https://levelup.gitconnected.com/why-is-list-struct-is-15-times-faster-to-allocate-than-list-class-17f5f79889ae
在上一篇文章《免费提高 C# 代码性能的 5 种方法》中,在其中一个示例中,我测量了分配类列表和分配结构列表之间的时间差。
让我们记住这个例子:
public class PointClass { public int X { get; set; } public int Y { get; set; } } public struct PointStruct { public int X { get; set; } public int Y { get; set; } } [Benchmark] public void ListOfClassesTest() { const int length = 1000000; var items = new List<PointClass>(length); for (int i = 0; i < length; i++) items.Add(new PointClass() { X = i, Y = i }); } [Benchmark] public void ListOfStructsTest() { const int length = 1000000; var items = new List<PointStruct>(length); for (int i = 0; i < length; i++) items.Add(new PointStruct() { X = i, Y = i }); }
的ListOfClassesTest和ListOfStructsTest的方法几乎相同。第一种方法分配一百万个PointClass实例并将它们添加到列表中,而第二种方法分配一百万个PointStruct实例并将它们也添加到列表中。TypesPointClass和PointStruct拥有相同的成员,但唯一的小而关键的区别是它PointClass是一个类,而是PointStruct一个结构体。
由很棒的库BenchmarkDotNet完成的性能结果令人印象深刻:


ListOfStructsTest 方法比速度快 15 倍以上 ListOfClassesTest.
让我们试着分析一下为什么会有如此巨大的时差。
对我们来说,第一件事是理解在堆上分配引用类型的一个实例和在堆栈上分配一个结构体的实例之间的区别。
public void Test()
{
var obj = new object(); //引用类型分配
int x = 12; //值类型分配
}
在托管堆中为引用类型分配内存的时间通常是快速操作。对象被连续分配和存储。公共语言运行时具有指向内存中第一个可用空间的指针。分配新对象涉及将新对象的大小添加到指针。
在对象被放置在托管堆上之后,它的地址被写回到obj在堆栈上创建的引用。
一般来说,整个过程是相当便宜的。然而,为引用类型的对象分配内存的过程并不总是那么容易,并且可能涉及额外的繁重部分。
如果引用类型大于 85K 字节,运行时将花费更多时间在大对象堆中寻找合适的位置来存储对象,因为那里的内存是碎片化的(空闲块或地址空间中的“空洞”)。
在小对象堆中没有更多可用空间来存储应用程序请求的对象的情况下,引用类型对象分配很慢。当这种情况发生时,公共语言运行库需要运行垃圾收集过程。如果垃圾收集器没有释放足够的内存,运行时会请求额外的虚拟内存页面。
在堆栈上分配值类型实例怎么样?
为值类型分配内存几乎是即时操作,分配时间几乎不依赖于值类型的大小。运行时唯一应该做的就是创建适当大小的堆栈帧来存储值类型并修改堆栈指针。
要点是将值类型的实例放在堆栈上是快速的,更重要的是,与在堆上分配引用类型对象相比,这是一个确定性的时间过程。
现在让我们回到我们的例子。
当一个引用类型的一百万个实例被分配时,它们被一个一个地推入托管堆中,而这些引用又被存储回集合实例中。事实上,会有一百万+1个对象进入内存。
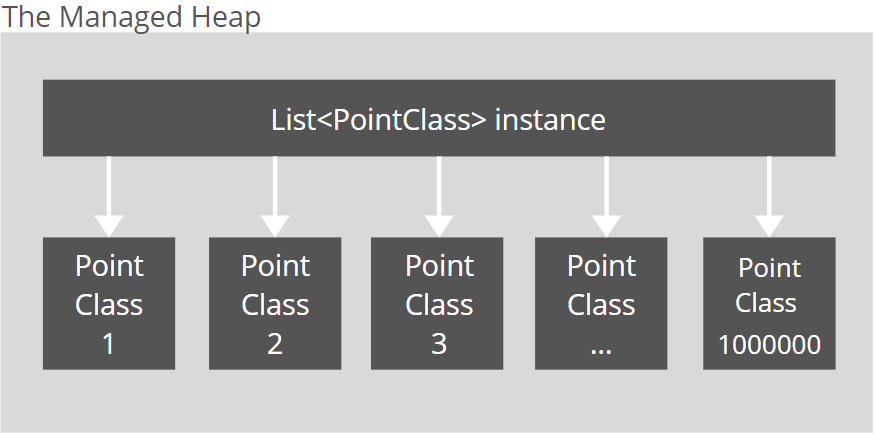
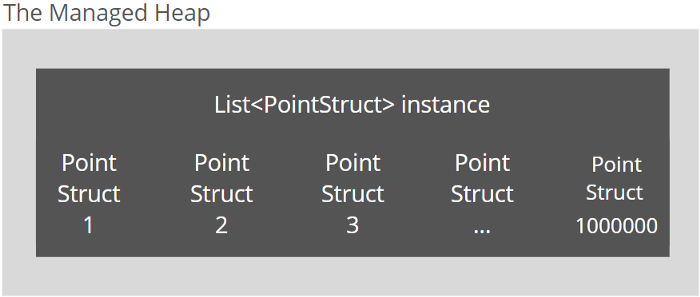
然而,当分配了一百万个值类型的实例时,只有一个被推入托管堆的对象是集合的实例。一百万个结构体将被嵌入到List<T>实例中。List<T>创建实例后,运行时唯一要做的就是用数据填充它。
开发人员在为大型集合选择结构而不是类时不仅可以从快速分配时间中受益,还可以从发布时间中受益。
如果开发人员分配了一百万个PointClass实例,在“标记和清理”阶段,垃圾收集器将必须扫描一百万个对象并检查每个对象是否还有引用。然后,在“紧凑”阶段,垃圾收集器将不得不移动一百万个对象。最终,存储在List<PointClass>实例中的地址应该用新的地址更新。这是很多工作。
但是对于垃圾收集器,当开发人员分配一百万个PointStruct实例时,情况会好得多,因为List<PointStruct>垃圾收集器将不得不使用托管堆中的唯一实例。
结论
结构可能比类更高效,但在用classastruct或其他方式替换关键字之前,请务必仔细分析您的具体情况。程序员的工作不是盲目地遵循建议或最佳实践,而是选择最合适的工具、方法、方法,以最佳方式解决他或她的独特案例。
参考
In the previous article, 5 Ways to Improve the Performance of C# Code for Free, in one of the examples, I measured the time difference between allocating a list of classes and allocating a list of structs.
Let’s remember that example:
