搜索引擎
1.背景
目前正在进行搜索引擎的学习,决定写个博客来记录学习的过程。
2.搜索领域
当前搜索推荐都涉及互联网的各个领域,可以简单的粗分成这2类
- 综合领域:像百度、google、搜狗、360等,搜索全网内容,一般叫大搜。一般搜索的内容是互联网上的网页,多数是通过爬虫获取到,通过网页的标题和正文来搜索。
- 垂直领域:像视频、音乐、电商、小说等,只搜索特定领域的内容,一般叫垂搜或小搜。垂域搜索的数据,往往是非常结构化的,比如淘宝里的商品,优酷里的影片信息等,与网页相比,文本偏短。例如像xunlei 是资源的垂直搜索引擎,flickr 是photo/images,youtube 应该是视频,digg 是社会化新闻,ctrip/qunar应该是酒店、旅行相关,大众点评是餐馆,豆瓣是 book/movie/music。
3.几个基本概念
首先介绍几个缩写基本概念:
- 缩写
- query:搜索关键字,也叫keyword
- doc:被搜索的内容,比如一个网页,一部影响,一件商品,在索引里是一条记录,都叫一个doc
- QU:query understanding,查询理解,即对query进行分析,得到一些用户意图相关的信息,辅助检索
- index:索引
- term:query分词后,每个词,称为一个term
- 正排索引:以doc作为key,以这个doc包含的term或属性信息作为value,就是常规的数据库存储结构。便于通过docId,查询这个doc的属性信息。想像一下,如果要检索出所有包含“apple”的网页,需要将索引里所有doc遍历一遍。
- 倒排索引:与正排相反,以term作为key,以包含这个term的所有doc的ID作为value,构建出的KV结构。如果要检索出包含“apple”的网页,只需要以apple作为key,一把就能取出所有包含apple这个词的网页。
- 分词:又成为切词,就是讲句子或者段落进行切割,从中提取出包含固定予以的词。
- 停止词:在英语中包含了 a、the、and这样频率很高的词,如果这些词都被建到索引中进行索引的话,搜索引擎就没有任何意义了,因为几乎所有的文档都包含这些词。
- 排序,当输入一个关键字进行搜索时,可能会命中许多文档,搜索引擎给用户的价值就是快速找到需要的文档,因此需要将相关度更大的内容排到前面,以便使用户能够更快的筛选有价值的内容弄。
4.倒排索引
索引的存储结构
单词词典是倒排索引中非常重要的组成部分,它用来维护文档集合中出现过的所有单词的相关信息,同时用来记载某个单词对应的倒排列表在倒排文件中的位置信息。在支持搜索时,根据用户的查询词,去单词词典里查询,就能够获得相应的倒排列表,并以此作为后续排序的基础。
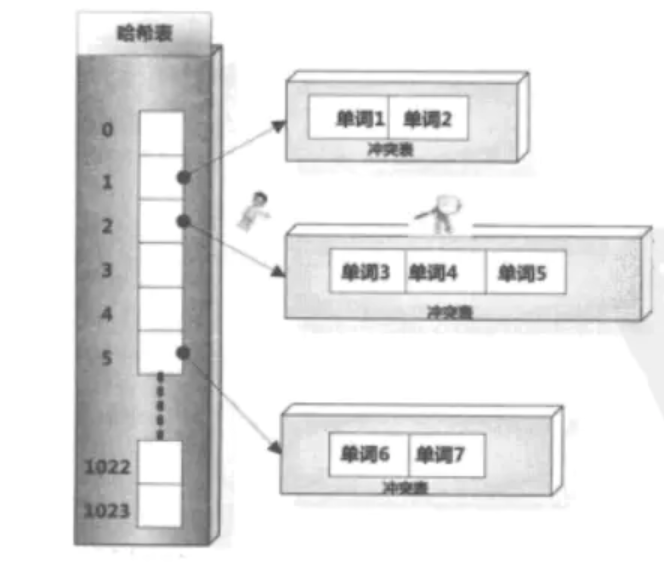
