目录
哈希表(Hash Table)是根据关键码值(key, value)而直接进行访问的数据结构。当我们从哈希表中查找需要的数据时,理想情况是不经过任何比较,一次存取便能得到所查记录,那就必须在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使每个关键字和结构中唯一的存储位置对应。
可以把哈希表理解为一个数组,每个索引对应一个存储位置,哈希表的索引并不像普通数组的索引那样,从0到length-1.而是关键字(key)本身通过哈希函数得到。
举例说明:
将26个小写字母存储到数组 int a[26]中。
a对应a[0], b对应a[1],c对应a[2],....以此类推
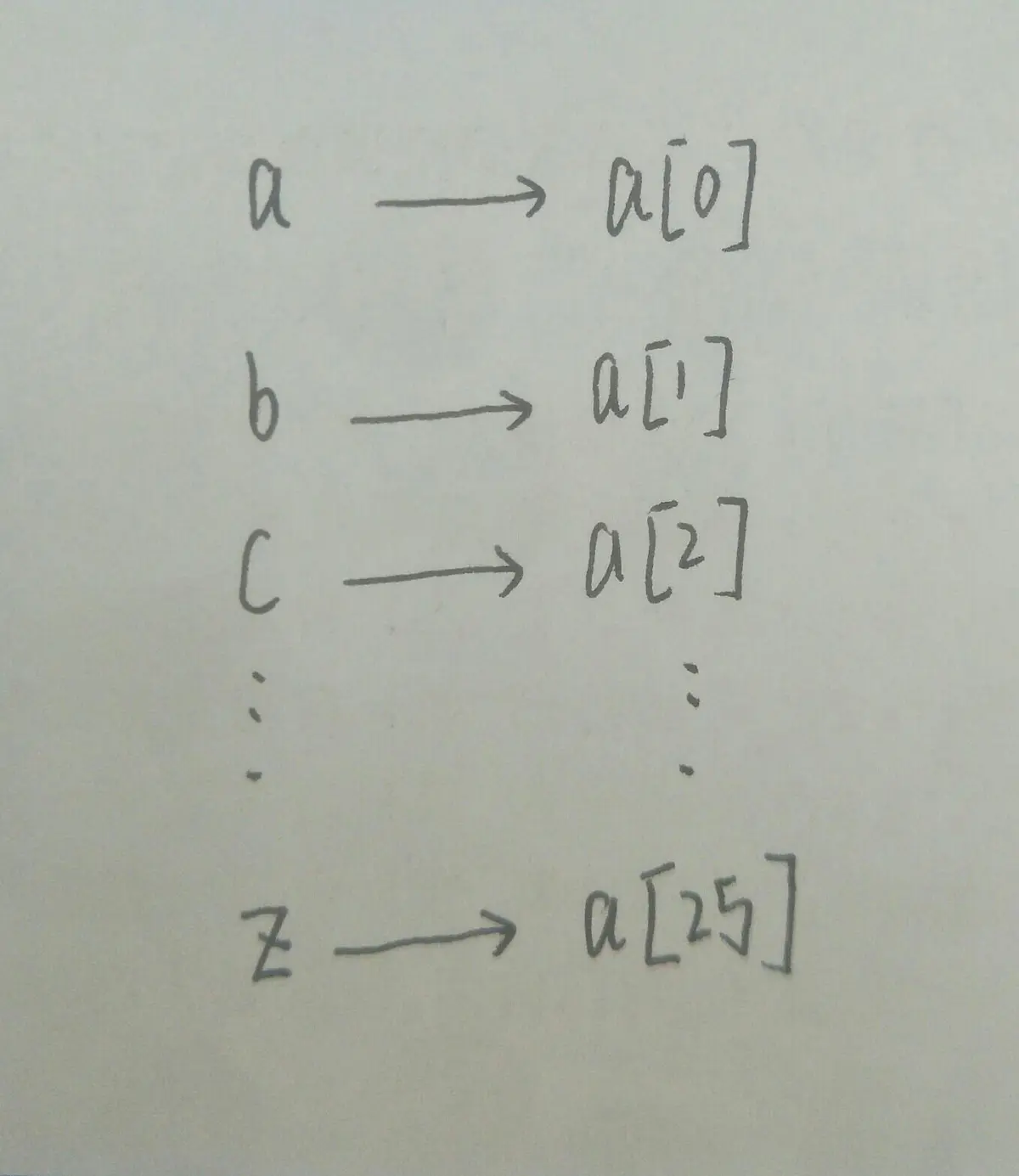
哈希函数
上述例子中,关键字(小写字母)是如何得到自己对应索引的位置的呢
关键字的ASCII值减去a的ASCII值。

之前说过,关键字通过哈希函数得到索引,所以,f(ch)就是哈希函数。
- 问题分析
要统计第一个只出现一次的字符,可以利用哈希表,遍历字符串两次
第一次:从头到尾遍历整个字符串,并统计每个字符出现的次数
第二次:再遍历字符串,在哈希表中找到首个数量为1的字符,并返回
为了实现哈希表,我们可以利用数组来进行实现。由于字符串中都是小写字母,因此我们申请一个长度为26的字符(一共有26个小写字母)。为了实现哈希表,我们将26个小写字母存储到数组word中,a对应a[0],b对应a[1],c对应a[2],...以此类推。
此时word[26]就是一个哈希表。但是小写字母如何得到自己索引呢?由于每个小写字母都有自己对应的ASCII码值,用每个小写字母的ASCII码值减去97即a的ASCII码值,就可以得到小写字母的索引位置。数组的元素存储每个小写字母出现的次数。
1 class Solution { 2 public: 3 char firstUniqChar(string s) { 4 if(s.empty()) 5 return ' '; 6 int n=s.size(); 7 vector<int> word(26); 8 for(int i=0;i<n;++i) 9 word[s[i]-'a']++; 10 for(int i=0;i<n;++i) 11 { 12 if(word[s[i]-'a']==1) 13 return s[i]; 14 } 15 return ' '; 16 } 17 };

- 问题分析
由于字符串全部由大写字母和小写字母组成。小写字母的ASCII码范围为65-90,大写字母的ASCII码范围为97-122,因此我们可以设置一个长度为65的数组即可。
我们采用哈希表,将字符串中每个字符和其ASCII码值相对应,每个字母如何找到其索引呢?每个字母的字符值减去65就是其索引值。
- 代码参考