The ListOfClassesTest and ListOfStructsTest methods are almost identical. The first method allocates a million of PointClass instances and add them to the list, while the second allocates a million of PointStruct instances and adds them to the list as well. Types PointClass and PointStruct have the same members, but the only small and key difference is that PointClass is a class, but PointStruct is a struct.
The performance results done by awesome library BenchmarkDotNet are quite impressive:
ListOfStructsTest method is over 15 times faster than ListOfClassesTest.
Let’s try to analyze why there is such a huge time difference.
The first thing for us is to understand the difference between allocating one instance of a reference type on heap and allocating one instance of a struct on stack.
public void Test()
{
var obj = new object(); //reference type allocation
int x = 12; //value type allocation
}
The time of allocating memory in a managed heap for reference type is usually fast operation. Objects are being allocated and stored continuously. The common language runtime has the pointer to the first free space in memory. Allocating a new object involves adding the size of the new object to the pointer.
After the object is placed on the managed heap, its address is written back to the reference obj that was created on the stack.
In general the whole process is quite cheap. However, the process of allocating memory for an object of a reference type is not always that easy and can involve additional heavy parts.
If the reference type is larger than 85K bytes, the runtime will spend more time looking for the appropriate place in the Large Object Heap to store the object because the memory there is fragmented (free block or “holes” in the address space).
Reference type object allocation is slow in cases where there is no more free space in Small Object Heap to store the object that the application requests. When such a case occurs, the common language runtime needs to run the garbage collection process. If the garbage collector didn’t release enough memory, the runtime requests additional pages of virtual memory.
What about allocating a value type instance on stack?
Allocating memory for value type is almost instant operation and the time of allocation almost does not depend on the size of the value type. The only thing that runtime should do is to create the stack frame of a proper size to store the value type and modify the stack pointer.
The takeaway is that placing an instance of a value type on the stack is fast and, more importantly, is a deterministic process in terms of time comparing to allocating a reference type object on a heap.
Now let’s go back to our example.
When a million instances of a reference type are allocated, they are pushed one by one into the managed heap, and the references are stored back into the collection instance. In fact, there will be one million + 1 object into memory.
