Pandas数据处理
删除重复元素
使用duplicated()函数检测重复的行,返回元素为布尔类型的Series对象,每个元素对应一行,如果该行不是第一次出现,则元素为True
- keep参数 : 指定保留哪一行重复行的数据
#创建具有重复元素的数据 import numpy as np import pandas from pandas import Series,DataFrame df = DataFrame(data=np.random.randint(0,100,size=(8,4))) df.iloc[1] = [666,666,666,666] df.iloc[3] = [666,666,666,666] df.iloc[6] = [666,666,666,666] df
效果如下:

#查看重复数据 ~df.duplicated(keep='first') #保留重复数据 第一行 df.loc[~df.duplicated(keep=False)] #不保留重复数据 #删除重复数据 #方式1 drop indexs = df.loc[df.duplicated(keep='last')].index df.drop(labels=indexs,axis=0) #删除重复数据,保留最后一行 #方式2 使用drop_duplicates()函数删除重复的行drop_duplicates(keep='first/last'/False) df.drop_duplicates(keep='first',inplace=False) #输出后直接映射到原数据
映射
replace() 函数 :替换
使用replace()函数,对values进行映射操作
1.Series替换操作
- 单值替换
- 普通替换
- 字典替换(推荐)
- 多值替换
- 列表替换
- 字典替换(推荐)
- 参数
- to_replace() 被替换的元素
示例
s = Series(data=[3,4,5,6,8,10,9]) #单值替换 s.replace(to_replace=6,value='six') #多值替换 s.replace(to_replace=[5,6],value=['five','six])
2. DataFrame替换操作
- 单值替换
- 普通替换: 替换所有符合要求的元素:to_replace=15,value='e'
- 按列指定单值替换: to_replace={列标签:替换值} value='value'
- 多值替换
- 列表替换: to_replace=[] value=[]
- 字典替换(推荐) to_replace={to_replace:value,to_replace:value}
示例
df.replace(to_replace=666,value='six') #将666全部替换为six df.replace(to_replace={0:'zero'}) #注意字典替换中,里面没有value参数的是将 列中为0的元素全部替换成 zero df.replace(to_replace={2:666},value='six') #这里字典替换,有value参数, 将下标为2的列的666替换为six '''注意:DataFrame中,无法使用method和limit参数'''
3. map()函数
新建一列 map函数并不是df的方法,而是series的方法
- map()可以映射新一列数据
- map()中可以使用lambd表达式
- map()中可以使用方法,可以是自定义的方法
- 注 : map() 中不能使用sum之类的函数,for循环
示例
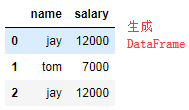
dic = { 'name':['jay','tom','jay'], 'salary':[12000,7000,12000] } df = DataFrame(data=dic) #生成一个DataFrame #映射关系表 dic2 = { 'jay':'周杰伦', 'tom':'张三', } df['c_name'] = df['name'].map(dic2) df
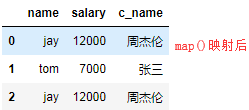
map当做一种运算工具,至于执行何种运算,是由map函数的参数决定的(参数:lambda,函数)
示例
#超过3000部分的钱缴纳50%的税 def after_salary(s): if s <= 3000: return s else: return s - (s-3000)*0.5 df['after_sal'] = df['salary'].map(after_salary) df
注意:并不是任何形式的函数都可以作为map的参数。只有当一个函数具有一个参数且有返回值,那么该函数才可以作为map的参数。