1 class Solution { 2 public: 3 int FirstNotRepeatingChar(string str) { 4 if(str.empty()) 5 return -1; 6 vector<int> word(65); 7 for(int i=0;i<str.size();++i) 8 word[(int)str[i]-65]++; 9 for(int i=0;i<str.size();++i) 10 { 11 if(word[(int)str[i]-65]==1) 12 return i; 13 } 14 return -1; 15 } 16 };
- 问题分析
要找到数组中的重复的数字,可以采用以下算法
对于数字范围在0-n-1范围内的长度为n的数组,如果没有重复的数字,则数组中每个位置有且仅有一个元素
如果有重复数字,则有些位置没有元素,有些位置有多个元素。
找到数组中重复数字的算法如下:
从头到尾扫描整个数组,设下标为i的位置元素值为m
如果m==i,则继续扫描下一个元素
如果m!=i,首先判断下标值为m的位置其元素值和下标值是否相同
如果元素值和下标值相同,则找到一个重复元素
否则,交换他们
- 代码参考
1 class Solution { 2 public: 3 int findRepeatNumber(vector<int>& nums) { 4 /* 5 如果0-n-1范围内长度为n的数组中没有重复的元素,数组中每一个位置有且仅有一个元素 6 如果有重复的元素,则有些位置是空的,有些位置存储了多个元素 7 因此找到数组中重复的数字算法如下: 8 从头到尾扫描整个数组 9 如果下标为i的位置元素为m,如果m==i,则继续扫描下一个元素 10 如果下标为i的位置的元素m!=i,则看下标为m的位置元素值和下标值是否相同 11 如果相同,则找到一个重复元素 12 否则,交换m和i 13 */ 14 if(nums.empty()) 15 return 0; 16 //从头到尾扫描整个数组 17 for(int i=0;i<nums.size();++i) 18 { 19 //判断下标为i的元素值和下标值是否相同 20 //如果相同,则直接扫描下一个元素 21 //如果不同,则做下一步判断 22 while(nums[i]!=i) 23 { 24 //判断下标为m的位置元素值和下标值是否相同 25 //如果相同,则找到一个重复元素 26 if(nums[nums[i]]==nums[i]) 27 { 28 return nums[i]; 29 } 30 else 31 { 32 int temp=nums[i]; 33 nums[i]=nums[temp]; 34 nums[temp]=temp; 35 } 36 } 37 } 38 return 0; 39 } 40 };

- 问题分析