However, when a million instances of a value type are allocated, there is just the only object pushed into a managed heap which is the instance of a collection. One million of structs will be embedded into the List<T> instance. The only thing to do for runtime after the List<T> instance is created is to fill it with the data.
Developers benefit not only from fast allocation time when choosing a struct instead of a class for a large collection, but also from release times.
If developers allocate one million of PointClass instances, during the “mark and clean” phase, the garbage collector will have to scan a million objects and check to see if each still has references. Then, during the “compact” phase, the garbage collector will have to move a million objects. Eventually, addresses stored into List<PointClass> instance should be updated with new ones. This is a lot of work.
But for the garbage collector, things are much better when developers allocate one million PointStruct instances, because there will be the only List<PointStruct> instance in a managed heap that the garbage collector will have to work with.
Conclusion
Structs can be more performant than classes, but always analyze your specific case carefully before replacing the class keyword with a struct or the other way around. A programmer’s job is not to blindly follow recommendations or best practices, but to choose the most appropriate tools, methods, approaches to solve his or her unique case in the best possible way.
免费提高 C# 代码性能的 5 种方法
软件开发是关于寻找权衡:
- CAP 定理——开发人员只需要为软件系统选择 3 个保证中的 2 个。
- 关系数据库模式的规范化与非规范化——开发人员在数据更新的简易性和数据检索时间之间找到平衡。
- 开发速度 vs 高质量编码——开发人员追求高质量,这是一项耗时的工作,而业务需要尽快准备好功能。
高性能 C# 代码也不是免费的。开发人员可以牺牲代码的可维护性或安全性来使代码运行得更快。但这仅适用于应用了所有性能模式和最佳实践的场景,但性能需要进一步提高。
有许多方法可以帮助开发人员在不牺牲任何东西的情况下显着提高应用程序性能。
一次实现 LINQ 查询
当使用写LINQ查询IEnumerable或IQueryable接口,开发者可以兑现(电话ToList,ToArray或类似的方法),要么不立即兑现查询。
缺乏物化允许开发人员懒惰地使用集合。但有时需要多次迭代同一个集合。如果查询不是通过调用ToList方法实现的,多次迭代集合会影响应用程序的性能。
[Benchmark] public void NotMaterializedQueryTest() { var elements = Enumerable.Range(0, 50000000); var filteredElements = elements.Where(element => element % 100000 == 0); foreach (var element in filteredElements) { //some logic } foreach (var element in filteredElements) { //another logic } foreach (var element in filteredElements) { //another logic } }
在此示例中,Where查询未具体化。调用该Where方法只是返回一个实现该IEnumerable接口的对象。该GetEnumerator和MoveNext方法将被称为只有当循环访问的集合foreach循环。
这是一个在定义后立即实现具体化查询的示例:
[Benchmark] public void MaterializedQueryTest() { var elements = Enumerable.Range(0, 50000000); var sw = Stopwatch.StartNew(); var filteredElements = elements.Where(element => element % 100000 == 0).ToList(); //The rest of the code is the same }
以下是性能结果:


正如预期的那样,第二个测试中,查询仅通过调用ToList方法实现一次,运行时间比第一个测试少三倍。
避免隐式线性搜索
线性搜索是最简单的搜索算法之一,它会一一遍历集合中的所有元素,直到找到指定的元素。
尽管开发人员通常不会明确实现线性搜索,但它仍然经常导致性能下降。
[Benchmark] public void LinearSearchTest() { var userIds = Enumerable.Range(0, 10000000); int userIdToFind = 9193513; var userExists = userIds.Any(u => u == userIdToFind); }
在这个例子中,Anymethod 使用线性搜索算法来检查指定的用户 ID 是否在集合中。
开发人员不一定需要知道他们使用的每一个的实现。了解基础知识很重要:在 .NET 中,List<T>集合基于数组。在未排序数组中查找值时,其复杂度为 O(n)。无论使用哪种 LINQ 方法在数组中查找值,Any, Contains or Where,复杂性都保持不变。
我们特定问题的解决方案是使用适合特定任务的数据结构。
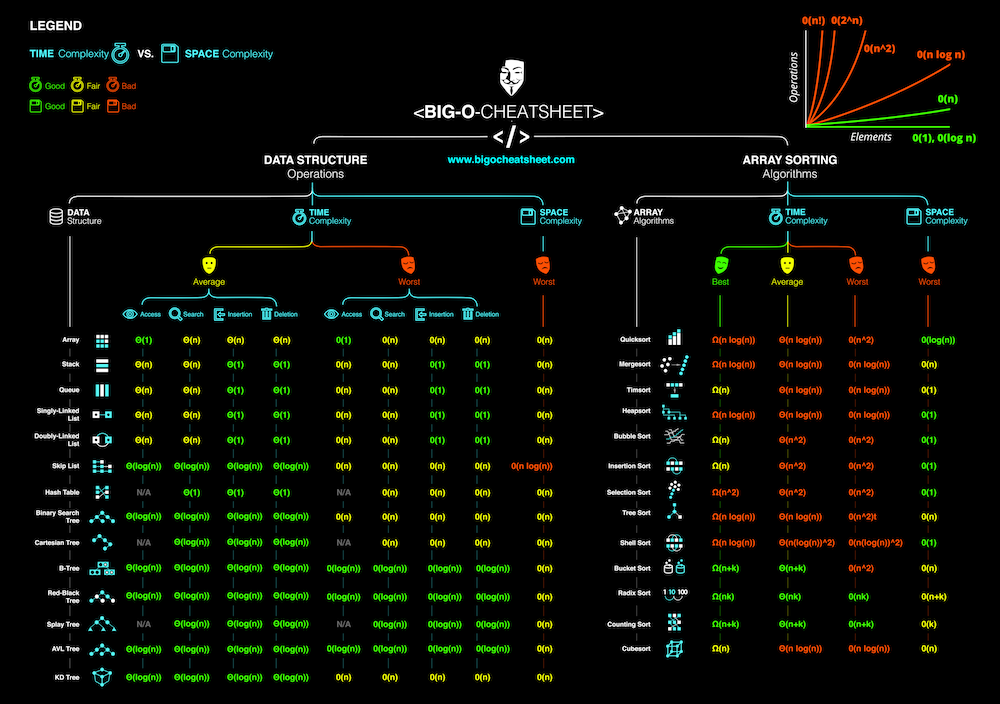
了解你的复杂性!
你好呀!该网页涵盖了计算机科学中常用算法的空间和时间大 O 复杂性。什么时候…
www.bigocheatsheet.com
在我们的例子中,我们拥有始终唯一的用户标识符。它允许我们将集合转换为HashSet<T>.
[Benchmark] public void HashSetTest() { var userIds = Enumerable.Range(0, 10000000).ToHashSet(); int userIdToFind = 9193513; var userExists = userIds.Contains(userIdToFind); }

发生了什么?HashSetTest比慢 5 倍LinearSearchTest.这是因为我们还在测量构建HashSet<T>集合的时间,这对于大型集合来说是一项耗时的操作。
HashSet只有在计划频繁调用其Contains上的方法时,开发人员才能从转换为。
如果我们将集合创建从性能测试中移出并仅测量找到元素的时间,结果将大不相同。


HashSet<T>与在List<T>集合中查找值相比,在集合中查找值几乎不需要时间。
循环的并行化
通常需要使用循环遍历集合foreach并为每个项目执行一些逻辑。
[Benchmark] public void ForeachTest() { var items = Enumerable.Range(0, 1000).ToList(); foreach (var item in items) { //Simulating long running operation Thread.Sleep(1); } }
在这个例子中,迭代在同一个线程中一个接一个地执行,所以总执行时间将随着集合大小线性增长。
通过开始使用foreach框架提供给开发人员的循环的并行版本,可以提高性能。
[Benchmark] public void ParallelForeachTest() { var items = Enumerable.Range(0, 1000).ToList(); Parallel.ForEach(items, (item) => { //Simulating long running operation Thread.Sleep(1); }); }
Parallel.Foreach可以在任何实现IEnumerable<T>接口的集合上使用,就像常规foreach循环一样。a 的实现Parallel.Foreach会代替开发人员做很多工作:将集合拆分成块,在单独的线程中调度和执行块。
这是并行版本与普通版本的foreach循环之间的性能比较:


如果集合很小,单次迭代的执行时间很快,切换foreach到Parallel.Foreach甚至可能会导致性能变差,特别是当开发人员由于访问共享资源而使用线程同步时。
Parallel该类提供的功能是相互独立且不需要使用同步原语(例如并发集合)的长时间运行迭代的绝佳选择。
在某些情况下使用结构而不是类
开发人员通常可能需要分配一个数组或List<T>在内存中存储数万个对象。这个任务可以使用类或结构来解决。
public class PointClass { public int X { get; set; } public int Y { get; set; } } public struct PointStruct { public int X { get; set; } public int Y { get; set; } } [Benchmark] public void ListOfObjectsTest() { const int length = 1000000; var items = new List<PointClass>(length); for (int i = 0; i < length; i++) { items.Add(new PointClass() { X = i, Y = i }); } } [Benchmark] public void ListOfStructsTest() { const int length = 1000000; var items = new List<PointStruct>(length); for (int i = 0; i < length; i++) { items.Add(new PointStruct() { X = i, Y = i}); } }
正如我们所看到的,ListOfObjectTest和之间的唯一区别ListOfStructsTest是第一个测试创建类的实例,而第二个测试创建结构的实例。的代码PointClass与 的代码相同PointStruct.


