我们以我的博客为例,来爬取我所有写过的博客的标题。
首先,打开我的博客页面,右键“检查”开始进行网页分析。我们选中博客标题,再次右键“检查”即可找到标题相应的位置,我们继续点击右键,选择Copy,再点击Copy XPath,即可获得对应的XPath编码,我们可以先将它保存在一个文本文档中。
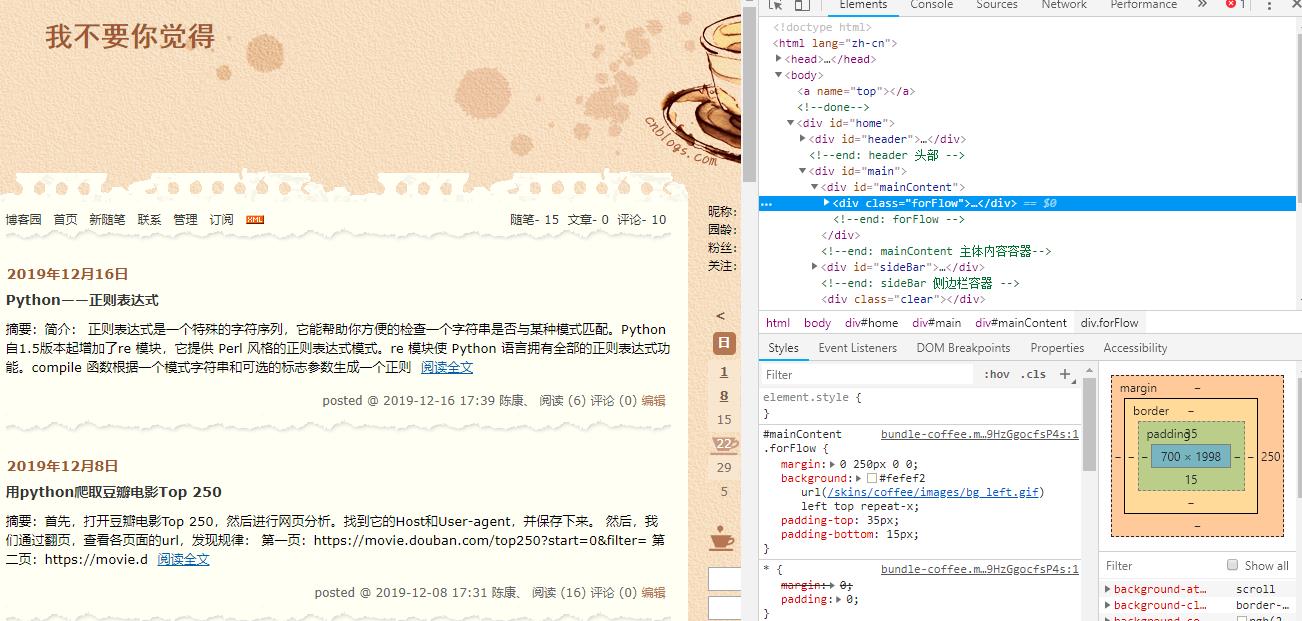
我们再多次对各个标题重复以上操作,即可得到关于标题的XPath编码的规律。我们不难看出,对于我的博客的标题的XPath编码格式为“//*[@id="mainContent"]/div/div[n]/div[2]/a”。
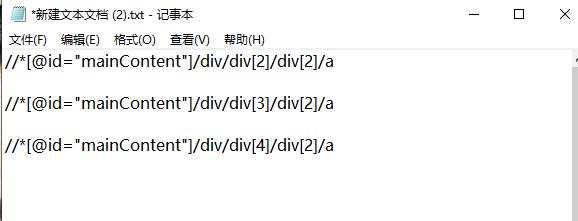
又因为我的博客共有2页,所以我们还需找到网页url的规律,经过分析,我们发现格式为'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1)。
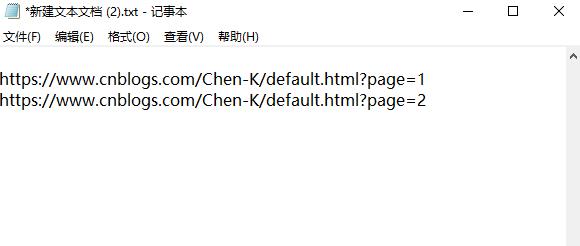
下面便可开始写代码:
import requests from lxml import etree for i in range(0,2): url = 'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1) html = requests.get(url) etree_html = etree.HTML(html.text) a = etree_html.xpath('//*[@id="mainContent"]/div/div/div[2]/a/text()') # 加text()是为了将结果以txt格式输出 for j in a: print(j)
运行结果:

若是要爬取其他的数据,我们只需复制下来相应的XPath编码即可。操作过程大同小异,我们便不再多加赘述,下面我们以爬取每个博客的url为例:
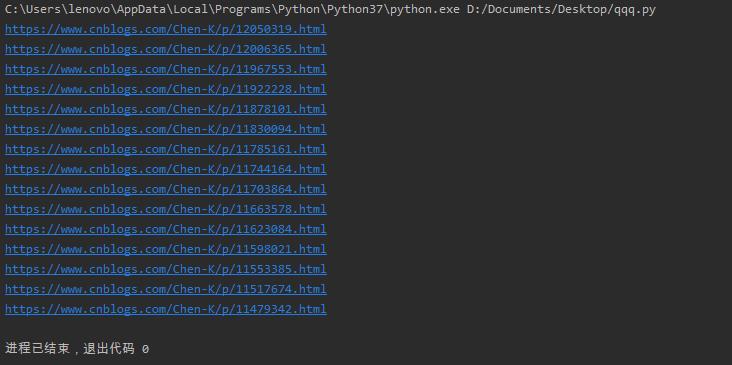
import requests from lxml import etree for i in range(0,2): url = 'https://www.cnblogs.com/Chen-K/default.html?page='+str(i+1) html = requests.get(url) etree_html = etree.HTML(html.text) a = etree_html.xpath('//*[@id="mainContent"]/div/div/div[2]/a/@href') for j in a: print(j)
运行结果:
XPath与BeautifulSoup相比,操作更加简单,代码也更为简洁,如果需要爬取比较多的信息,使用XPath将会大大减少我们的工作量。当然,我们想要使用XPath,必须先安装lxml库,而我们有两个方法可以安装lxml库。
1、使用pip安装
我们只需打开命令行,输入指令“pip install lxml”,然后等待安装即可。
2、使用PyCharm安装
我们点击“文件”,找到设置,打开后点击右边的加号,然后在上面的搜索框中输入lxml,然后点击下方install,等待安装即可。
安装好lxml库之后,我们便可以使用其相关功能了。