这道题我们可以使用滑动窗口+双指针+哈希表来实现
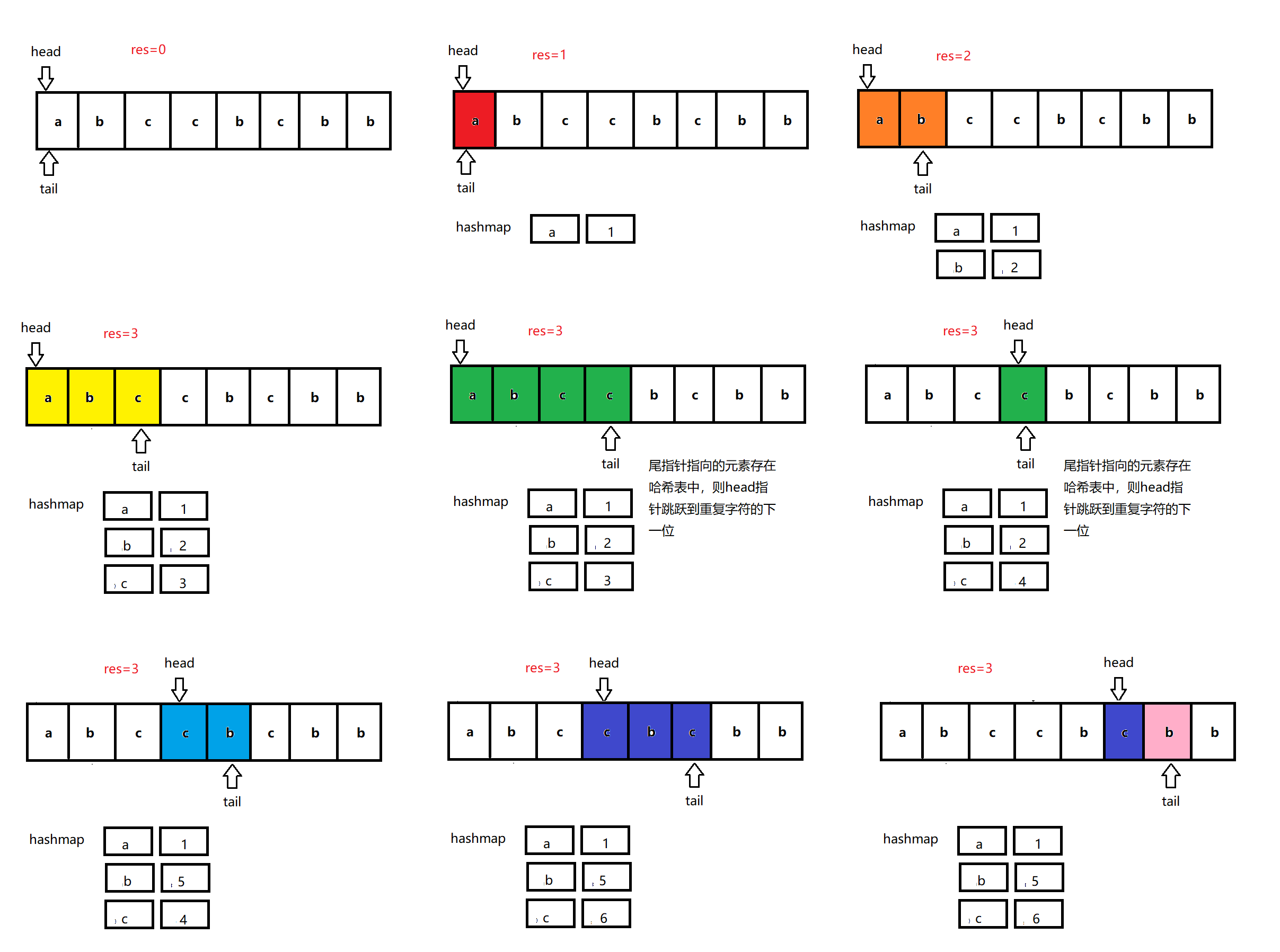
题目中要求答案必须是子串的长度,意味着子串内的字符在原生字符串中一定是连续的。因此我们可以将答案看做源字符串的一个滑动窗口,并维护窗口内不能有重复字符,同时更新窗口的最大值。我们可以使用哈希表记录每个字符的下一个索引,然后尽量向右移动尾指针来扩展窗口,并更新窗口的最大长度,如果尾指针指向的元素重复,则将头指针直接移动到窗口中重复元素的右侧。
算法:
1. tail指针向末尾方向移动
2. 如果尾指针指向的元素存在于哈希表中:
head指针跳跃到重复字符的下一位
3. 更新哈希表的窗口长度。
定义一个哈希表(k, v), 其中key为字符,value为字符位置+1,+1表示从字符位置后一个才开始不重复
我们定义不重复子串的开始位置为start,结束位置为end
随着end不断遍历向后,会遇到与[start, end]区间内字符相同的情况,此时将字符作为key值,获取其value值,并更新start,此时[start, end]区间内不存在重复字符
无论是否更新start,都会更新其哈希表和结果ans
- 代码参考
1 class Solution { 2 public: 3 int lengthOfLongestSubstring(string s) { 4 if(s.empty()) 5 return 0; 6 unordered_map<char,int> map;//利用哈希表,key存储字符,value存储字符的位置+1 7 /* 8 定义不重复字符子串的开始位置为start,结束位置为end 9 end向后遍历,若end指向的字符在哈希表中出现过,则将此字符作为key值,获取其value值,并更新start,此时[start,end]区间内不存在重复字符 10 */ 11 int ans=0; 12 int start=0; 13 for(int end=0;end<s.size();++end) 14 { 15 //如果此字符在哈希表中出现过,将此字符作为key值,获取其value值,并更新start 16 if(map.count(s[end])!=0) 17 { 18 //更新start 19 start=max(map[s[end]],start); 20 } 21 //无论是否出现,都将目前的字符作为key值,获取其value值 22 map[s[end]]=end+1; 23 //更新ans 24 ans=max(end-start+1,ans); 25 } 26 return ans; 27 } 28 };
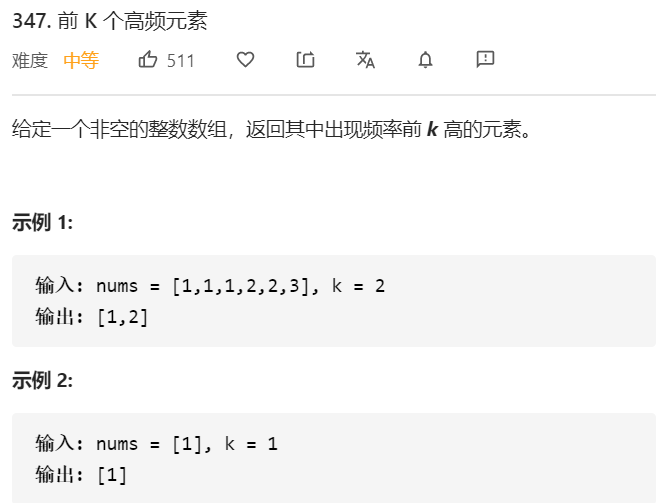
- 问题分析
这道题是需要我们统计数组中前k个高频元素。算法如下
首先统计数组中每个元素出现的次数,用哈希表进行存储元素和出现次数,key表示数组元素,value表示数组出现的次数