1)Hash的存储方式
在建立索引的过程中,词典结构也会相应地被构建出来。比如在解析一个新文档的时候,对于某个在文档中出现的单词T,首先利用哈希函数获得其哈希值,之后根据哈希值对应的哈希表项读取其中保存的指针,就找到了对应的冲突链表。如果冲突链表里已经存在这个单词,说明单词在之前解析的文档里已经出现过。如果在冲突链表里没有发现这个单词,说明该单词是首次碰到,则将其加入冲突链表里。这样的存储方式很类似于Java中HashMap解决hash冲突的方式。
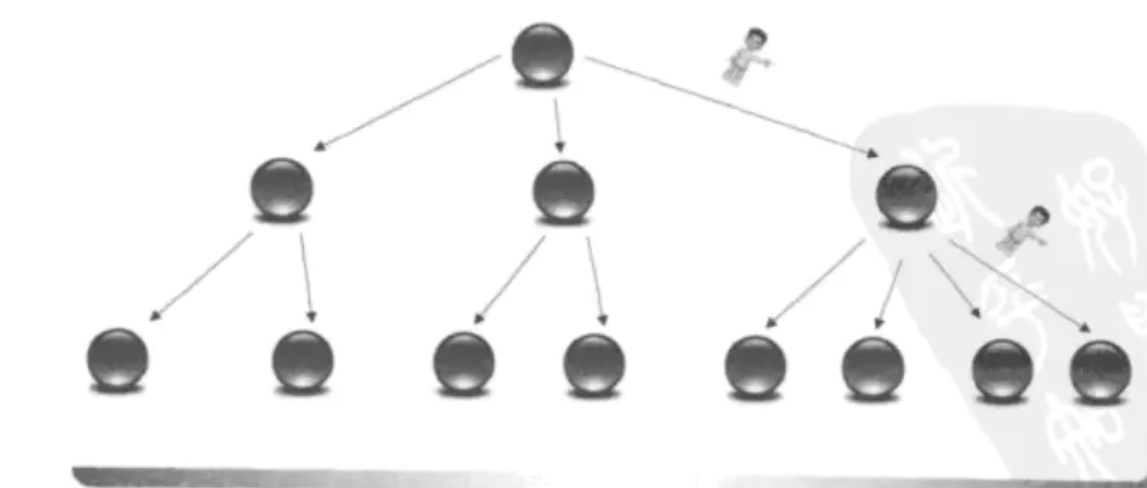
2)树形结构
B树(或者B+树的)存储方式,这点很类似于Mysql的Inoodb的存储引擎中采用B+树的方式来存储索引,由于采用了B树的结构,即索引存储在是一个平衡树,避免了查询极端的情况,由于有序,所以能根据字典项需要的大小顺序来构建索引,这样在检索中可以快速通过字典项比较大小,最终确定叶子结点中词汇的存储地址信息。(由于B树的构建复杂,这里就不过多的讲解,向深入了解,可以翻翻上学那会儿的《数据结构》那本书喔)
上面大致粗略的讲解了一下倒排索引的概念,其实在实际中,倒排索引还会进行索引压缩,排序的加工,也正因为这些加工,让其成为目前许多搜索引擎采用的索引方式。
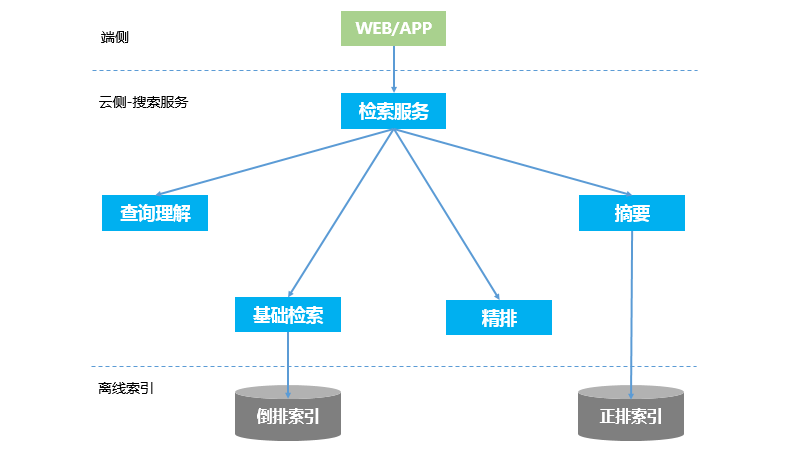
5.流程和架构
搜索引擎的在线检索架构如图1所示。主要包含以下几个模块:查询理解(QU),基础检索,精排(重排),摘要(高亮、飘红)。除此之外,可能还会有运营干预之类的模块。
垂搜与大搜的架构基本一致。相比大搜,垂搜在某些模块上会简化。比如摘要,垂搜会比大搜简单很多。
下面简单介绍下每个模块的功能
5.1 检索服务(编排)
图1中的检索服务,实际上是个编排模块,接受端侧的搜索请求,负责整个在线检索的流程串通,本身没有实质性的功能。所以,也是其中最简单的一个模块。
编排模型会依次调用查询理解、基础检索、精排、摘要这4个模块,每一个模块的输出,作为下一个模块的输入。
5.2 查询理解(QU)
QU的功能,是对用户输入的query进行分析,以支撑后续的搜索排序效果。
QU的主要功能包括:
- 分词:搜索|是|什么
- 实体识别:人名、地名、影片名、机构名、歌曲名等等
- 意图/需求识别:常见的意图类型包括:问答、新闻、软件下载、视频、小说等
- 同义词识别:
- 查询改写:
- 纠错:搜索阴晴 -> 搜索引擎
- 词权重计算:计算query分词后,每个term的权重是多少
- 核心词选择:query分词后,哪些词是必须命中的,即核心词只要没命中这个内容就不会被搜索出来
- 紧密度分析:query中,相邻两个词之间的紧密关系,是否需要连续命中
