概念
神经网络的深度和数据据体的深度(图像的通道数channels)要主要区分。
输入
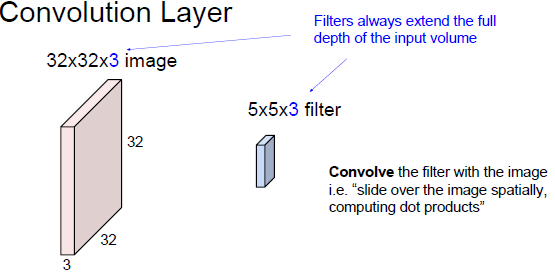
1.得到一些数据,作为网络的输入。
2.在CNN中有filter,the size of filter is small。如上的filter为5*5,深度为3,这个3要在深度上穿过
输入数据的每一个位置,输入数据是三个通道;
3.filter 要完全覆盖输入数据的全部深度,用filter来和输入图像做卷积运算。
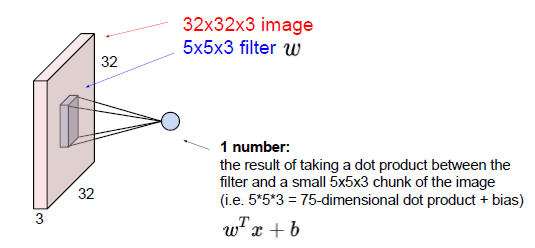 filter要在整个图像的空域范围内全部位置滑动,每一个位置filter和图像做点乘。这个filter是要学习的用W表示,我们也要学习这些filter,可以把filter看作是你的一堆W,然后在图像范围内滑动这个filter。
filter要在整个图像的空域范围内全部位置滑动,每一个位置filter和图像做点乘。这个filter是要学习的用W表示,我们也要学习这些filter,可以把filter看作是你的一堆W,然后在图像范围内滑动这个filter。
as folllows:
$w^{T}x + b$
where w denotes the filter and x denotes the patch of input image, 大小是5*5*3的小区域。
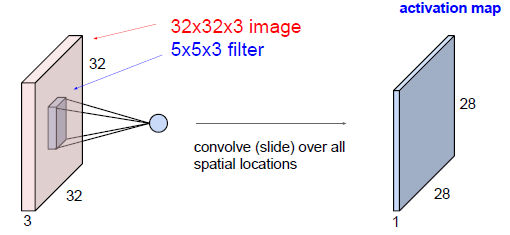
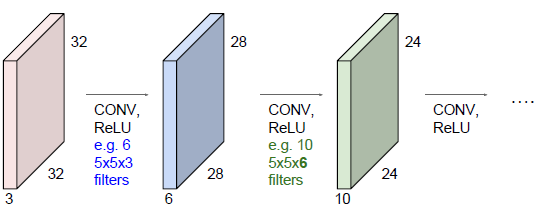
激活图给出了每个空间位置出滤波器的反应,将5*5的filter在32*32的输入数据上滑动,得到了28*28的激活图。
hei = 32; wid = 32; stride = 1; count = 0; step1 = 0; step2 = 0; pathchSize = 5; for x = 1 + step1: stride : hei - patchSize + 1 for y = 1 + step2 : stride : wid - patchSize +1 count = count + 1; end end out >>> count = 784 >>> 28 * 28
另一个滤波器与第一次滤波器计算无关,所以的滤波器都是相互独立的,假设有六个filter,然后输入数据每一个独立的计算与六个滤波器点乘,这个过程成为卷积运算,得到了一组28*28*6的激活图组,把他们沿着深度方向存储在一起。
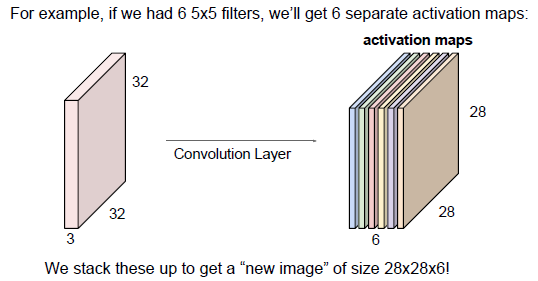
操作:遍历这幅图像,重新表示这幅32*32的图像,表示为了28*28*6,又作为了后续层的输入,后一个filter为5*5*6(为了保持了输入的深度一致),假设有10个独立的filter做线性运算
感性的认识这些操作的意义
CNN最后会构建整个特征层级