由于需要找到钱k个高频元素,因此需要对数组中出现的次数进行排序,我们可以用快速排序或者最小堆来解决这个问题,在这里主要介绍最小堆
创建一个最小堆,如果最小堆中元素的个数小于k,则直接将其插入最小堆中
如果最小堆中的元素大于k,则比较堆顶元素与当前出现次数大小
如果堆顶元素更大,说明至少有k个数字出现的次数比当前值大,将当前值舍去
如果堆顶元素更小,则将当前值插入堆中
为了更简便的写代码,也可以这样构造一个大小为k的最小堆
将来的元素通通插入最小堆,若最小堆尺寸大于k,则直接将堆顶元素出栈,否则不作出反应
- 代码参考
1 class Solution { 2 public: 3 class mycomparison{ 4 public: 5 bool operator()(const pair<int,int> &lhs,const pair<int,int> &rhs) 6 { 7 return lhs.second>rhs.second; 8 } 9 }; 10 vector<int> topKFrequent(vector<int>& nums, int k) { 11 vector<int> result(k); 12 if(nums.empty()) 13 return result; 14 //从头到尾统计数组中每个数字出现的次数 15 unordered_map<int,int> map; 16 for(int i=0;i<nums.size();++i) 17 map[nums[i]]++; 18 //建立一个最小堆 19 //每个新来的元素都插入最小堆,若最小堆元素个数超过k,则将堆顶元素删除 20 priority_queue<pair<int,int>,vector<pair<int,int>>,mycomparison> pri_que; 21 for(unordered_map<int,int>::iterator it=map.begin();it!=map.end();++it) 22 { 23 pri_que.push(*it); 24 if(pri_que.size()>k) 25 pri_que.pop(); 26 } 27 //建立好最大k个元素的最小堆后,由于最小堆是最小元素在堆顶,因此倒序打印 28 for(int i=k-1;i>=0;--i) 29 { 30 result[i]=pri_que.top().first; 31 pri_que.pop(); 32 } 33 return result; 34 } 35 };
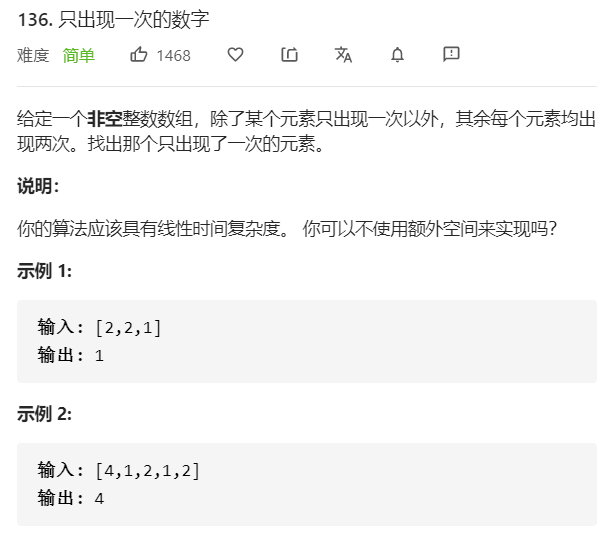
- 问题分析(解法一)
解法一:位运算
首先要了解异或运算:
一个元素与其本身异或结果为0
如果整数数组中,一个元素出现次数两次,则其异或结果为0.