QU中很多模块的效果,依赖于NLP能力,例如分词、实体识别、意图识别等。像纠错、改写等,也强依赖于用户的行为日志。
5.3 基础检索
基础检索(粗排)是做第一轮检索,从全量索引中召回网页候选集(例如top1000),并做一个排序。整个搜索的过程,就像是一个漏斗筛选的过程,基础检索是第一次筛选,如果没有被筛选出来,就不会成为本次的搜索结果。
由于基础检索涉及的网页量非常大,对性能要求高,所以一般只用少量最重要的特征,相对简单的策略来做召回。不亦使用太多的特征和太复杂的模型。
检索的过程主要分2步,
- 根据query的核心词term,从倒排索引中取出倒排拉链。每个核心词对应一个倒排拉链,多个核心词的拉链取交,得到基础检索的一个候选集合。
- 对候选集中的每个doc,计算它与query的匹配分数以及doc本身的质量得分,合并后得到一个总的分数并做降序排序。最终,再按一个阈值(例如1000)做截断,作为基础检索的结果。
一个网页是否能被基础检索召回,主要取决于几个因素:1)doc是否满足term倒排求交条件;2)doc与query的相关性得分;3)doc本身的质量(静态特征,与query无关)
5.4 精排
精排是对基础检索召回的结果,做一个更精准的排序。由于基础检索召回的数量有限(1000条以内),相比粗排,精排需要处理的doc数量少了很多,就可以用更丰富的特征,更复杂的算法模型(LTR),以得到更精准的排序效果。
除了使用排序模型,精排也可以使用一些人工策略来调权。
在精排之后,也会根据运营干预的策略,对结果做进一步的调整干预。
最终,根据翻页参数,只返回10或15条结果给上游。
5.5 摘要
精排返回的结果,还要补充些信息,才能在终端界面上展示。例如淘宝搜索结果,需要展示商品的图片、标题、销量等一系列信息。
一般的垂直领域,只要把doc的几个属性展示出来即可。网页搜索比较特殊,一般网页正文很长,但是最终展示的只有简短的三两行文字片段。这个片段,就是网页的摘要信息。摘要模块的主要目标,主要就是从网页正文中,抽取出匹配最好的那一两个片段,并把与query匹配的那些词标红,让用户直观的看到这个网页与query的匹配关系。
6.分词
1. 分词粒度
例如北京疫情防控
- 最细粒度分词:【北京,疫情,防控】
- 正常粒度分词:【北京,疫情防控】
- 最粗粒度分词:【北京疫情防控】
- 混合粒度分词:【北京,北京疫情,北京疫情防控,疫情,疫情防控,防控】
2.构建索引
在构建索引时,为了扩大召回,一般要求粗细粒度都要有。
3.在线查询
- 在线检索时,分词的粗细粒度各有优劣。
- 粗粒度分词:
- 召回的数量少。例如,在线查询时,分成了【北京疫情防控】,那就搜索不到《北京疫情防治》之类的内容了。
