ResNet
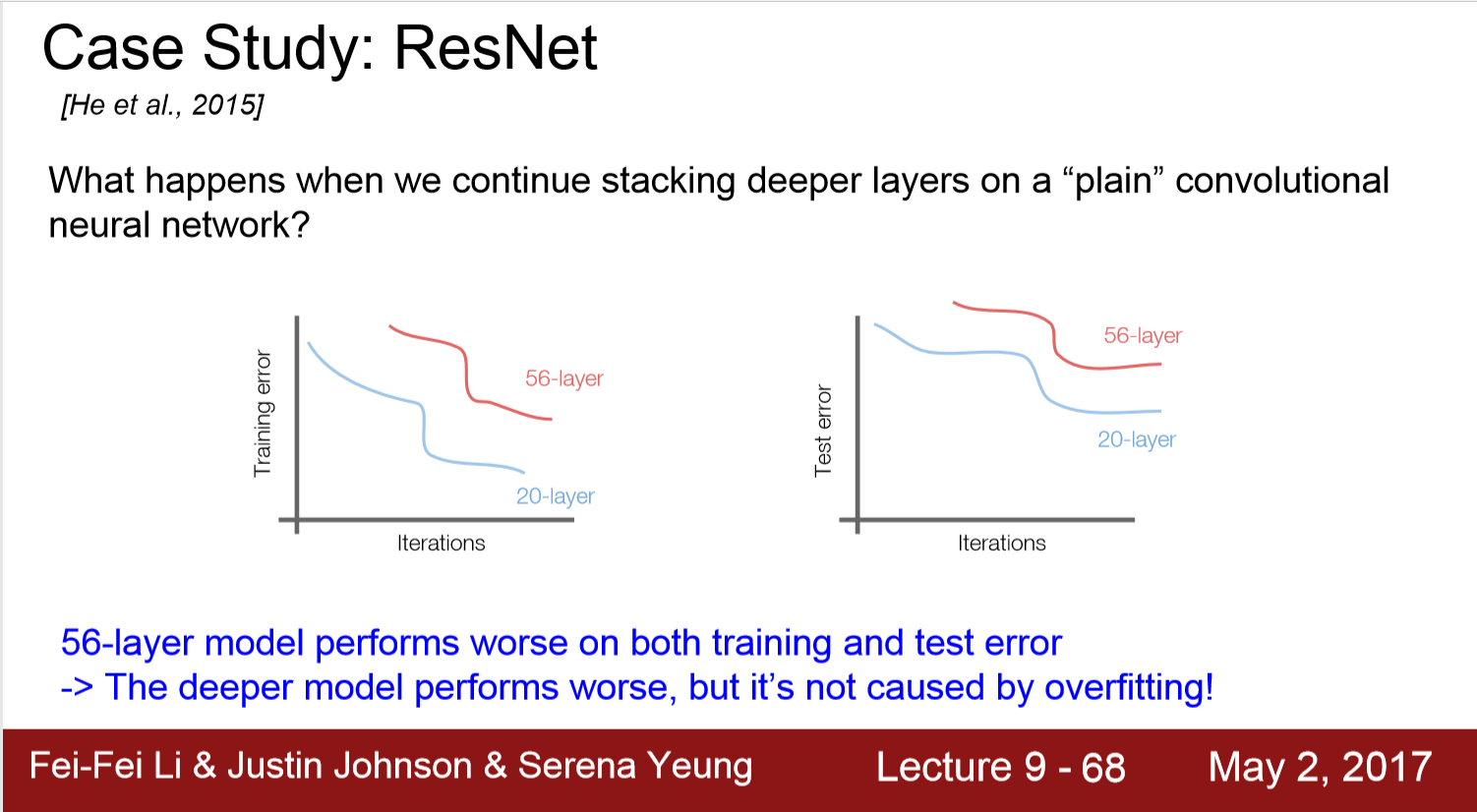
其他不带残差的网络(plain-CNN)中:
56层的网络比20层的网络,无论是trainning set 还是test set都要表现差
问题: 1) 优化问题,梯度在传播过程中出现梯度消失,或者梯度爆炸 2) weight_matrix_decay
1. Batch Normalization,可以解决在forward过程中的梯度消失
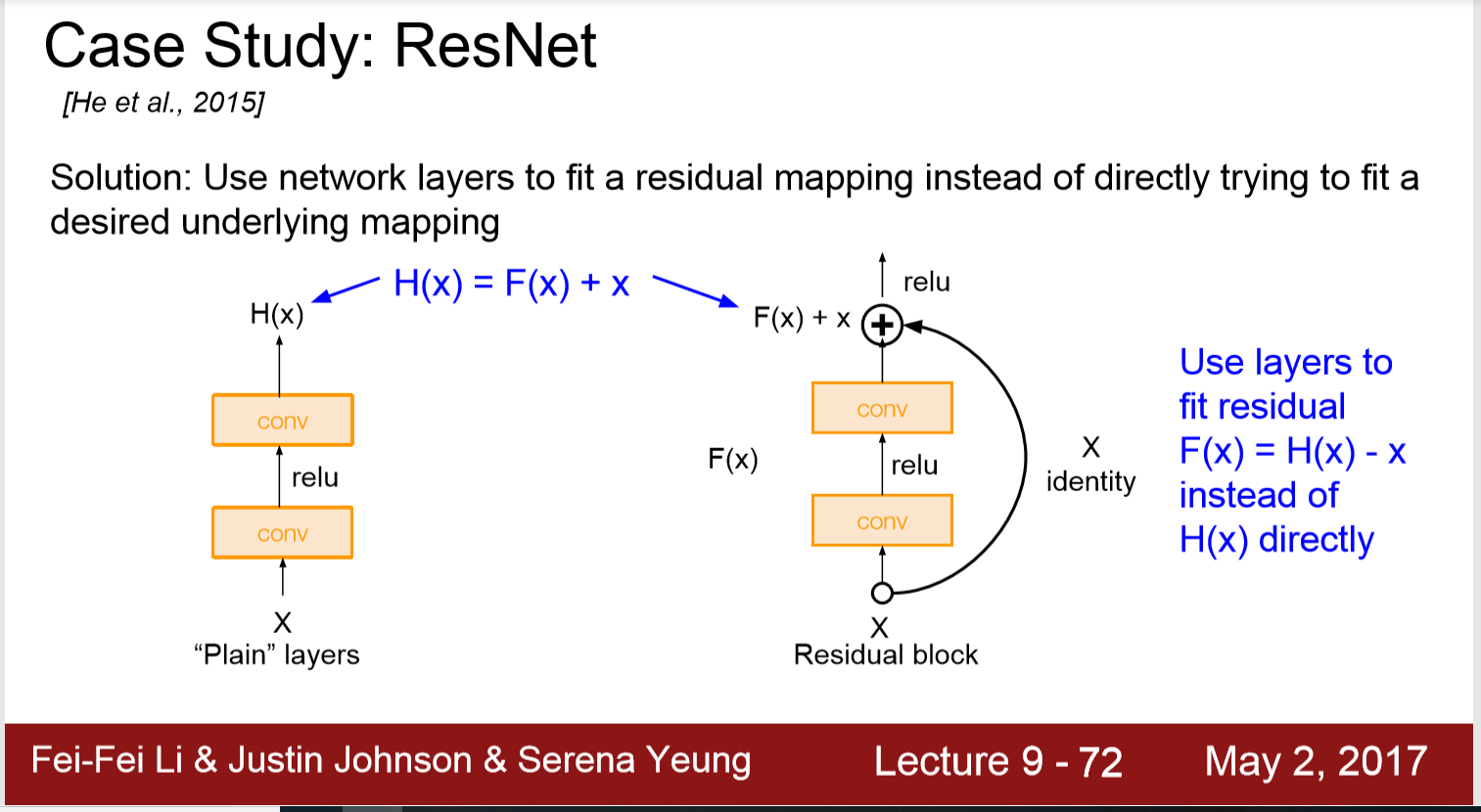
2. Residual block 提供的 skip connection,在backpropagation中直接将梯度跨层传递,这可以使得即使有几百层的模型也可以收敛的更快。
例如在t时刻:
非残差网络G(1)=1.1,
残差网络H(1)=1.1, H(1)=F(1)+1, F(1)=0.1
在t+1时刻:
非残差网络G’(1)=1.2,
残差网络H’(1)=1.2, H’(1)=F’(1)+1, F’(1)=0.2
这时候我们看看:
非残差网络G的梯度 = (1.2-1.1)/1.1 = 1/11
而残差网络F的梯度 = (0.2-0.1)/0.1 = 1
————————————————
版权声明:本文为CSDN博主「ylyyyy」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_40240670/article/details/85685095
3.
1)消除了输入和权重零奇点
2)打破对称性
3)打破线性依赖性
https://www.jianshu.com/p/a2812cf3ddad
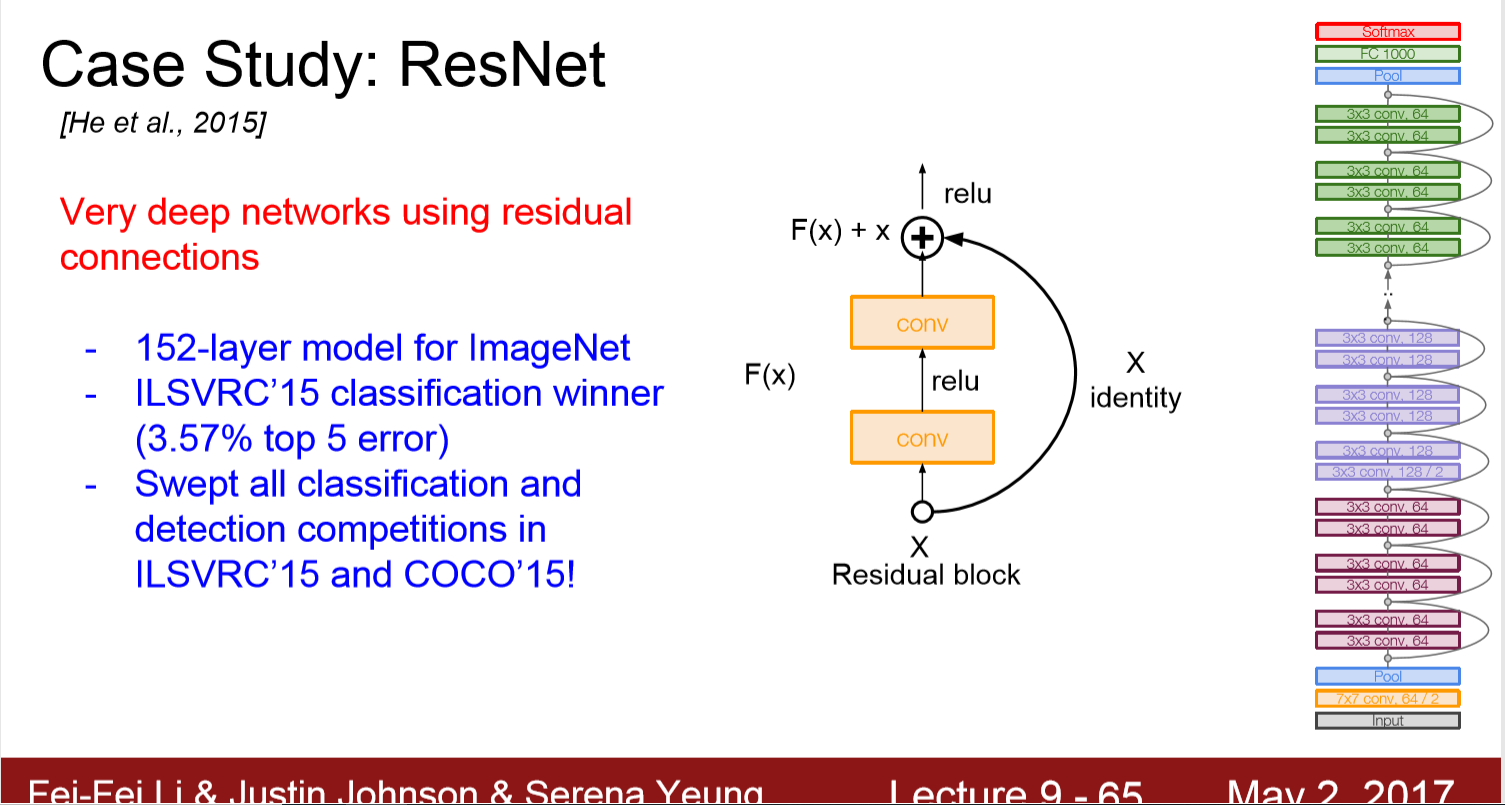
解决方法:
1.ResNet采用残差块的堆叠,每个残差块有两个3*3*depth的ConvReLu组成
2. 周期性的double filter的数量(64->128,......),并将stride变成2
3. 除了最后output的1000FC,没有全连接层