使用结构的代码比使用类的代码运行速度快 15 倍。存在如此大的时间差异是因为在类的情况下,CLR 必须将一百万个对象分配给托管堆并将它们的引用存储回List<T>集合。在结构的情况下,将唯一分配到托管堆中的对象是List<T>集合的实例。一百万个结构将嵌入到该单个集合实例中。更多关于它的信息:
为什么 List<Struct> 在 C# 中的分配速度比 List<Class> 快 15 倍
在上一篇文章《免费提高 C# 代码性能的 5 种方法》中,在其中一个示例中,我测量了……
levelup.gitconnected.com
指定集合的容量
让我们看看下面两个几乎相同的方法:
[Benchmark] public void NonFixedCapacityTest() { var items = new List<decimal>(); for (int i = 0; i < 1000000; i++) { items.Add(i); } } [Benchmark] public void FixedCapacityTest() { const int capacity = 1000000; var items = new List<decimal>(capacity); for (int i = 0; i < capacity; i++) { items.Add(i); } }
两种方法都完成相同的任务——使用foreach循环用整数填充集合。唯一的区别是在FixedCapacityTest方法中构造函数被初始化为某个数字。这个简单的技巧使该方法的FixedCapacityTest运行速度是该方法的两倍NonFixedCapacityTest


性能提高了两倍,因为List<T>它以将元素存储在数组中的方式实现,这是一个固定大小的数据结构。当开发人员在List<T>未指定其容量的情况下进行实例化时,会分配一个默认容量数组。当数组已满时,会分配一个新的更大的数组,并将旧数组中的值复制到新数组中。
提前指定容量可以消除旧数组的分配、复制和垃圾回收的开销。如果开发人员事先知道将有多少项添加到集合中,那么指定集合的容量应该是开发人员的默认选择。
容量设置不仅适用于 List 集合,还适用于其他类似的集合Dictionary<TKey, TValue>, HashSet<T>。
最后的想法
之前应用任何建议,如从类转换到结构或foreach到Parallel.ForEach,运行探查,以确保问题确实存在。
始终仔细分析您的具体情况,并做出最适合您的选择。
我的其他文章:
NetArchTest — 在您的应用程序中执行架构和设计规则
通过编写单元测试。
levelup.gitconnected.com
如何专业地对错误修复进行代码审查
在检查错误修复时要问的几个重要问题。
levelup.gitconnected.com
在 C# 中实现单例设计反模式的 5 种方法
各有利弊
levelup.gitconnected.com
而以,像 STL 重头戏的 traits 是无法使用的了(不过 sf.net 上有一个 CSTL
(C# STL)的项目,初具形状)。
.NET 2.0 加入了一系列的泛型容器,如 List,Dictionary<key, <br="">Value> 等。这些容器对于引用(Object 及子类)类型和原生数据类型(如 int,
double 等)支持得很好,然而对 struct 类型的元素的支持却有问题。这里所说
的问题是指,List 并不能对等的代替 T[]。struct 类型的问题在于,你不能
直接修改 List 中元素的成员。
产生问题的原因在于,C# 只有针对“对象”的引用,而没有 C++ 那样针对
值类型的引用。struct T 是值类型,所以你在索引 List 元素的时候,
返回的只是元素的一个值拷贝。自然,你对这个拷贝的成员的修改不会影响到真
实的元素。幸运的是,C# 编译器禁止这种操作。代码如下:
struct T
{
public int a;
}
List list;
list.Add(new T());
list[0].a = 100; // 编译错误!!
