所有学生的信息;
SELECT * FROM student WHERE sage>=28;
--查询所有男生信息
SELECT * FROM student WHERE ssex='M';
SELECT * FROM student WHERE ssex!='F';
SELECT * FROM student WHERE ssex<>'F';
--查询学号比s0010靠前的学生的信息。
SELECT * FROM student WHERE sid<'s0010';
1)between..and..
语法格式:字段 between 值1 and 值2 等价于 字段>=值1 and 字段<=值2;是一个独立、完整的字段,不可拆分。
示例:--查询年龄在23-28岁之间(包含)的学生信息。
SELECT * FROM student WHERE sage>=23 AND sage<=28;
SELECT * FROM student WHERE sage BETWEEN 23 AND 28;
--查询年龄在23-28岁之间(包含)的女生信息。
SELECT * FROM student WHERE sage BETWEEN 23 AND 28 AND ssex='F';
SELECT * FROM student WHERE sage>=23 AND ssex='F'AND sage<=28;
2)like:实现的是模糊查询,一般来说会结合两个特殊符号使用,%通配符,匹配任意多个字符;_表示匹配一个字符。
示例:--查询所有姓张的同学信息。
SELECT * FROM student WHERE sname LIKE '张%';
--查询所有姓张,姓名总共为2个字的同学信息。
SELECT * FROM student WHERE sname LIKE '张_';
--查询所有姓张,姓名总共为3个字的同学信息。
SELECT * FROM student WHERE sname LIKE '张__';
SELECT * FROM student WHERE sname LIKE '%张';
3)in:是一种枚举用法,字段in(值1,值2,......,值n)等价于 字段=值1 or 字段=值2 or ... or 字段=值n。
示例:--查询年龄等于27岁或者28岁的学生的信息。
SELECT * FROM student WHERE sage=27 OR sage=28;
SELECT * FROM student WHERE sage IN (27,28);
4)distinct:用来修饰字段,表示唯一查询、去除重复值。
示例:--查询所有选课了的学生的学号。
SELECT sid FROM score;
SELECT DISTINCT sid FROM score;
5)别名:可以应用在查询内容和来源中。
语法格式: 原名 as 别名,一般来说,as是省略的, 原名 别名。
示例:SELECT sname,sage FROM student;
SELECT sname as 姓名,sage 年龄 FROM student;
SELECT sname,sage+1 sage FROM student;
SELECT sname sage FROM student; --语法没问题,从应用层面是有问题的。查询学生姓名,但结果是列名改为了sage。
6)嵌套
SQL语句中,查询语句是可以被嵌套使用。嵌套是通过括号()实现。每一条查询语句的结果本身就是一个表、是一些值的集合,可以被嵌套使用在值或者来源的部分。
--查询所有选修oracle课程的学生的姓名。
SELECT sname FROM student WHERE sid IN (SELECT sid FROM score WHERE cid=(SELECTcid FROM course WHERE cname='oracle'));
--查询某一位同学所选修的课程的名称。(已经学生姓名)
SELECT cname FROM course WHERE cid IN (SELECT cid FROM score WHERE sid in (SELECT sid FROM student WHERE sname='张三'));
7)all: 使用and来对表达式进行分解
--字段 > all(值1,值2,。。。,值N) 等价于: 字段>值1 and 字段>值2 and... and 字段>值N。
--字段 < all(值1,值2,。。。,值N) 等价于: 字段<值1 and 字段<值2 and... and 字段<值N。
示例:查询比所有女生年龄都大的男生信息。
SELECT * FROM student WHERE ssex='M' AND sage>39;
SELECT sage FROM student WHERE ssex='F'; --212539
SELECT * FROM student WHERE ssex='M' AND sage>ALL(SELECT sage FROM student WHERE ssex='F');
--等价于 SELECT *FROM student WHERE ssex='M' AND sage>21 AND sage>25 AND sage>39;
8)any: 就是用or来对表达式进行分解
--字段 > any(值1,值2,。。。,值N) 等价于: 字段>值1 or 字段>值2 or ... or 字段>值N。
示例:--查询比任一女生年龄都大的男生信息。
SELECT * FROM student WHERE ssex='M' AND sage>ANY(SELECT sage FROM student WHERE ssex='F');
4.聚合函数(分组函数/组函数)
常见的聚合函数有:count()avg()min()max()sum(), 括号里加字段或字段表达式。
示例:--查询男生的数量
SELECT count(*) FROM student WHERE ssex='M';
--查询有成绩的学生的数量
SELECT count(distinct sid) FROM score;
--查询女生的最小年龄
SELECT min(sage) FROM student WHERE ssex='F';
--查询某一位学生的平均成绩
SELECT avg(grade) FROM score WHERE sid='s0001';
--查询年龄最大的学生的姓名
SELECT* FROM student WHERE sage=(SELECT max(sage) FROM student);
5.分组查询
语法格式: group by 分组字段
作用:表示会将表格中所有的数据按照分组字段进行分组处理、分组字段的值相同的行会被合并为一条记录、即一组;分组字段以外的字段是无法再被独立查询,只能通过聚合函数来实现查询,分组字段可以是多个,用逗号分隔。
示例:--查询男生和女生的数量
SELECT ssex,COUNT(*) FROM student GROUP BY ssex;
--查询男生和女生的平均年龄、最大年龄、最小年龄
SELECT ssex,AVG(sage),MAX(sage),min(sage) FROM student GROUP BY ssex;
--查询每一门课程被选的数量
SELECT cid,COUNT(DISTINCT sid) FROM score GROUP BY cid;
注意:where是发生在分组之前,having是发生在分组之后,意味分组函数是不能直接作为条件的值出现在where之后,但是可以出现在having之后。
示例:--查询所有科目都及格的学生的sid。
SELECT sid FROM score WHERE grade>=60 GROUP BY sid; --错误的写法,实现的是任意科目及格的学生。
SELECT sid FROM score GROUP BY sid HAVING MIN(grade)>=60; --先按学生分组,设定条件每个学生的最低分要大于等于60.