前言
大数据实在是太热,一直对新技术充满着向往,其实hadoop也不是新技术,已经好几年了。打算学习,一下hadoop整个生态圈的内容。这篇文章介绍一下环境搭建,自己搭环境摸索了好几天连着,终于搭建完成,记录一下。并share一下,如果哪天你也需要,大家一起共勉。在这希望我能认认真真写完每一篇博客,坚持一直写。
——chaosju
环境+工具准备
大数据实在是太热,一直对新技术充满着向往,其实hadoop也不是新技术,已经好几年了。打算学习,一下hadoop整个生态圈的内容。这篇文章介绍一 下环境搭建,自己搭环境摸索了好几天连着,终于搭建完成,记录一下。并share一下,如果哪天你也需要,大家一起共勉。在这希望我能认认真真写完每一篇 博客,坚持一直写。
1.vmare虚拟机
2.xshell or secureCRT
3.JDK1.6 或者 1.7 -------不建议1.8
4.centos的iso
5.安装ssh
6.hadoop2.5.2
download:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.5.2/hadoop-2.5.2.tar.gz
download:http://hadoop.apache.org/releases.html#19+November%2C+2014%3A+Release+2.5.2+available
7.zookeeper-3.4.6.tar
download:http://www.apache.org/dyn/closer.cgi/zookeeper/
注意:apache提供的hadoop-2.5.2的安装包是在32位操作系统编译的,因为hadoop依赖一些C++的本地库,所以如果在64位的操作上安装hadoop-2.5.2就需要重新在64操作系统上重新编译(建议第一次安装用32位的系统)。
编译教程:http://blog.csdn.net/ggz631047367/article/details/42460589
64位hadoop2.5.2下载地址:http://pan.baidu.com/s/1kTnIeLT
hadoop搭建环境准备步骤 像虚拟机安装,xshell的安装使用,就不在这说了。直说一点,我搭建完全分布式,用到4台虚拟机,不要一台一台安装,用vwware的克隆功能,例如你的jdk已经搭建完成,就可以克隆了。
现在4台虚拟机已经安装好了假设。搭建环境真正的开始。
0.如果你其中3台虚拟机用的VMware克隆,需要保证ip能够自动获取,做以下修改。其中克隆的主机需要修改
克隆之后的操作系统需要重新分配MAC地址 a、vi /etc/sysconfig/network-scripts/ifcfg-eth0 (网卡信息) 将该文件中删除两行:UUID和物理地址 b、删除rm -rf /etc/udev/rules.d/70-persistent-net.rules 文件 c、重启 init 6 或reboot
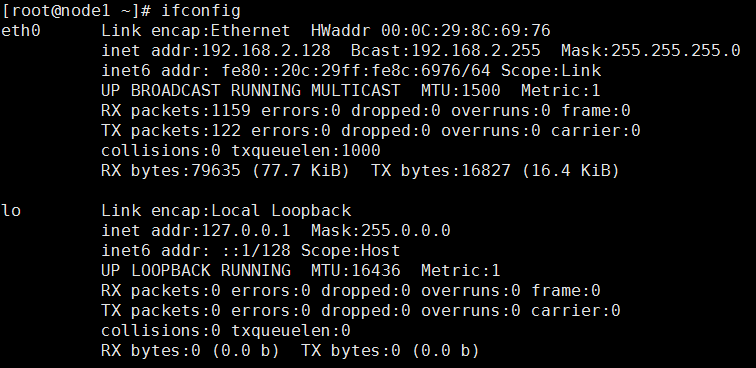
修改上述操作完成,执行ifconfig能够看到etho的ip,和新的mac地址
ifconfig
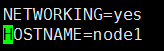
1.修改Linux主机名 ,4台主机全部修改
vim /etc/sysconfig/network
修改每台主机的hostname,我的命名是node1、node2、 node3、node4