如果整数数组中,只有一个元素出现了一次,其余元素都出现了两次,则从头到尾异或整个数组,结果为那个只出现一次的数组
- 代码参考
1 class Solution { 2 public: 3 /* 4 对于一个整数数组来说,如果一个元素出现了两次,则异或结果为0 5 如果一个整数数组除了一个元素出现一次,其余每个元素均出现两次,则从头到尾异或整个数组,结果为只出现一次的元素 6 */ 7 int singleNumber(vector<int>& nums) { 8 if(nums.empty()) 9 return 0; 10 int sumOR=0; 11 for(int i=0;i<nums.size();++i) 12 { 13 sumOR^=nums[i]; 14 } 15 return sumOR; 16 } 17 };
- 问题分析(解法二)
也可以直接使用哈希表来实现
从头到尾遍历整个数组,并统计数组中每个元素出现的次数
从头到尾遍历整个哈希表,如果元素出现的次数为1,则直接将这个元素返回
- 代码参考
1 class Solution { 2 public: 3 int singleNumber(vector<int>& nums) { 4 /* 5 还可以使用哈希表,两次扫描 6 第一次扫描: 7 如果数组中元素第一次出现,则将元素插入哈希表 8 如果数组中元素第二次出现,则将元素从哈希表中移除 9 第二次扫描哈希表 10 最后剩下的数组就是只出现一次的数字 11 */ 12 if(nums.empty()) 13 return 0; 14 unordered_map<int,int> m; 15 int result; 16 for(int i=0;i<nums.size();++i) 17 { 18 m[nums[i]]++; 19 } 20 for(auto i=m.begin();i!=m.end();++i) 21 { 22 if(i->second==1) 23 result=i->first; 24 } 25 return result; 26 } 27 };
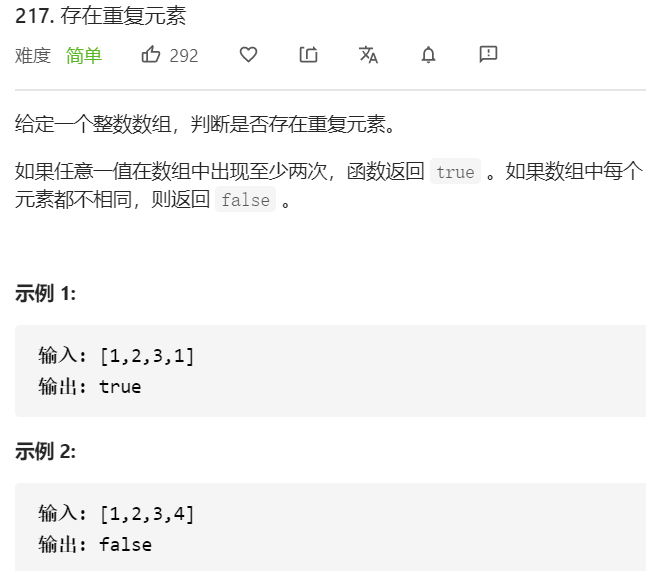
- 问题分析
利用哈希表实现
从头到尾遍历整个数组,统计数组中每个元素出现的次数,如果某个元素出现次数大于1,则直接返回true,否则继续统计。
- 代码参考
1 class Solution { 2 public: 3 bool containsDuplicate(vector<int>& nums) { 4 if(nums.empty()) 5 return false; 6 //统计整数数组中每个元素出现的次数 7 unordered_map<int,int> map; 8 for(auto c:nums) 9 { 10 map[c]++; 11 if(map[c]>1) 12 return true; 13 } 14 return false; 15 } 16 };
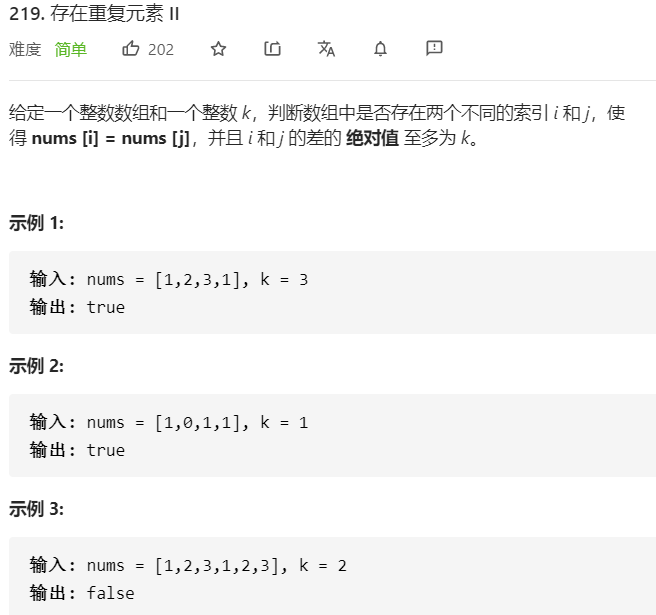
- 问题分析
遍历一个哈希表
维护一个哈希表,里面始终最多包含k个元素,当出现重复值时则说明在k距离内存在重复元素。
每次遍历一个元素则将其加入哈希表,如果哈希表的大小大于k,则移除最前面的数字。
- 代码参考
1 class Solution { 2 public: 3 bool containsNearbyDuplicate(vector<int>& nums, int k) { 4 if(nums.empty()) 5 return false; 6 unordered_set<int> set; 7 for(int i=0;i<nums.size();++i) 8 { 9 if(set.count(nums[i])) 10 return true; 11 //每次遍历一个元素则将其加入哈希表中 12 set.insert(nums[i]); 13 //如果哈希表大小大于k,则移除最前面的数字 14 if(set.size()>k) 15 set.erase(nums[i-k]); 16 } 17 return false; 18 } 19 };
- 问题分析
要判断字符串是否是回文排列,可以采用以下算法
首先通过统计字符串中每个字符出现的次数,用哈希表存储起来
然后统计哈希表中出现的次数,回文排列最多允许出现一个奇数字符,若超过奇数字符,则判断出不是回文排列
- 代码参考
