简介
Base64是一种非常常用的数据编码方式,标准Base64可以把所有的数据用"A~Z,a~z,0~9,+,/,="共65个字符(‘=’号仅是一个占位符,作为后缀)表示,当然在遇到的一些CTF题中也会有变种Base64作为加密算法来用,Base64运用范围是很广的,但是这里只讨论在安卓逆向中较为常见的URL编码和变种Base64
编码方式
在标准base64中,每行最多有76个字符(仅在Intent相关内有这个定义,如MIME,但是如果是别的领域不一定要满足这个),在每行结束的时候添加回车换行符“ ”,在windows系统中,“ ”是类似于箭头“↓”的功能,将光标向下平移。而“ ”是键盘“Home”功能,即将光标移动到首位。所以需要使用回车换行符才能达到Linux里的" "效果,即将光标往下平移至首位。还有就是在URL中,由于'+','/','='都是特定的意义,所以一般会对应的用'-','_','.'等替换。
标准Base64是一种编码方式而非加密方式最大的原因就是因为它的可逆,它的编码方式也很简单:
- 先将所有的字符由ASCⅡ转换为二进制串,例如:c o d转换为0110 0011(99) 0110 1111(111) 0110 0100(100)
- 将所有的二进制串连接,并按6个比特为一组,即011000110110111101100100
- 在每组比特前补上两个高位0,即:00011000 00110110 00111101 00100100
- 再根据下表转换,如本例中的00011000 00110110 00111101 00100100 即为24 54 61 36,即Y29k
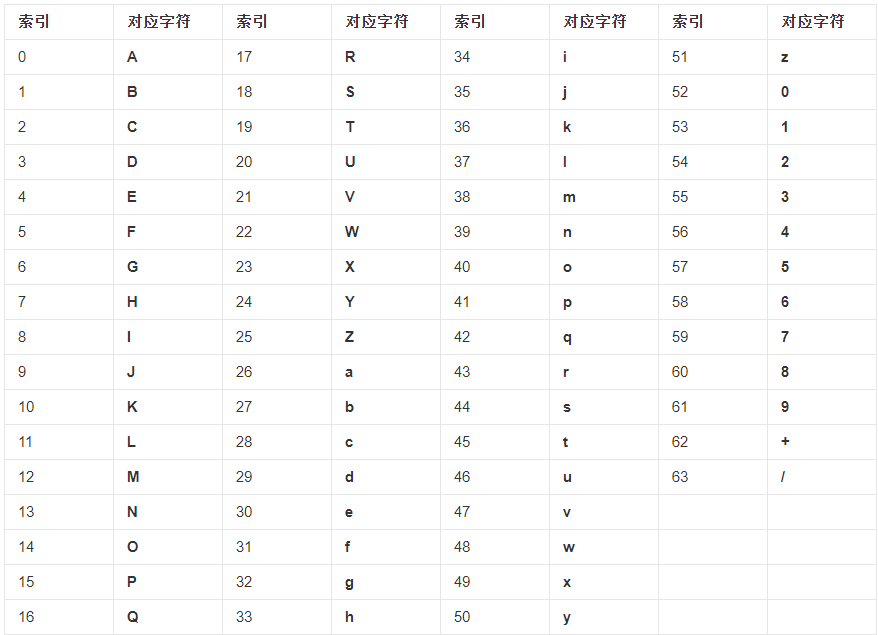
但是上述中我们也能发现不少问题,比如按我一开始说的有65个字符,那么“=”号去哪了呢?再如8*3=4*6,所以我们可以分为四组,每组六个比特,但如果我们的输入数据有4个或者5个等不可被3整除的长度呢?其实在解决办法中,这两者有联系。
既然有多余的长度,那就再后补零,比如上例子中,若输入数据是coda,那在cod操作之后,还剩下a,即0110 0001,同样转换为:
- 011000 01,往后补零为:011000 010000
- 补位00011000(24) 00010000(16)
- 查表转换为YQ
那“=”号呢?有人说等号是用来判断长度余下几位的,如余一位(4位,7位等)则用两个等号标识,若余两位,则用一个等号标识。
但是仔细想想就发现这个说法明显是错的,毕竟不管怎么说,若正好是三位一组的话,转为base64后也就是对应的4位一组,而除4,余下来的只可能是3和2(0和1在Base64编码里是不可能出现的),通过多余的字符数量,自然就可以知道输入数据的长度了。所以等号的用处就是:Base64规定要以4位字符为一组,所以你得加上这个等号。也就是说,如果是自己定义的话,这个等号也是可以不用加的。
变种Base64
既然已经知道了Base64的编码规则,那如果我们自己定义一些规则,就可以变成自己的变种base64,比如上述的“=”号,很多人都会用等号来判断是否是Base64的编码方式,但是经过分析之后就看得出,这个“=”号在编码中并不影响逆向编码,所以就可以删除最后的这个添加等号的判断;再比如标准Base64中的密码表是很规则的"A~Z....",但是这个密码表我们可以自己改,将其中间几个元素位置打乱是不是就可以修改为自己的base64了呢。
最后附上标准base64的加解密Python代码
加密:
#来源于百度百科 def base(string:str)->str: oldstr = '' newstr = [] base = '' base64_list = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '/'] #把原始字符串转换为二进制,用bin转换后是0b开头的,所以把b替换了,首位补0补齐8位 for i in string: oldstr += '{:08}'.format(int(str(bin(ord(i))).replace('0b', ''))) #把转换好的二进制按照6位一组分好,最后一组不足6位的后面补0 for j in range(0, len(oldstr), 6): newstr.append('{:<06}'.format(oldstr[j:j + 6])) #在base_list中找到对应的字符,拼接 for l in range(len(newstr)): base += base64_list[int(newstr[l], 2)] #判断base字符结尾补几个‘=’ if len(string) % 3 == 1: base += '==' elif len(string) % 3 == 2: base += '=' return base
解密:
1 #我也忘了来源于哪了 2 base64_charset = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/" 3 #base64密码表 4 def decode(base64_str): 5 base64_bytes = ['{:0>6}'.format(str(bin(base64_charset.index(s))).replace('0b', '')) for s in base64_str if 6 s != '='] 7 resp = bytearray() 8 nums = len(base64_bytes) // 4 9 remain = len(base64_bytes) % 4 10 integral_part = base64_bytes[0:4 * nums] 11 12 while integral_part: 13 tmp_unit = ''.join(integral_part[0:4]) 14 tmp_unit = [int(tmp_unit[x: x + 8], 2) for x in [0, 8, 16]] 15 for i in tmp_unit: 16 resp.append(i) 17 integral_part = integral_part[4:] 18 19 if remain: 20 remain_part = ''.join(base64_bytes[nums * 4:]) 21 tmp_unit = [int(remain_part[i * 8:(i + 1) * 8], 2) for i in range(remain - 1)] 22 for i in tmp_unit: 23 resp.append(i) 24 return resp