2.修改IP(可选)改成固定ip,4台主机全部修改
vi /etc/sysconfig/network-scripts/ifcfg-eth0 #修改 BOOTPROTO=static IPADDR=192.168.239.6 #(该IP即为设置的固态IP) NETMASK=255.255.255.0 GATEWAY=192.168.239.2
3.修改主机名和IP的映射关系,4台主机全部修改
vim /etc/hosts

验证:分别在每台主机上ping 别的主机的hostname,不是ip验证配置正确
4.关闭防火墙
关闭防火墙,重启还是自动重启
service iptables stop
永久关闭,建议永久关闭
chkconfig iptables off
查看防火墙关闭状态
service iptables status
5.ssh免登陆
配置node1到node1-4的ssh免登陆 node1上执行 ssh-keygen -t rsa scp ~/.ssh/id_rsa.pub node1:~/.ssh/ scp ~/.ssh/id_rsa.pub node2:~/.ssh/ scp ~/.ssh/id_rsa.pub node3:~/.ssh/ scp ~/.ssh/id_rsa.pub node4:~/.ssh/ node1-node4都要执行 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys 配置node2到node1的免登陆 ssh-copy-id -i node1
验证:ssh node*,第一次需要输入密码。之后就不需要了
6.安装JDK,配置环境变量等
这个我就不说了,自己百度吧
集群规划
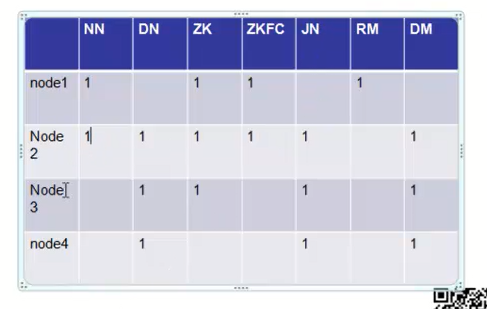
说明:你对hadoop的架构有一定的了解,不了解也没事,先搭起来再看
1. namenode(NN) node1、node2
2. datanode(DN) node1、node2
3. zookeeper(ZK)node1、node2、node3
3. DFSZKFailoverController(ZKFC)node1、node2
3. JournalNode(JN)node2、node3、node4
3. ResourceManager(RM)node1
3. DataManager(DM)node2、node3、node4
安装部署zookeeper和hadoop 一、安装配置zookeeper集群
1、node1上解压
tar -zxvf zookeeper-3.4.6.tar.gz ln -sf /root/zookeeper-3.4.6 /home/zk
2、node1上修改配置
node1上进行: cd /home/zk/conf/ cp zoo_sample.cfg zoo.cfg vim zoo.cfg 修改:dataDir=/opt/zookeeper 在最后添加: server.1=node1:2888:3888 server.2=node2:2888:3888 server.3=node3:2888:3888 然后创建一个tmp文件夹 mkdir /opt/zookeeper 再创建一个空文件 touch /opt/zookeeper/myid 最后向该文件写入ID echo 1 > /opt/zookeeper/myid
3、将配置好的zookeeper拷贝到node2、node3)