1 class Solution { 2 public: 3 bool canPermutePalindrome(string s) { 4 if(s.empty()) 5 return true; 6 int odd_number=0; 7 //首先统计字符串中每个字符出现的次数 8 unordered_map<char,int> ch_map; 9 for(int i=0;i<s.size();++i) 10 { 11 ch_map[s[i]]++; 12 } 13 for(auto c:ch_map) 14 { 15 if(c.second%2!=0) 16 odd_number+=1; 17 } 18 if(odd_number>1) 19 return false; 20 else 21 return true; 22 } 23 };
- 问题分析
使用哈希表来进行实现,由于哈希查找的时间复杂度为O(1),所以可以利用哈希表来降低时间复杂度
从头到尾遍历整个数组nums,i为当前下标,对于数组nums中的每个元素,都要判断哈希表map中是否存在temp=target-nums[i]的key值
如果存在,则找到两个值
如果不存在,则将当前的(nums[i], i)存入哈希表中,继续遍历直到找到位置
在进行判断哈希表中是否存在temp的key值时,也要注意判断条件,防止利用同个元素
在存储时,为了防止处理下标为0的情况,将哈希表对应下标+1

- 代码参考
1 class Solution { 2 public: 3 vector<int> twoSum(vector<int>& nums, int target) { 4 vector<int> B; 5 if(nums.empty()) 6 return B; 7 unordered_map<int,int> map; 8 //遍历整个数组nums,i为当前下标,每个nums[i]都判断map中是否存在temp=target-nums[i] 9 for(int i=0;i<nums.size();++i) 10 { 11 int temp=target-nums[i]; 12 //如果哈希表中存在key值为temp的元素,则找到这两个数,直接将下标返回 13 if(map.count(temp)!=0&&map[target-nums[i]]!=i+1) 14 { 15 //防止利用同个元素 16 B.push_back(i); 17 B.push_back(map[target-nums[i]]-1); 18 break; 19 } 20 //如果不存在,则将(nums[i],i)存入哈希表中 21 map[nums[i]]=i+1; 22 } 23 return B; 24 } 25 };

- 问题分析
这是一道经典的题型,凡是和“变位词”,“字母顺序打乱”相关的题目,都考虑字母出现的次数
我们既要统计字母表中字符出现的次数,又要统计单词中字母出现的次数,如果单词中字母出现的次数都小于或等于字母表中字母出现的次数,则这个单词可以由字母表拼写出来,否则不能被字母表拼写出来。
对于这种拼写单词的问题,我们可以设置一个长度为26的数组,数组中的下标为字符的ASCII码-a的ASCII码。数组的元素值为字符出现的次数。
我们遍历这个单词数组,如果单词数组中的单词中字符出现的次数小于或等于字母表中字符出现的次数,则这个单词可以由字母表拼写出来,否则不能。
- 代码参考
1 class Solution { 2 public: 3 int countCharacters(vector<string>& words, string chars) { 4 if(chars.empty()||words.empty()) 5 return 0; 6 //首先统计字母表中每个字符出现的次数 7 vector<int> chars_count=count(chars); 8 int res=0; 9 //统计words中每个元素中每个字符出现的次数 10 for(string& word:words) 11 { 12 vector<int> word_count=count(word); 13 if(iscontains(chars_count,word_count)) 14 res+=word.length(); 15 } 16 return res; 17 } 18 /*设置两个函数,一个函数判断字母表中字符出现的次数是否覆盖单词中字符出现的次数 19 如果字母表中出现的次数大于单词中字符出现的次数,则直接遍历下一个字符 20 如果字母表中出现的次数小于单词中出现的次数,则返回结果错误。 21 */ 22 bool iscontains(vector<int>&chars_count,vector<int> &word_count) 23 { 24 for(int i=0;i<26;++i) 25 { 26 if(chars_count[i]<word_count[i]) 27 return false; 28 } 29 return true; 30 } 31 /* 32 第二个函数,统计每个单词或者字符表中每个字符出现的次数,对于类似这种字母问题,直接用长度为26的数组,可以节省时间和空间,即统计26个字符出现的次数 33 设置一个长度为26的数组,数组下标为字符的ASCII码减去字符的ASCII码,数组的元素为每个字符出现的次数 34 */ 35 vector<int> count(string &words) 36 { 37 vector<int> word(26,0); 38 for(auto c:words) 39 { 40 word[c-'a']++; 41 } 42 return word; 43 } 44 };