// 实际你要这样做:
T t = list[0];
t.a = 100;
list[0] = t;
在上面的代码里,我的解决办法是复制到一个临时变量,修改值,然后回写。
为什么不能修改真实的元素,考虑如下代码:
public T this[int index]
{
get
{
T t = list[index];
return t; // 返回的是拷贝,不是吗?
}
}
https://stackoverflow.com/questions/11448421/c-sharp-list-and-memory
数组(ArrayPool数组池、Span<T>结构)
对资源的可复用是提高应用程序性能的一个很是重要的手段,好比本篇要分享的 ArrayPool 和 MemoryPool,它们就有效的减小了内存使用和对GC的压力,从而提高应用程序性能。html
什么是 ArrayPool
System.Buffers 命名空间下提供了一个可对 array 进行复用的高性能池化类 ArrayPool<T>,在常常使用 array 的场景下可以使用 ArrayPool<T> 来减小内存占用,它是一个抽象类,以下代码所示:数组
public abstract class ArrayPool<T>
{
}
能够想象一下你的业务场景中须要屡次实例化 array,这么作有什么后果呢? 很显然每一次 new array 都会在托管堆上分配,同时当 array 再也不使用时还须要 GC 去释放,而 ArrayPool<T> 就是为了解决此事而生的,它在池中动态维护若干个 array 对象,当你须要 new array 的时候只需从池中获取便可。ide
使用 ArrayPool<T>
能够经过下面三种方式来使用 ArrayPool<T> 。性能
-
经过
ArrayPool<T>.Shared属性来获取ArrayPool<T>实例。code -
经过
ArrayPool<T>.Create()来生成ArrayPool<T>实例。htm -
经过继承
ArrayPool<T>来生成一个自定义子类。对象
下面的代码展现了如何从 ArrayPool 中获取一个 size >= 10 的 array 数组。blog
var shared = ArrayPool<int>.Shared;
var rentedArray = shared.Rent(10);

上面的代码必定要注意,虽然只租用了 10 个 size,但底层会返回 2的倍数 的size , 也就是图中的 2* 8 = 16。继承
当何时不须要 rentedArray 了,记得再将它归还到 ArrayPool 中,以下代码所示。内存
shared.Return(rentedArray);
下面是仅供参考的完整代码。
static void Main(string[] args)
{
var shared = ArrayPool<int>.Shared;
var rentedArray = shared.Rent(10);
for (int i = 0; i < 10; i++)
{
rentedArray[i] = i + 1;
}
for (int j = 0; j < 10; j++)
{
Console.WriteLine(rentedArray[j]);
}
shared.Return(rentedArray);
Console.ReadKey();
}
建立自定义的 ArrayPool
你也能够经过重写 ArrayPool 来实现自定义的池化对象,以下代码所示:
public class CustomArrayPool<T> : ArrayPool<T>
{
public override T[] Rent(int minimumLength)
{
throw new NotImplementedException();
}
public override void Return(T[] array, bool clearArray = false)
{
throw new NotImplementedException();
}
}
使用 MemoryPool<T>
System.Memory 命名空间下提供了一个内存池对象 MemoryPool<T>,在这以前你须要每次都 new 一个内存块出来,同时也增长了 GC 的负担,有了 MemoryPool<T> 以后,你须要的内存块直接从池中拿就能够了。
static void Main(string[] args)
{
var memoryPool = MemoryPool<int>.Shared;
var rentedArray = memoryPool.Rent(10);
for (int i = 0; i < 10; i++)
{
rentedArray.Memory.Span[i] = i + 1;
}
for (int j = 0; j < 10; j++)
{
Console.WriteLine(rentedArray.Memory.Span[j]);
}
Console.ReadKey();
}
ArrayPool<T> vs MemoryPool<T>
从上面的演示能够看出, ArrayPool<T> 是以 array 的形式向外租借,而 MemoryPool<T> 则是以 内存块 的方式向外租借,因此在重复使用 array 的场景下能够优选 ArrayPool<T> 来提升性能,若是你的代码是以 Memory<T> 这种内存块的形式屡次使用则优先使用 MemoryPool<T>。
https://www.shangmayuan.com/a/eb09b5757f4642d1a4ca8b92.html
https://stackoverflow.com/questions/23032494/performance-of-liststruct-vs-listclass
软件开发是关于寻找折衷方案的:Software development is about finding trade-offs:

https://www.bigocheatsheet.com/
Know Thy Complexities!
