VGGish
通过阅读帮助文档,知道可以VGGish是产生128维音频数据集的工具,原文的描述是这样的: VGGish, as well as supporting code to extract input features for the model from audio wavaforms and post-process the model enmbedding output int the same fomat.
输入:音频特征
1.所有的音频都被重采样为16KHz的单声道形式。
2.使用 25ms 的帧长、10ms 的帧移,以及周期性的 Hann 窗口对语音进行分帧,对每一帧做短时傅里叶变换,然后利用信号幅值计算声谱图。
3.通过将声谱映射到 64 阶 mel 滤波器组(covering the range 125-7500 Hz.)中计算 mel 声谱.
4.计算 log(mel-spectrum + 0.01),得到稳定的 mel 声谱,所加的 0.01 的偏置是为了避免对 0 取对数。
5.然后这些特征被以 0.96s 的时长被组帧,并且没有帧的重叠,每一帧都包含 64 个 mel 频带,时长 10ms(即总共 96 帧)。
测试安装的VGGish是否成功
vgg_smoke_test.py 程序的checkpoint_path和pac_params_path需要根据你的放置的位置进行修改。在Anaconda Prompt直接执行
E://Audio_project//VGGish//vggish_smoke_test.py
运行该测试程序
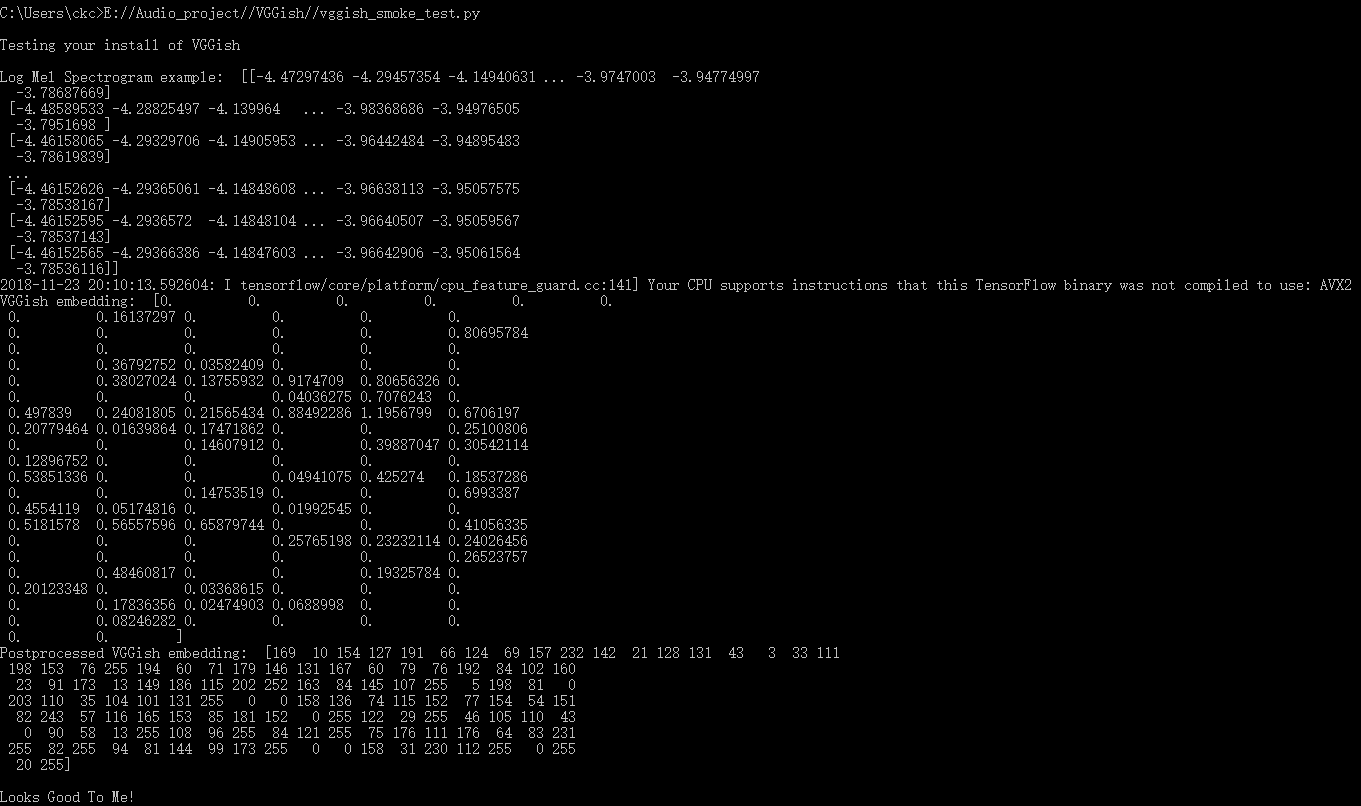
测试完成!可以发现VGGish embedding:的结果和Postprocessed VGGish embedding:的结果都是128维的。
通过这一部分测试代码可以知道:
1.测试的音频是1K的正弦波,然后进行44.1Khz的采样。
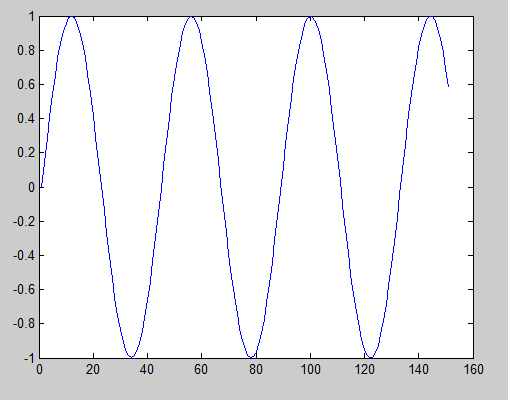
2.然后执行产生log mel 声谱
input_batch = vggish_input.waveform_to_examples(x, sr)
之后经过VGGish后128维的数据:

之后再将此数据进行PCA变换: