https://www.cse.unsw.edu.au/~cs9313/20T2/slides/L2.pdf
https://drive.google.com/drive/folders/13_vsxSIEU9TDg1TCjYEwOidh0x3dU6es
回顾 3-replication
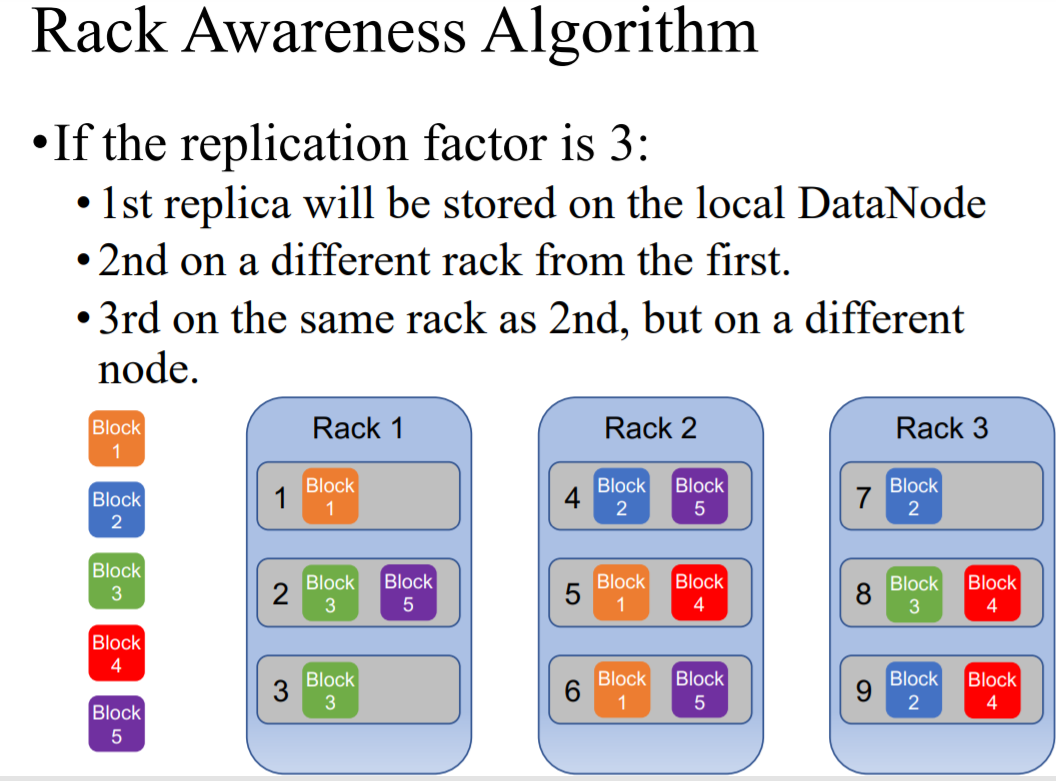
1)上周我们讲到一个文件会被复制三份,放入不同的datanodes;
2)比如一份文件640MB,被分为五个blocks(128*5),复制三份就是15个blocks,放入不同的datanodes,同一个datanodes中不能有相同的block,一般这三个blocks所在的datanotes在两个racks
3)这样有两个问题就是,所占内存太大,并且很少访问副本
HDFS Erasure Coding
1) 不是简单的将文件(blocks)分为三份,EC将单一block的内容写入9个block中(encoding),任意6个便能还原原始block(decoding)
2) 过程:
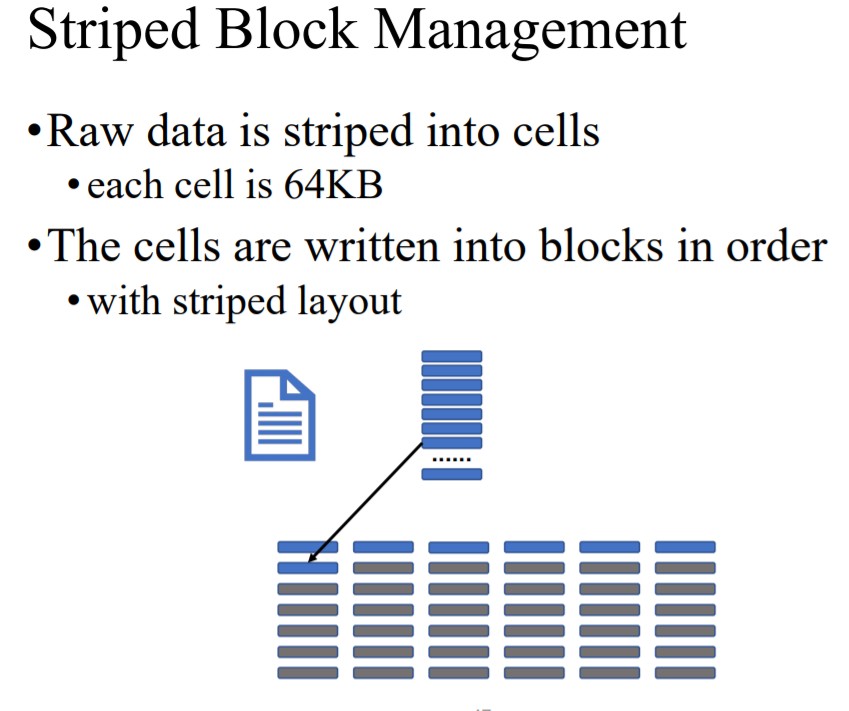
(1)将 block(128MB)中的文件分为cells(64KB)
(2)将这些cells 六个六个的写入六个不同的blocks中
(3)一行的六个cells计算出3个parities,写入另外三个blocks
(4)这一行的九个cells就组成了一个strpe,这九个blocks就完成了block(128MB)的写入
(5)这个block group的信息会被记录在NameNode中
3)failure:
(1)如果一个interval block坏掉了, We can recover the data from any 6 internal blocks


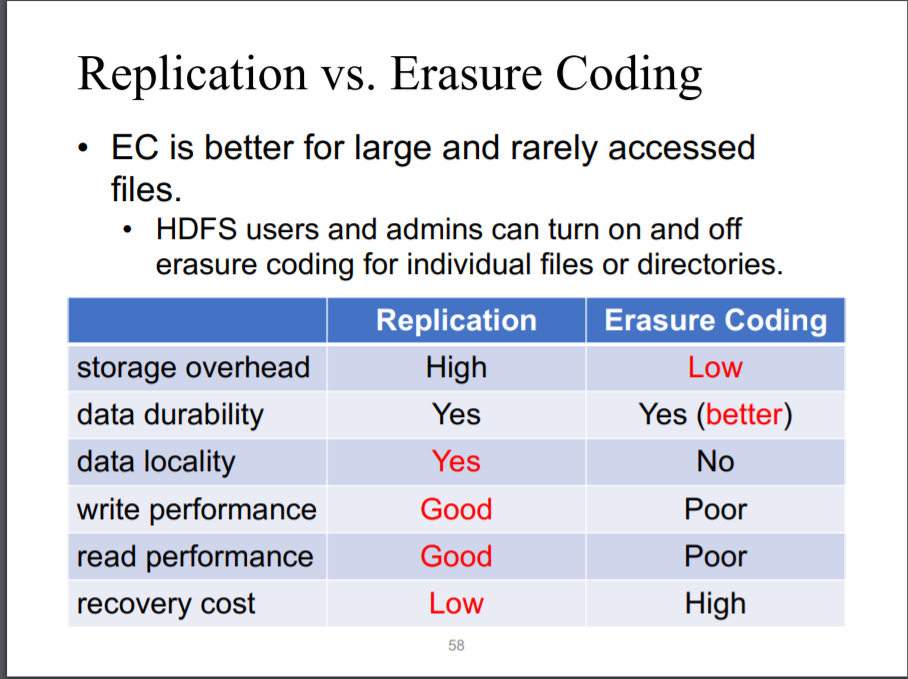
3-replication VS Erasure Coding:
1)EC占空间少(1.5N) 3R (3N)
2)EC允许丢失3个nodes,3R至允许丢失2个Nodes
3)3R具有更好的读写表现,因为一个replica就是一个整体,可以直接操作,EC的读写需要解码
(4)EC读数据要对6个blocks操作,写要对9个Blocks操作 group of blocks
4)恢复3R的cost更低