了解你的复杂性
Hi there! This webpage covers the space and time Big-O complexities of common algorithms used in Computer Science. When preparing for technical interviews in the past, I found myself spending hours crawling the internet putting together the best, average, and worst case complexities for search and sorting algorithms so that I wouldn't be stumped when asked about them. Over the last few years, I've interviewed at several Silicon Valley startups, and also some bigger companies, like Google, Facebook, Yahoo, LinkedIn, and Uber, and each time that I prepared for an interview, I thought to myself "Why hasn't someone created a nice Big-O cheat sheet?". So, to save all of you fine folks a ton of time, I went ahead and created one. Enjoy! - Eric
你好啊!本网页介绍了计算机科学中常用算法的时空复杂性。在过去准备技术面试的时候,我发现自己花了好几个小时在互联网上爬行,把搜索和排序算法的最佳、平均和最差情况下的复杂性放在一起,这样我就不会在被问到它们时被难住了。在过去的几年里,我采访了几家硅谷的创业公司,还有一些更大的公司,比如谷歌(Google)、 Facebook、雅虎(Yahoo)、领英(LinkedIn)和优步(Uber)。每次我为采访做准备的时候,我都会问自己,“为什么没有人制作一份漂亮的大 o 小抄呢?”.所以,为了节省你们这些优秀的人们大量的时间,我继续创造了一个。享受吧!埃里克
Check out El Grapho, a graph data visualization library that supports millions of nodes and edges
查看 El Grapho,一个支持数百万个节点和边的图形/数据可视化库
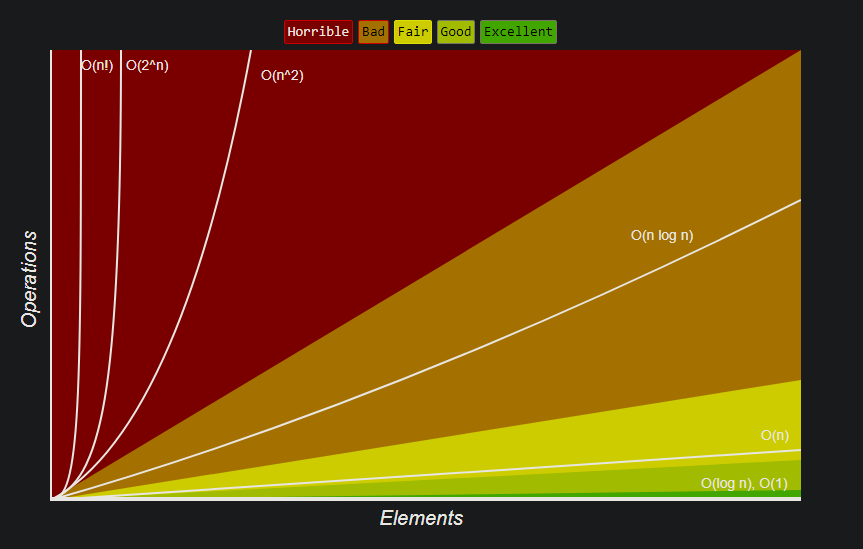
Big-O Complexity Chart
大 o 型复杂性图表
Horrible |
Bad |
Fair |
Good |
Excellent |
Common Data Structure Operations
通用数据结构操作
| Data Structure 数据结构 | Time Complexity 时间复杂性 | Space Complexity 空间复杂性 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Average 平均数 | Worst 最糟糕的 | Worst 最糟糕的 | |||||||
| Access 访问 | Search 搜寻 | Insertion 插入 | Deletion 删除 | Access 访问 | Search 搜寻 | Insertion 插入 | Deletion 删除 | ||
| Array 数组 | Θ(1) |
Θ(n) |
Θ(n) |
Θ(n) |
O(1) |
O(n) |
O(n) |
O(n) |
O(n) |
| Stack 斯塔克 | Θ(n) |
Θ(n) |
Θ(1) |
Θ(1) |
O(n) |
O(n) |
O(1) |
O(1) |
O(n) |
| Queue 排队 | Θ(n) |
Θ(n) |
Θ(1) |
Θ(1) |
O(n) |
O(n) |
O(1) |
O(1) |
O(n) |
| Singly-Linked List 单向链表 | Θ(n) |
Θ(n) |
Θ(1) |
Θ(1) |
O(n) |
O(n) |
O(1) |
O(1) |
O(n) |
| Doubly-Linked List 双向链表 | Θ(n) |
Θ(n) |
Θ(1) |
Θ(1) |
O(n) |
O(n) |
O(1) |
O(1) |
O(n) |
| Skip List 跳过列表 | Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
O(n) |
O(n) |
O(n) |
O(n) |
O(n log(n)) |
| Hash Table 哈希表 | N/A |
Θ(1) |
Θ(1) |
Θ(1) |
N/A |
O(n) |
O(n) |
O(n) |
