LOSS FUNCTION AND OPLIZATION (来源网易公开课-斯坦福大学 CV课程)
LOSS FUNCTION:
1.W中的每一行都是 某一类的像素值的权重/分类模板,说明对应像素(3072*1)对该类别(猫,狗,汽车)的影响。
2. 而判断权重矩阵(weight matrix)的好坏的函数就是 loss function (学了好久都不知道loss function是用来决定权重矩阵的)
以下是 hinge loss的公式, 表示:
只要 目标类的score比其他类的score高出一个safe_margin的值就可以了,少的值就是 loss
例如,对于一张猫的image,该模型对猫类得分(3.2)比对狗类得分(5.1),蛙类得分(-1.7)高出1分算合格,这里不合格。


2. (补)所以该模型的总 Loss 为该模型所有类预测的loss的平均
SVM_loss_function: 只要正确分类的值高过某个阈值,loss就是0
softmax_loss_function: 正确分类的exp值,占各个分类exp值之和的比重,再加对数。 所以正确分类取值多大,loss 都达不到 0

3. 正则项: 为了防止 Loss function 采用复杂的函数来 拟合training_data,导致overfiting,这里引入了正则项:model should be simple
对高次幂模型的惩罚项
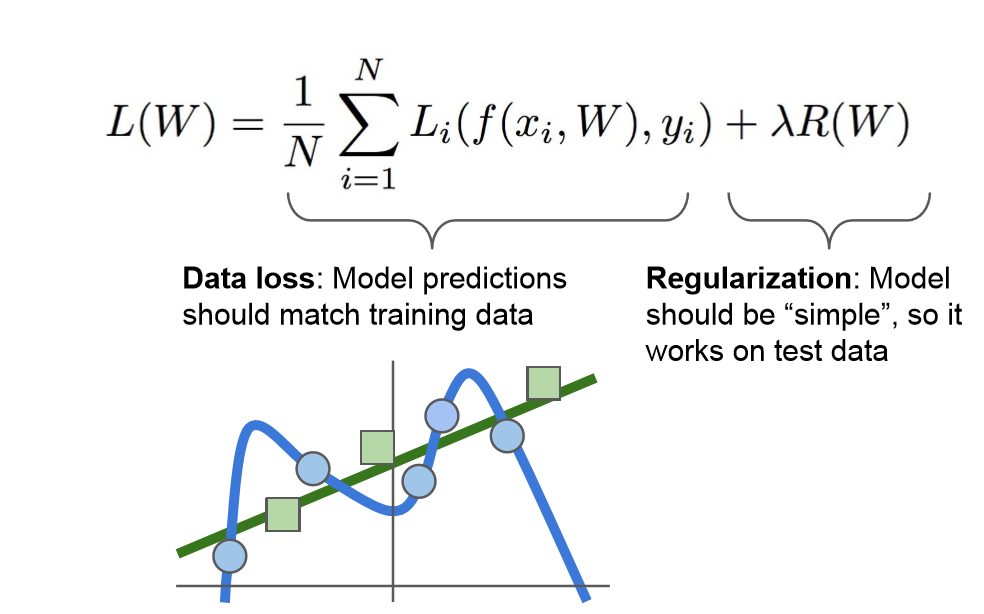

4. loss function 总结

OPLIZATION:
1. 初步想法 numerical gradient 在W的每个维度都前进一个learning rate ,然后通过loss计算出dW,再挑选梯度下降的最多的一个维度
缺点:这样在实际中可能要计算百万次,一次计算百万个维度的 loss ,这样的计算量是不可行的
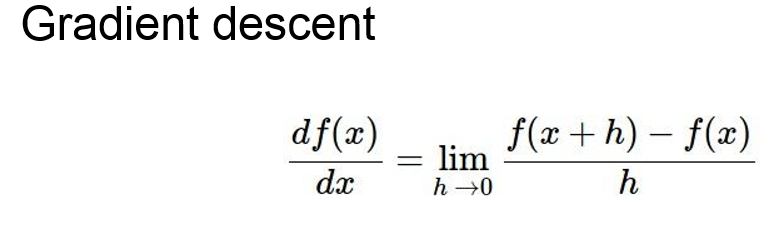

2. analytic gradient 想要得到某个方向的梯度下降速度可以直接求导 dW
缺点: 虽然省去了计算loss 的步骤,但是每一次learning rate的前进还是要计算维度次数(可达百万次)的导数
3. stochastic Gradient Descent (SGD) 随机梯度下降
https://www.zhihu.com/question/264189719