使用聚合操作对数据异常值检测和过滤
- 使用df.std()函数可以求得DataFrame对象每一列的标准差
# 创建一个1000行3列的df 范围(0-1),求其每一列的标准差 df = DataFrame(data=np.random.random(size=(1000,3)),columns=['A','B','C']) df #对df应用筛选条件,去除标准差太大的数据:假设过滤条件为 C列数据大于两倍的C列标准差 std_twice = df['C'].std() * 2 #获取C列2倍的方差 df['C'] > std_twice df.loc[~(df['C'] > std_twice)] #获取到大于2倍方差的所有数据(异常数据) indexs = df.loc[df['C'] > std_twice].index #获取到异常数据 df.loc[indexs,'C'] = np.nan #将异常数据对应的C列元素赋值为np.nan #将C列前后的正常数据填充np.nan df.fillna(axis=0,method='ffill',inplace=True) df.fillna(axis=0,method='bfill',inplace=True)
排序
使用.take()函数排序
- take()函数接受一个索引列表,用数字表示,使得df根据列表中索引的顺序进行排序
- eg:df.take([1,3,4,2,5])np.random.permutation()函数 #随机排序
示例
df.take([2,1,0],axis=1) #根据索引顺序进行对列排序 df.take(np.random.permutation(3),axis=1) #针对列进行随机排序 random_df = df.take(np.random.permutation(3),axis=1).take(np.random.permutation(1000),axis=0) #先根据列随机排序,再根据行随机排序 #注意:这里的axis使用也是和drop一样 axis=1 表示
- np.random.permutation(x)可以生成x个从0-(x-1)的随机数列
np.random.permutation(5) #随机生成以下数列 array([1, 2, 3, 0, 4]) array([2, 3, 0, 1, 4])
总结 : 当DataFrame规模足够大时,直接使用np.random.permutation(x)函数,就配合take()函数实现随机抽样
数据分类处理
数据聚合是数据处理的最后一步,通常是要使每一个数组生成一个单一的数值。
数据分类处理:
- 分组:先把数据分为几组
- 用函数处理:为不同组的数据应用不同的函数以转换数据
- 合并:把不同组得到的结果合并起来
数据分类处理的核心:
- groupby()函数
- groups属性查看分组情况
- eg: df.groupby(by='item').groups分组
from pandas import DataFrame,Series df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'], 'price':[4,3,3,2.5,4,2], 'color':['red','yellow','yellow','green','green','green'], 'weight':[12,20,50,30,20,44]}) df

示例1
# 使用groupby实现分组 df.groupby(by='item',axis=0) # <pandas.core.groupby.DataFrameGroupBy object at 0x000000000EDABA20> #使用groups查看分组情况 df.groupby(by='item',axis=0).groups
''' {'Apple': Int64Index([0, 5], dtype='int64'), 'Banana': Int64Index([1, 3], dtype='int64'), 'Orange': Int64Index([2, 4], dtype='int64')} ''' """分组后的聚合操作:分组后的成员中可以被进行运算的值会进行运算,不能被运算的值不进行运算""" #给df创建一个新列,内容为各个水果的平均价格 mean_price = df.groupby(by='item',axis=0)['price'].mean() dic = mean_price.to_dict() df['mean_price'] = df['item'].map(dic) df
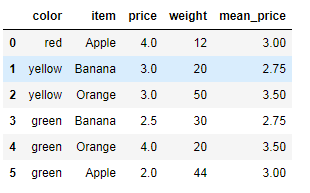
示例2 如下图看各色水果平均价格
color_mean_price = df.groupby(by='color',axis=0)['price'].mean() dic = color_mean_price.to_dict() df['color_mean_price'] = df['color'].map(dic) df
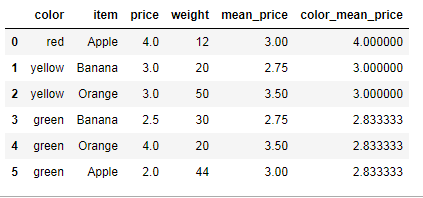
高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
- df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)
- transform和apply都会进行运算,在transform或者apply中传入函数即可
- transform和apply也可以传入一个lambda表达式
示例
def fun(s): sum = 0 for i in s: sum+=i return sum/s.size #使用apply函数求出水果的平均价格 df.groupby(by='item')['price'].apply(fun) #使用transform函数求出水果的平均价格 df.groupby(by='item')['price'].transform(fun) #apply还可以代替运算工具形式map s = Series(data=[1,2,3,4,5,6,7,87,9,9]) # s.map(func) s.apply(func)
...
...