- 问题分析
由于字符串中都是小写字母,因此我们可以利用长度为26的数组来实现哈希表
若两个字符串是字母异位词,则这两个字符串长度一样,每个字符出现的次数是相同的。
因此要判断字符串t是否是字符串s的字母异位词,我们可以采用如下算法
首先判断两个字符串是否相等,不相等则返回false
若相等,则利用长度为26的数组来实现哈希表,初始化数组中元素为0,并遍历字符串s和t
字符串s负责在对应位置+1
字符串t负责在对应位置-1
如果最终数组中所有元素值为0,则这两个字符串是字母异位词。
- 代码参考
1 class Solution { 2 public: 3 bool isAnagram(string s, string t) { 4 //字母异位词,即两个字符串中字符个数是相等的,只是可能在不同的位置 5 //首先判断两个字符串长度是否相同,若字符串长度不同,则直接返回false 6 if(s.size()!=t.size()) 7 return false; 8 //由于都是小写字母组成,因此用长度为26的数组即可 9 //首先将数组中每个元素值初始化为0 10 vector<int> word(26, 0); 11 //分别遍历字符串s和字符串t,字符串s则+1,字符串t则-1 12 for(int i=0;i<s.size();++i) 13 { 14 word[(int)s[i]-'a']++; 15 word[(int)t[i]-'a']--; 16 } 17 for(int i=0;i<26;++i) 18 { 19 if(word[i]!=0) 20 return false; 21 } 22 return true; 23 } 24 };

- 问题分析
要找到字母异位词分组,可以采用以下算法
首先遍历strs,对每个string进行排序,字母异位词排序结果相同
同时,字母异位词在map中的key值也是一样的,在map中添加相应的vector
- 代码参考
1 class Solution { 2 public: 3 vector<vector<string>> groupAnagrams(vector<string>& strs) { 4 vector<vector<string>> B; 5 if(strs.empty()) 6 return B; 7 unordered_map<string,vector<string>> word; 8 //对字符串数组中的每个字符串进行排序,字母异位词排序之后是同一个单词 9 for(auto c:strs) 10 { 11 //字母异位词排序之后是一样的,即unordered_map中的key值也一样 12 string temp=c; 13 sort(temp.begin(),temp.end()); 14 word[temp].push_back(c); 15 } 16 for(auto c:word) 17 { 18 B.push_back(c.second); 19 } 20 return B; 21 } 22 };

- 问题分析
什么
- 代码参考
1 class Solution { 2 public: 3 bool isIsomorphic(string s, string t) { 4 if(s.size()==0&&t.size()==0) 5 return true; 6 if(s.size()!=t.size()) 7 return false; 8 unordered_map<char,int> shash; 9 unordered_map<char,int> thsah; 10 for(int i=0;i<s.size();++i) 11 { 12 char ss=s[i]; 13 char tt=t[i]; 14 if(shash.count(ss)) 15 { 16 if(shash[ss]!=tt) 17 return false; 18 } 19 else if(thsah.count(tt)) 20 { 21 if(thsah[tt]!=ss) 22 return false; 23 } 24 else 25 { 26 shash[ss]=tt; 27 thsah[tt]=ss; 28 } 29 } 30 return true; 31 } 32 };
- 问题分析
要判断拥有的石头中有多少宝石,首先需要统计拥有的石头中总的石头中各类石头的数量
然后判断宝石的数量相加