O(n) |
| Binary Search Tree 二叉查找树 | Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
O(n) |
O(n) |
O(n) |
O(n) |
O(n) |
| Cartesian Tree 笛卡尔树 | N/A |
Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
N/A |
O(n) |
O(n) |
O(n) |
O(n) |
| B-Tree B 型树 | Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
O(log(n)) |
O(log(n)) |
O(log(n)) |
O(log(n)) |
O(n) |
| Red-Black Tree 红黑树 | Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
O(log(n)) |
O(log(n)) |
O(log(n)) |
O(log(n)) |
O(n) |
| Splay Tree 张开树 | N/A |
Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
N/A |
O(log(n)) |
O(log(n)) |
O(log(n)) |
O(n) |
| AVL Tree | Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
O(log(n)) |
O(log(n)) |
O(log(n)) |
O(log(n)) |
O(n) |
| KD Tree | Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
Θ(log(n)) |
O(n) |
O(n) |
O(n) |
O(n) |
O(n) |
Array Sorting Algorithms
数组排序算法
| Algorithm 算法 | Time Complexity 时间复杂性 | Space Complexity 空间复杂性 | ||
|---|---|---|---|---|
| Best 最好的 | Average 平均数 | Worst 最糟糕的 | Worst 最糟糕的 | |
| Quicksort 快速排序 | Ω(n log(n)) |
Θ(n log(n)) |
O(n^2) |
O(log(n)) |
| Mergesort | Ω(n log(n)) |
Θ(n log(n)) |
O(n log(n)) |
O(n) |
| Timsort 时间排序 | Ω(n) |
Θ(n log(n)) |
O(n log(n)) |
O(n) |
| Heapsort | Ω(n log(n)) |
Θ(n log(n)) |
O(n log(n)) |
O(1) |
| Bubble Sort 冒泡排序 | Ω(n) |
Θ(n^2) |
O(n^2) |
O(1) |
| Insertion Sort 插入排序 | Ω(n) |
Θ(n^2) |
O(n^2) |
O(1) |
| Selection Sort 选择排序 | Ω(n^2) |
Θ(n^2) |
O(n^2) |
O(1) |
| Tree Sort 树排序 | Ω(n log(n)) |
Θ(n log(n)) |
O(n^2) |
O(n) |
| Shell Sort | Ω(n log(n)) |
Θ(n(log(n))^2) |
O(n(log(n))^2) |
O(1) |
| Bucket Sort 斗式排序 | Ω(n+k) |
Θ(n+k) |
O(n^2) |
O(n) |
| Radix Sort 基数排序 | Ω(nk) |
Θ(nk) |
O(nk) |
O(n+k) |
| Counting Sort 计数排序 | Ω(n+k) |
Θ(n+k) |
O(n+k) |
O(k) |
| Cubesort 立方体 | Ω(n) |
Θ(n log(n)) |
O(n log(n)) |
O(n) |
Learn More
了解更多
- Cracking the Coding Interview: 150 Programming Questions and Solutions 破解编程面试: 150个编程问题及解决方案
- Introduction to Algorithms, 3rd Edition 算法导论,第三版
- Data Structures and Algorithms in Java (2nd Edition) Java (第二版)中的数据结构和算法
- High Performance JavaScript (Build Faster Web Application Interfaces) 高性能 JavaScript (构建更快的 Web 应用程序接口)
Get the Official Big-O Cheat Sheet Poster
获得官方大 o 作弊海报