随着网络的加深,组合成更大的特征块,用小的特征块组合在一起。所以初始值随机,空间上组合这个特征。
filters的堆叠
将滤波器产生的激活图沿着深度方向组合起来,然后把这些图作为下一个卷积层的输入,也就是不断的做这些图的组合。
Conv的大体布局
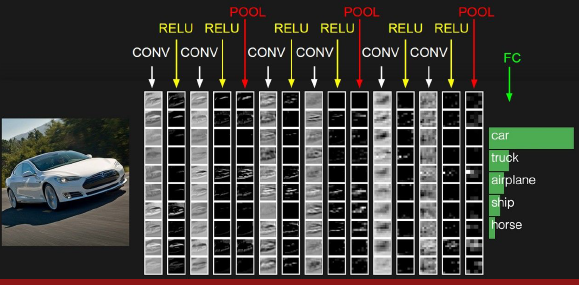
从图中可以看到大概为三个部分:
1. 卷积层 2.Relu层 (非线性变换层,进行阈值处理也是控制过拟合的方式) 3. 池化层pooling
一列中的每一行是一个激活图,每一个卷积层有10个滤波器
filter的不同尺寸和步长(stride)对于得到的激活图的尺寸
1.计算可以取多少个patch的公式:
hei = ?; wid = ?; stride = ?; count = 0; step1 = 0; step2 = 0; pathchSize = ?; for x = 1 + step1: stride : hei - patchSize + 1 for y = 1 + step2 : stride : wid - patchSize +1 count = count + 1; end end
2.计算输出的激活图的尺寸
$Result = (N-F)/Stride + 1$
where Result should be integer.
3.常用图像的填充(pad)
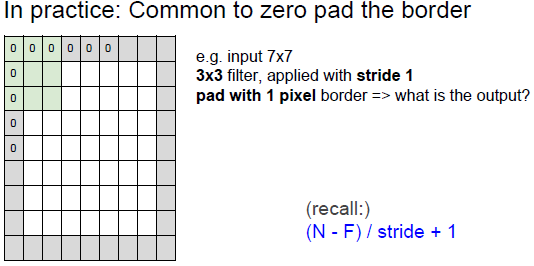 1.填充的默认值为0;
1.填充的默认值为0;
2.如果加上一圈边缘之后再做卷积,输出尺寸和输入尺寸一样大,这是我们想要的结果,这对于设计神经网络架构十分好,空间大小不变的性质。
3.对于3*3的滤波器,需要1圈才能保持空间大小不变,对于广义的F的大小,如何使空间大小不变呢?需要考虑填充的大小:

4.使用5*5的filter 会发现图像尺寸会随着时间的推进而变小,这是个不好的性质,尺寸从32-》28-》24,空间尺寸变小的速度非常快,我们不想让我们的图像尺寸减小的太快,我们希望做很大大小不会缩小的卷积层,用更少的数字表现原来的图像;希望表达的尺寸不变。
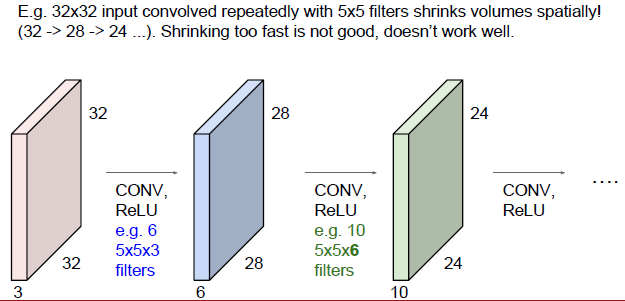
5.参数的计算

6.卷积层的总结:每次接收到的输入数据尺寸为W1*H2*D1,输出尺寸为W2*H2*D2;卷积层的四个超参数:
(1)K 是filter的数量(也表示卷积后的深度,总是2的指数,e,g,32 64 128 512,因为有时候会进入特殊的高效的计算流程,使用向量化表示,这是使用2的指数的原因)
(2)空间的延生F:经常3*3 S=1 空间尺寸不变、或者5*5 S=2 空间尺寸不变;filter的尺寸总是奇数,奇数尺寸的filter有更好的表达,3是有意义的最小尺寸了。
(3)步长S
(4)zero-padding的数量P
7.特例:1*1的卷积,每个滤波器在整个深度方向上做点乘,在整个深度方向上做64维的点乘,再做阈值化处理,有意义。