- 搜索准确率高,只搜索出完整包含《北京疫情防控》,不会搜索出《广州疫情防控》之类的内容
- 性能快,只用一个粗粒度term搜索,倒排相对较短。只需要取一个倒排拉链,没有其它term参与打分计算。
- 细粒度分词:(与粗粒度分词的优劣正好相反)
- 召回数量多,可以搜索《北京疫情处理》《广州疫情防控》之类(如果多个term之间是或查询,不要求所有term都命中)。
- 准确率会下降,搜索出部分相关的内容。
- 处理逻辑更复杂。分词后,多个term之间的关系如何处理,是取交集还是并集?
- 粗粒度分词:
如果是约定俗成的内容,例如成语、人名、地名等,不建议再做进一步细分词。否则,搜索出的结果会有明显偏差。
如果是可粗可细的,可以考虑一个折中办法:先用粗粒度分词去做搜索,如果搜索结果够多、质量够好,就不再用细粒度分词去做检索。否则,如果搜索结果数量偏少,或质量不佳,则再细分词,去做进一步的查询。
举个例子:人名“周杰伦”,建索引时,尽可能的各种粒度都有,例如分成【周,周杰,周杰伦,杰伦】。
- 用户搜索“周杰伦”,只用粗粒度分词【周杰伦】,搜索出准确的内容。如果再细分出【周杰】,搜索出“周杰”相关的内容,明确主违背了用户的意图。
- 用户搜索“周”或“周杰”,也可以搜索出“周杰伦”的相关内容。因为用户有可能是想搜索周杰伦,未输入全就点击了搜索按钮。输入不全,在搜索中是一种常见的问题。
词形还原&词干提取
在涉及英语等语言时,会涉及时态、单复数等变化问题,中文里没有这个问题。分词时如果不考虑词形还原&干提取问题中,会导致漏召回。
- 词形还原(Lemmatization)
词形还原,是将词还原成最原始的状态。例如过去式、过去分词,变成原样(running -> run)。复数变成单数等(dogs -> dog)。
也就是用户在搜索dog时,也要能搜索出dogs的内容。同样,搜索dogs,也要能搜索出dog的内容。所以分词时,需要将dogs识别出原形是dog。
词形还原一般是通过词典实现,准确率高。也可以基于规则做,但是我们知道英语里不规则的单复数、时态例子太多了,用规则解决不了。
- 词干提取(temming)
词干提取是去除词的后缀,得到词根。与词形还原一个很明显的区别是,词形还原后的仍然是一个有意义的词,但是词干提取出来的词根,可能不是一个单词,只是单词的一部分。例如electricity的词根是electr。
相比词形还原,用了词干提取后,召回更多,准确率同时也会下降。
在搜索中,如果要使用词形还原与词干提取,用户输入的原词,与还原后的词或词根,这2者之间的权重可能要做些区分。否则,会搜索出一些有偏差的结果。
7.不可省词
倒排求交
解决求交选词
https://www.cnblogs.com/grindge/p/12241855.html
8.Query改写