- 代码参考
1 class Solution { 2 public: 3 int numJewelsInStones(string J, string S) { 4 //由于J和S中的字符都是字母且区分大小写,因此我们可以用数组来进行实现 5 //小写字母ASCII码为65-90,大写字母ASCII码值为97-122,设置长度为65的数组来存储 6 if(J.empty()||S.empty()) 7 return 0; 8 int total_count=0; 9 //首先统计你拥有的石头个数 10 vector<int> stone(65,0); 11 for(int i=0;i<S.size();++i) 12 { 13 stone[(int)S[i]-65]++; 14 } 15 for(int i=0;i<J.size();++i) 16 { 17 total_count+=stone[(int)J[i]-65]; 18 } 19 return total_count; 20 } 21 };
- 问题分析
最直观的方法是迭代并检查第一个数组nums1中的每个值也存在于num2中,如果存在,则将值添加到输出。
这道题是可以用unordered_set实现的,unordered_set和unordered_map底层是用哈希表实现的
set和map底层是用红黑树实现的
使用unordered_set实现。判断第二个数组中的每个值也存在于nums2中,如果存在,则将值添加到输出
- 代码参考
1 class Solution { 2 public: 3 vector<int> intersection(vector<int>& nums1, vector<int>& nums2) { 4 /* 5 这道题可以使用unordered_set实现,unordered_map和unordered_set底层实现是哈希表 6 map和set底层实现是红黑树,是有序的 7 这道题使用unordered_set实现,其是不包含重复元素的,因此首先转换成unordered_set实现去重 8 然后判断unordered_set中是否存在nums2中的元素,如果存在,则找到一个 9 */ 10 unordered_set<int> num1_set(nums1.begin(),nums1.end()); 11 unordered_set<int> ans; 12 for(auto num:nums2) 13 { 14 if(num1_set.count(num)==1) 15 ans.insert(num); 16 } 17 return vector<int>(ans.begin(),ans.end()); 18 19 } 20 };
- 问题分析
这道题和两个数组的交集1的差别是:两个数组的交集1中结果是唯一的,因此可以借助unordered_set来实现。
这道题的思路是类似的,但是可能有重复的交集,因此采用哈希表来存储每个元素及其出现的次数。
由于同一个数字在两个数组中可能出现多次,因此需要用哈希表存储每个数字出现的次数。对于一个数字,其在交集中出现的次数等于该数字在两个数组中出现次数的最小值。
算法如下
首先遍历第一个数组,并在哈希表中记录第一个数组中的每个数字及其对应出现次数。
然后遍历第二个数组,对于第二个数组中的每个数字,如果在哈希表中存在这个数字,则将该数字添加到答案,并较少哈希表中该数字出现的次数
- 代码参考
1 class Solution { 2 public: 3 vector<int> intersect(vector<int>& nums1, vector<int>& nums2) { 4 //假设第二个数组更大 5 if(nums1.size()>nums2.size()) 6 return intersect(nums2,nums1); 7 vector<int> result; 8 if(nums1.empty()||nums2.empty()) 9 return result; 10 unordered_map<int,int> num1_map; 11 //首先遍历第一个数组,在哈希表中记录第一个数组中的每个数字及对应出现的次数 12 for(auto c:nums1) 13 { 14 num1_map[c]++; 15 } 16 //遍历第二个数组,对第二个数组中的每个数字,如果在哈希表中存在这个数字,则将该数字添加到答案,并减少哈希表中该数字出现的次数 17 for(auto c:nums2) 18 { 19 if(num1_map.count(c)) 20 { 21 result.push_back(c); 22 --num1_map[c]; 23 if(num1_map[c]==0) 24 num1_map.erase(c); 25 } 26 } 27 return result; 28 } 29 };