1. 输入 x W -> 算除 scores

2. 计算 该模型的LOSS = hinge loss + regularazation
3. backpropagation
1)用链式规则(chain rule) 求 local gradient 再乘以 upstrean gradient 得到总导数,在给定数值的 时候,这比直接求导f(w,x) 要快得多
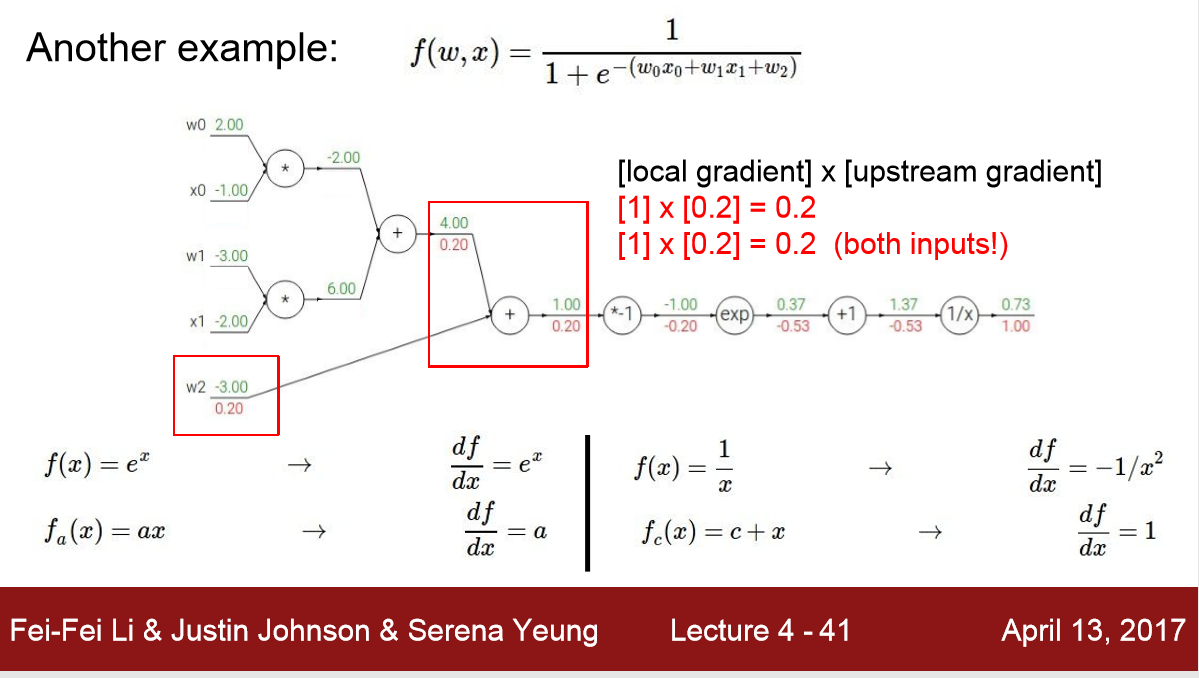
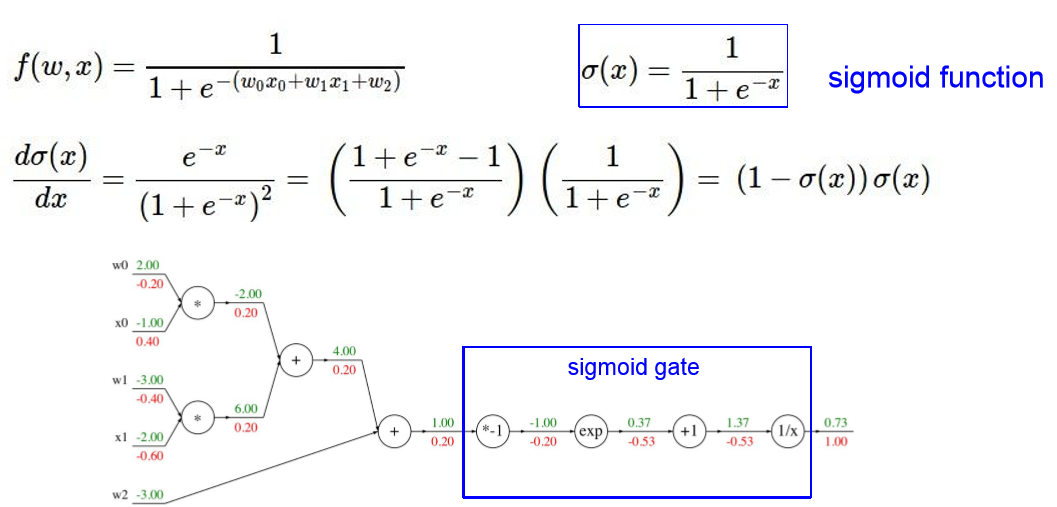
2) 只要知道能算 local gradient 可以创建稍微复杂的nodes ,比如将上面的四个节点组成一个sigmoid节点
3) max()函数的 local gradient : max的那项是 1 ,其余项是0
乘法(a*b)的 local gradient: a的local gradient是b , b的local gradient是a