将node1上zookeper的安装文件copy到node2和node3 scp -r /home/zk/ node2:/root scp -r /home/zk/ node3:/root node2: ln -sf /root/zk /home/zk node3: ln -sf /root/zk /home/zk 将node1上zookeper的配置文件copy到node2和node3 scp -r /opt/zookeeper/ node2:/opt scp -r /opt/zookeeper/ node3:/opt 注意:修改node2、node2对应/opt/zookeeper/myid内容 node2: echo 2 > /opt/zookeeper/myid node3: echo 3> /opt/zookeeper/myid
二、安装配置hadoop集群
1、node1解压
tar -zxvf hadoop-2.5.2.tar.gz ln -sf /root/hadoop-2.5.2 /home/hadoop2.5
2、将hadoop添加到环境变量中
vim /etc/profile
修改: export JAVA_HOME=/usr/java/jdk1.6.0_45 export HADOOP_HOME=/home/hadoop2.5 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
3、修改配置文件,hadoop的配置文件在cd /home/hadoop2.5/etc/hadoop,需要修改的配置文件如下图

1)core-site.xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/hadoop2</value> </property> </configuration>
2)hdfs-site.xml
<configuration> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>node1:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>node2:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node1:50070</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node2:50070</value> </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node2:8485;node3:8485;node4:8485/mycluster</value> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/journalnode/data</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
3)mapred-site.xml
<configuration> <!-- 指定mr框架为yarn方式 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
4) yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties --> <!-- 指定resourcemanager地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <!-- 指定nodemanager启动时加载server的方式为shuffle server --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
5)slaves
node2
node3
node4
6)修改hadoop-env.sh
export JAVA_HOME=/usr/java/jdk1.6.0_45
3、将修改好的hadoop拷贝到其他节点
scp -r /home/hadoop2.5/ node2:/root scp -r /home/hadoop2.5/ node3:/root scp -r /home/hadoop2.5/ node4:/root 在node2-4执行link ln -sf /root/hadoop2.5 /home/hadoop2.5
启动zookeeper和hadoop
1.启动zookeper
在node1、node2、node3上启动zk cd /home/zk/bin/ ./zkServer.sh start 查看状态: ./zkServer.sh status (一个leader,两个follower)
验证
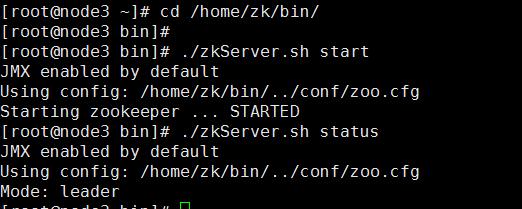
2.启动hadoop,jps查看进程
1)启动journalnode(在node2上启动所有journalnode) //ha环境下,格式化hdfs前需要启动journal node
cd /home/hadoop2.5 sbin/hadoop-daemons.sh start journalnode
(运行jps命令检验,多了JournalNode进程)

2)格式化HDFS在node1上执行命令:
cd /home/hadoop2.5 bin/hdfs namenode -format 格式化后会在根据core-site.xml中的hadoop.tmp.dir配置生成个文件,这里我配置的是/opt/hadoop2,然后将/opt/hadoop2/拷贝到node2的/opt/下。 scp -r /opt/hadoop2/ node2:/opt
3)格式化ZK(在node1上执行即可)
cd /home/hadoop2.5 bin/hdfs zkfc -formatZK
4)启动HDFS(在node1上执行)
cd /home/hadoop2.5
sbin/start-dfs.sh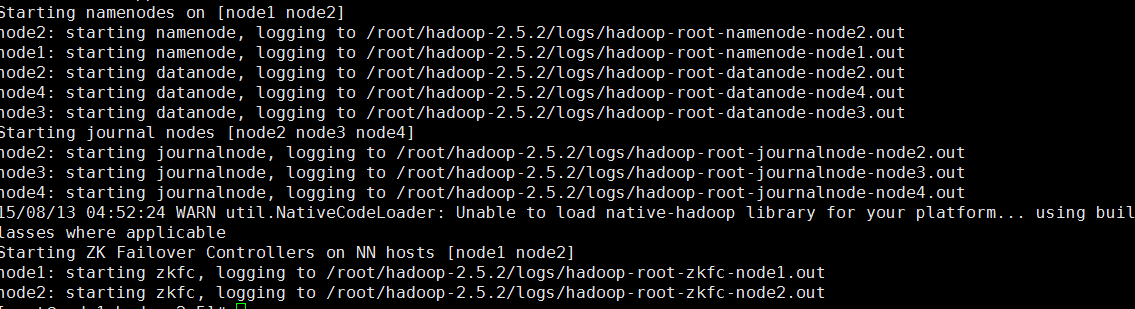
jps查看:
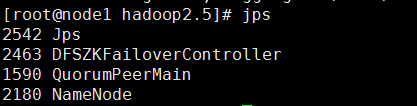
5)启动YARN(在node1上执行)
cd /home/hadoop2.5
sbin/start-yarn.sh
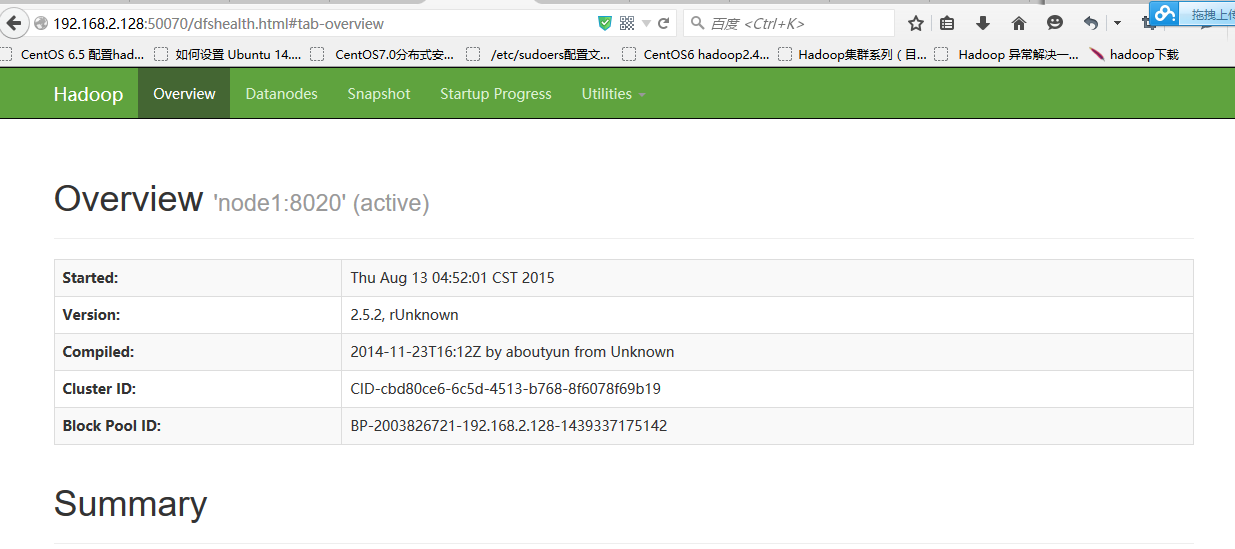
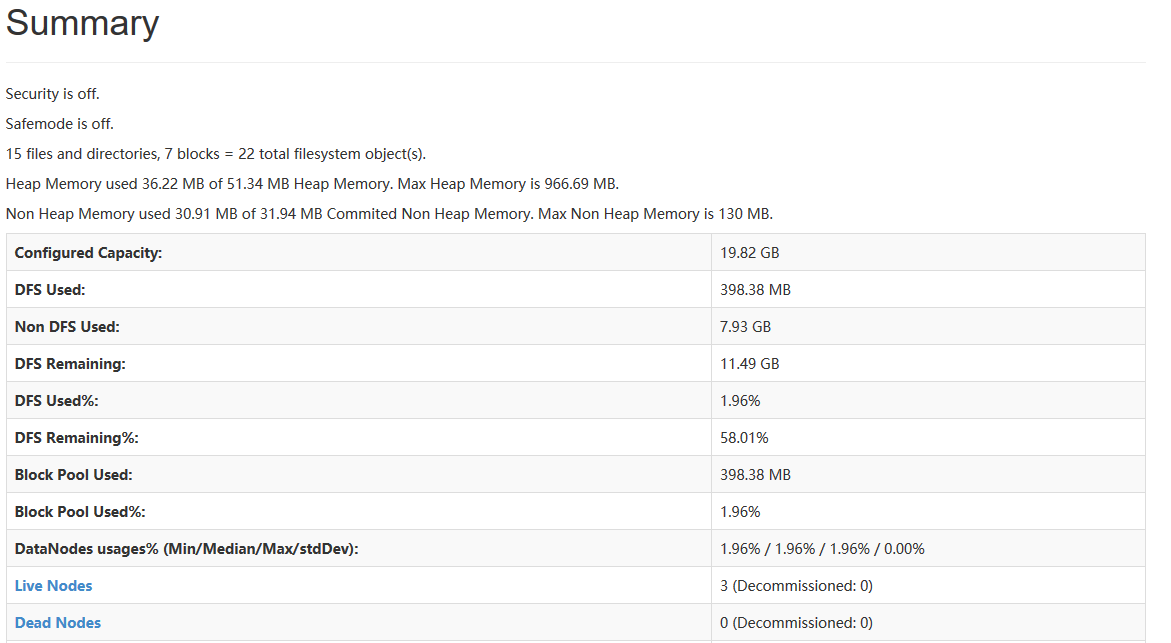
到此,hadoop2.5.2配置完毕,可以统计浏览器访问:
http://192.168.2.128:50070
NameNode 'node1:8020' (active)
http://192.168.2.129:50070
NameNode'node2:8020' (standby)
成功图片;