前言
关于SQL Server基础系列尚未结束,还剩下最后一点内容未写,后面会继续。有园友询问我什么时候开始写SQL Server性能系列,估计还得等一段时间,最近工作也比较忙,但是会陆陆续续的更新SQL Server性能系列,本篇作为性能系列的基本引导,让大家尝尝鲜。在涉及到SQL Server性能优化时,我看到的有些文章就是一上来列出SQL Server的性能优化条例,根本没有弄清楚为什么这么做,当然也有可能是自己弄懂了,只是作为备忘录,但是到了我这里,我会遵循不仅仅是备忘录,还要让各位园友都能易于理解,不至于面试时只知道其果,不知其因。
存储过程性能优化
禁用受影响函数通过设置SET NOCOUNT ON
如上当我们进行查询时总是会返回受影响的行数,这种消息只是对于我们调试SQL时有帮助,其他再无其他帮助,我们可以通过设置 SET NOCOUNT ON 来禁用这个特性,这将有显著的性能提升,有利于减少网络流量的传输。在存储过程中我们像如下设置。
CREATE PROC dbo.ProcName AS SET NOCOUNT ON; --Your Procedure code SELECT [address], city, companyname FROM Sales.Customers -- Reset SET NOCOUNT to OFF SET NOCOUNT OFF; GO
使用架构名称+对象名称
这个建议在开篇我们就已经明确讲过,通过设置架构名称的对象名称是最合格的,此时将直接执行编译计划而不是在使用缓存计划时还要去其他可能的架构中去查找对象。所以我们建议总是像如下使用。
SELECT * FROM Sales.Customers -- 推荐 -- 而不是 SELECT * FROM Customers -- 避免 --调用存储过程如下 EXEC dbo.MyProc -- 推荐 --而不是 EXEC MyProc -- 避免
存储过程名称禁止以sp开头
如果一个存储过程名称以sp开头,此时数据库查询引擎首先将在master数据库中去查找存储过程然后再是在当前会话的数据库中去查找存储过程。
使用IF EXISTS (SELECT 1) 而不是 (SELECT *)
网上随便一搜索就看到如下查询一行是否存在的SQL语句。
declare @message varchar(200), @name varchar(200) if exists(select * from students where 学号='1005') begin set @message='下列人员符合条件:' print @message set @name=(select 姓名 from students where 学号='1005') print @name end else begin set @message='没有人符合条件' print @message end go
当判断一条记录是否在表中存在时我们使用IF EXISIS,如果在IF EXISTS中内部语句中有任何值返回则返回TRUE。如上述
if exists(select * from students where 学号='1005')
此时将返回学号 = '1005'的这一行,而如果用1代替则不用返回满足条件的这一行记录,在查询时为了网络传输我们应该最小化处理数据,所以我们应该像如下做返回单值1.
IF EXISTS (SELECT 1 FROM Sales.Customers WHERE [address] = 'Obere Str. 0123')
使用sp_executesql而不是使用EXECUTE
sp_executesql支持使用参数而不是使用EXECUTE来提高代码重用,动态语句的查询执行计划只有对每个字符包括大小写、空格、参数、注释相同的语句才重用。如果利用EXECUTE执行如下动态SQL语句。
DECLARE @Query VARCHAR(100) DECLARE @contactname VARCHAR(50) SET @contactname = 'Allen, Michael' SET @Query = 'SELECT * FROM Sales.Customers WHERE contactname = ' + CONVERT(VARCHAR(3),@contactname) EXEC (@Query)
执行查询计划如下,如果再一次使用不同的@contactname值,此时查询执行计划将再次创建@contactname不会达到重用的目的

如果我们使用利用sp_executesql像如下查询,如果对于不同的@contactname值,此时查询执行计划将被会重用,将会达到提高性能的目的。