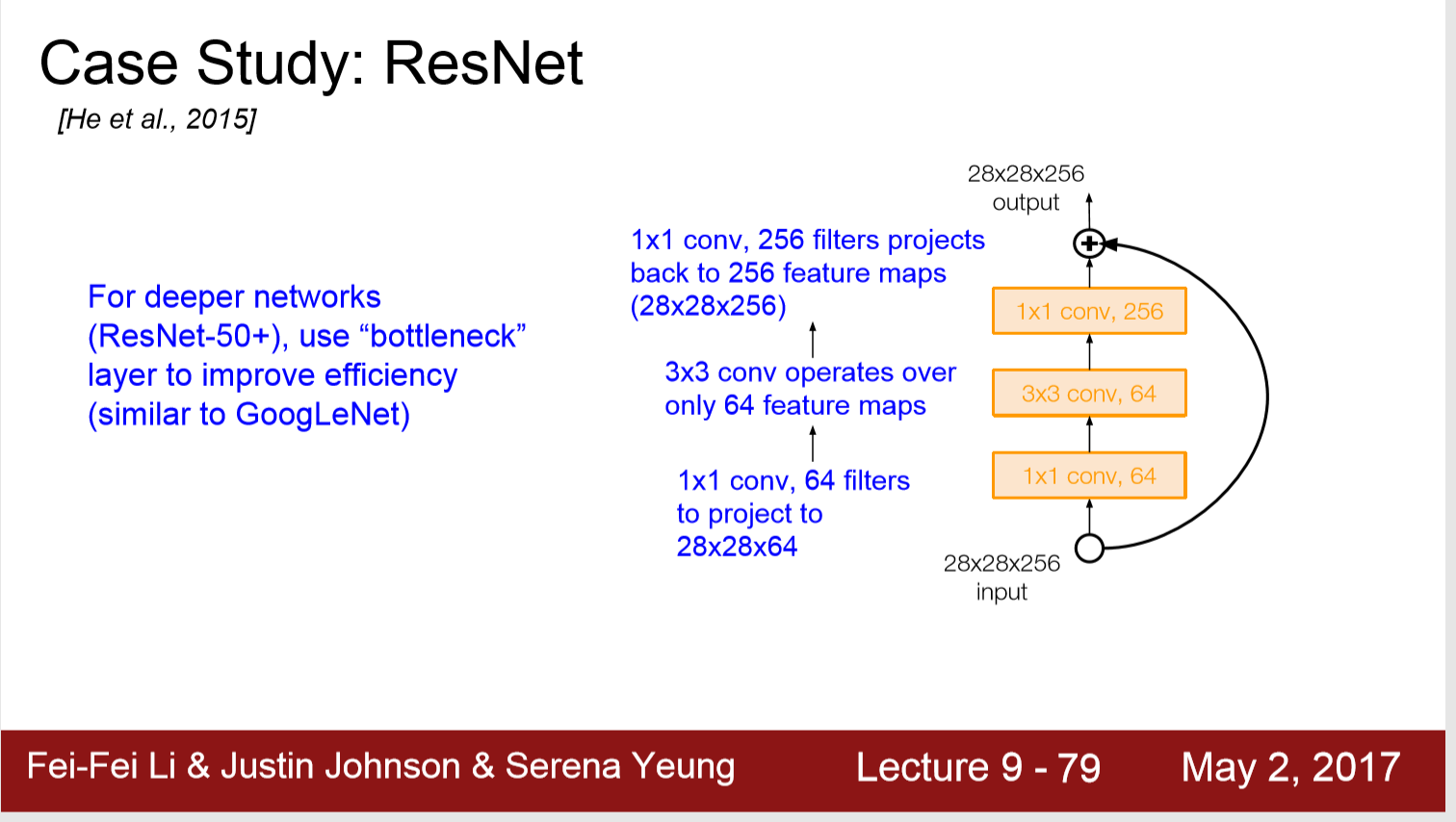
另:
1. 在深层ResNet-50+中,我们也用bottleneck to improve efficientcy
细节:
1. 每层 Conv之后都有ReLu与BN
2. Xavier/2 initialization
3. SGC + Momentum
4. learning rate decay
5. mini-batch size 256
6.weight decay 1e-5
7. no dropout