8.输入深度取决于你的图像通道,输出深度取决于你有多少个滤波器,比较重要的两个词:共享参数和局域连接;也就是说神经元在一个激活映射中共享相同的权值, 我们有5个不同的滤波器,结果从整体上观察数据,你有排列在3维空间中的神经元体,全部以一个局域模式,共享参数的状态关注着同一个数据体。
但是在深度方向上,它们都有不同的神经元,都有着输入数据体的相同的部分,它们的权重不同,它们各自和自己相同层的小伙伴分享权重。
局域连接和参数共享的优点是可以从视觉上控制模型能力,神经元在平面上想要计算相似的东西,例如小的边缘,这样的功能有意义。
下采样
空间尺寸的减小通常是在下采样层进行的。
直观概念:下采样层就是把输入数据拿过来,通过下采样达到空间上压缩的目的,下采样在每个激活映射中独立进行,as follows:
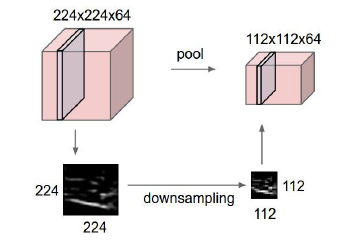
1.max pooling(效果最好的)
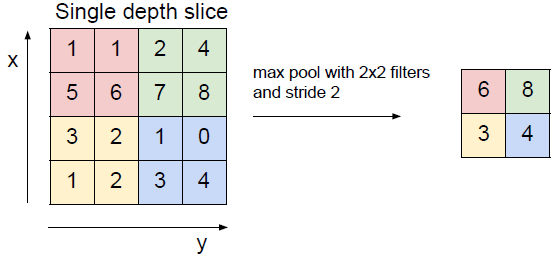
需要知道的下采样的超参数包括: 步长、filter的尺寸,深度保持不变。
全连接层(FC layer)
AlexNet
注意池化层没有参数,只有卷积层才有参数。
当在进行反向传播时一定要小心,因为参数是共享的,当你在用filter做卷积时,所有神经元都共享参数,你必须小心所有filter的梯度都汇总到一个权重
blob,

ZFNet
VGGNet
在filter的大小等参数上做了很多的工作,整个VGG网络只用了3*3卷积核,滑动步长2和2*2的池化窗口,stride为2。

大多数的memory的消耗在前面的卷积部分,而大多数的参数集中在全连接层。
GooLeNet
使用了平均池化,在全连接层前大幅度的减小了参数的规模
Resnet
plain net 随着层数的增长反而错误率降低;按道理来说随着层数的增长,模型的性能应该更好,但是结果却是更坏。我们在优化层数上做的不够好
但是ResNet相反,当你提升层数时,模型的训练错误率和测试错误率上都持续地改进,所以你想用更多层数。
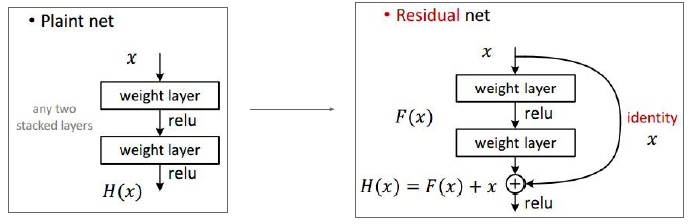
梯度“流经”这些权重并且后向传播,你需要做的是加法处理,加法在这里是分散梯度给所有的两部分,因此梯度会流向之前的一部分,同样也会跳过
这一部分,之间流向输入处,该结构让你的梯度直接从158层的softmax层跳达这里的卷积层,因此你可以训练处离图像很近的这些小层次。中间的这些家伙能够
能够学习到如何加入你的信号使得更有效。
另一种解释是这一层基本上是由默认的恒等运算,这些建立在顶部的恒等上,它只是让它更好的优化。
Resnet的训练

(需要再看下Xavier/2的初始化方法)BN可以使得学习率高一些;
残差网络快速缩减了这个尺寸,它们打包了所有的大小,以便内存存下来更多的层次。