4) 把前文中的 标量a,b,c变成矩阵的时候, 就要用到Jacobien matrix雅可比矩阵
https://baike.baidu.com/item/%E9%9B%85%E5%8F%AF%E6%AF%94%E7%9F%A9%E9%98%B5/10753754?fr=aladdin
( 如果我们的输入输出为: input 4096d-vector ,output 4096d-vector
并且一次输入100个样本,则我们要计算的雅可比矩阵为 [4096000*4096000]的矩阵,实际中只用到了对角线矩阵?)
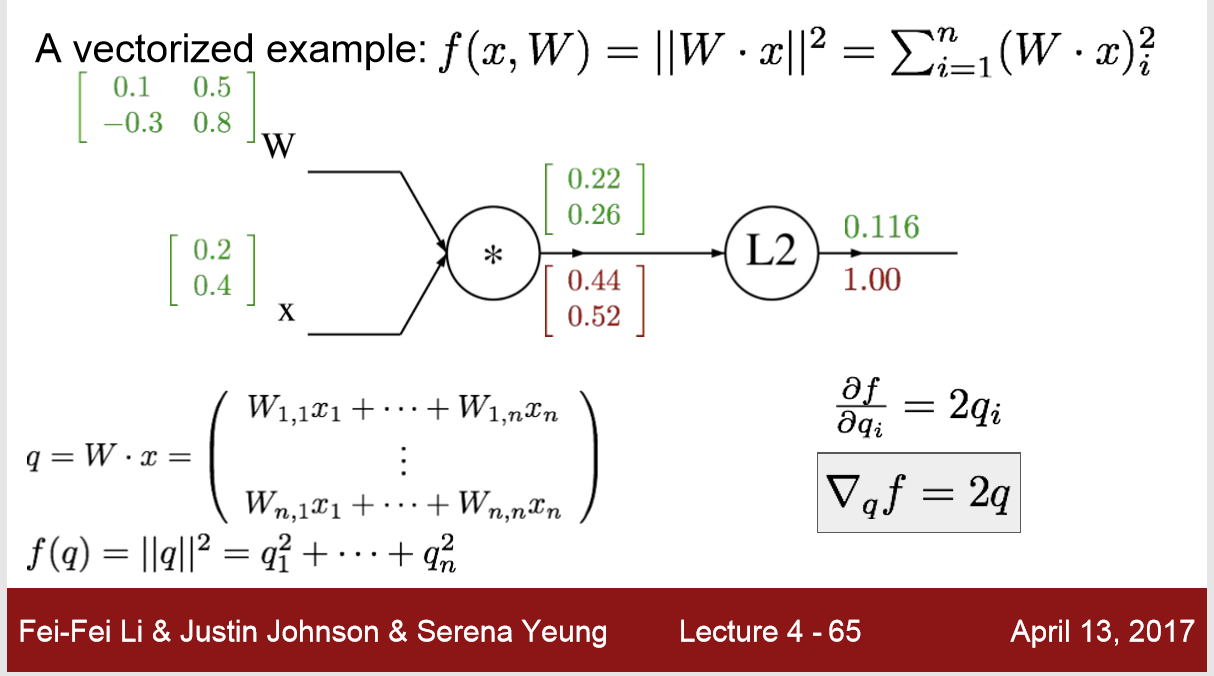
5)
先求矩阵q的 local gradient 都是2qi
再求 q 对 w 和 x 的 local gradient ,乘上 upstream gradient 2qi


6)
forward 计算出 node的值 output
backward 计算偏导 gradient