DECLARE @Query VARCHAR(100) SET @Query = 'SELECT * FROM Sales.Customers WHERE contactname = @contactname' EXECUTE sp_executesql @Query,N'@contactname VARCHAR(50)',@contactname = 'Allen, Michael'
对于异常处理利用TRY-CATCH处理
在SQL Server 2005之后开始支持异常处理,如果我们进行异常语句检查处理,如果出现异常将不会导致利用更多的代码来消耗更多的资源和时间。
尽可能使事务简短
事务的长度会影响阻塞和死锁。直到事务结束排他锁不会释放,在高隔离级别中共享锁的生命周期更长, 因此,冗长的事务意味着锁定的时间更长,锁定的时间越长最终导致阻塞,在有些情况下,阻塞会转变成死锁,所以为了更快的执行、更少的阻塞,我们应该使事务的长度尽量简短。
数据压缩和页压缩提高IO
SQL Server主要的性能取决于磁盘IO效率,改善IO意味着提高性能,在SQL Server 2008中提供了数据和备份压缩功能。下面我们一起来看看。
数据压缩
数据压缩意味着磁盘保留的空间减少,数据压缩可以配置在表上的聚集索引、非聚集索引、索引视图或者分区表或者分区索引。数据压缩可以在两个级别中实现:一个是行压缩,另外一个是页压缩,甚至页压缩会自动实现行压缩,当通过CREATE TABLE、CREATE INDEX语句时会压缩表和索引,为了改变一个表、索引和分区的压缩状态通过 ALTER TABLE.. REBUILD WITH or ALTER INDEX.. REBUILD WITH语句实现。当一个堆栈的压缩状态改变后,此时非聚集索引将重建,在行压缩中,使用以下四种方法来消除未使用的空间。
1.减少记录中的元数据开销。
2.所有数字类型(INT、NUMERIC等)和基于数字类型(如DATETIME、MONEY)将会转换成可变长度值,例如INT类型在压缩后所有未被消耗的空间将会被回收。比如我们知道0-255可以存储一个字节中,若我们的值是100,在磁盘中INT是4个字节,但是在压缩之后其余3个字节将会被回收。
3.CHAR和NCHAR会转换成可变长度存储,在压缩之后对于实际存储的数据将不会再有空格,比如我们定义CHAR(10),此时我们存储的数据为Jeffcky,默认情况下将会预留10个字节,此时将会有3个字节为空格补充,但是在压缩之后这3个字节将会被回收,仅仅只预留7个字节。
4.所有NULL和0都已经过优化不需要字节。
页压缩
页压缩将会通过以下三种方法实现。
1.上述已经提到的所有。
2.前缀压缩:在每页上的每一列,被标识的所有行的公共值以及存储在标题下的每一行,在压缩之后公共值将替换为标题行的引用。
3.字典压缩:在字典压缩中,每一页中的每一列标识公共值,是将存储在标题行的第二行中,然后这些公共值将替换为新行中的值的引用。
说了这么多,具体到底是怎样使用的呢?请继续往下看,我们通过使用临时数据库插入748条数据,如下:
USE tempdb GO CREATE TABLE TestCompression (col1 INT, col2 CHAR(50)) GO INSERT INTO TestCompression VALUES (10, '压缩测试') GO 748
接下来进行行压缩和页压缩来和原始未压缩进行比较看看。
-- 原始值 EXEC sp_spaceused TestCompression GO -- DATA_COMPRESSION = 设置行压缩 ALTER TABLE TestCompression REBUILD WITH (DATA_COMPRESSION = ROW); GO EXEC sp_spaceused TestCompression GO -- DATA_COMPRESSION = 设置页压缩 ALTER TABLE TestCompression REBUILD WITH (DATA_COMPRESSION = PAGE); GO EXEC sp_spaceused TestCompression GO -- DATA_COMPRESSION = 没有压缩 ALTER TABLE TestCompression REBUILD WITH (DATA_COMPRESSION = NONE); GO EXEC sp_spaceused TestCompression GO
结果如下:
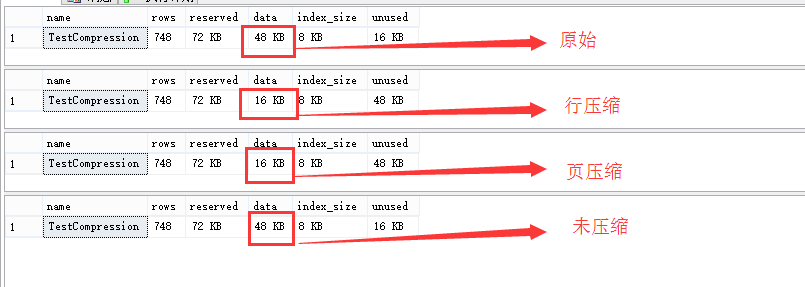
压缩后数据显然变少了,如果数据量足够大页压缩比行压缩的数据会更少,从而减少IO提高性能,不知道看到本文的你是否在生产服务上是否已经应用过呢,下次可以试试。
总结
本节我们稍微讲解了下存储过程的性能优化和数据压缩提高IO,当然还有其他优化,这里只是作为后续开篇。