第二章总结了二分分类与逻辑回归,第三章关于浅层神经网络
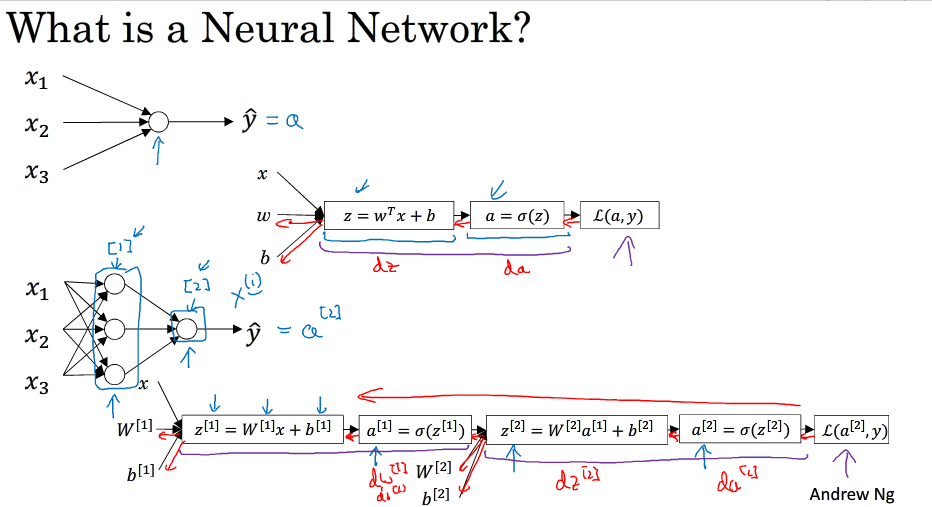
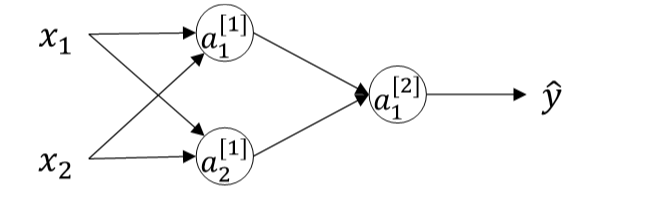
神经网络的结构与逻辑回归类似,只是神经网络的层数比逻辑回归多了一层,多出的中间一层叫隐藏层,那么,神经网络的计算就相当于多进行一次逻辑回归的计算
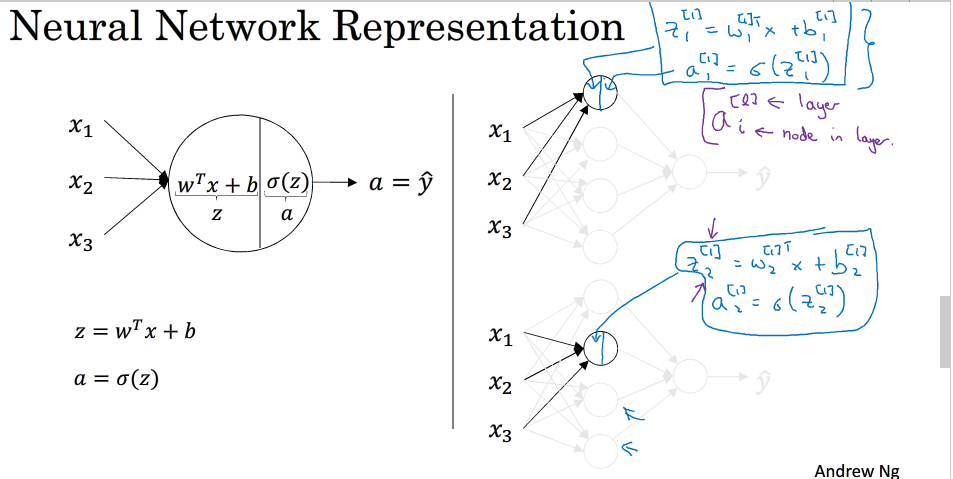
正向传播过程分成两层,第一层是输入层到隐藏层,用上标[1]来表示:第二层是隐藏层到输出层,用上标[2]来表示
神经网络的正向传播过程为:
每一个神经元的计算过程如下:
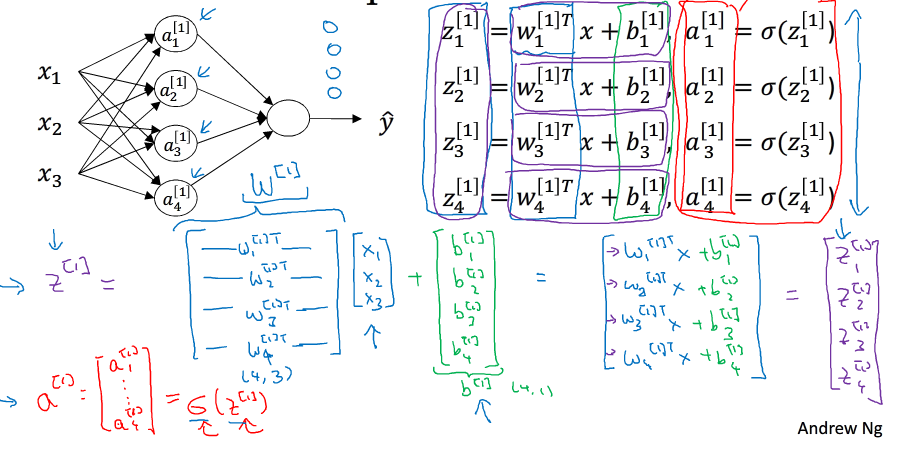
关于隐藏层对应的权重W [1] 和常数项b [1] ,W [1] 的维度是(4,3)。这里的4对应着隐藏层神经元个数,3对应着输入层x特征向量包含元素个数。常数项 b[1] 的维度是(4,1),这里的4同样对应着隐藏层神经元个数。关于输出层对应的权重W[2] 和常数项b [2] ,W [2] 的维度是(1,4),这里的1对应着输出层神经元个数,4对应着隐藏层神经元个数。常数项b [2] 的维度是(1,1),因为输出只有一个神经元。总结一下,第i层的权重W [i] W[i] 维度的行等于i层神经元的个数,列等于i-1层神经元的个数;第i层常数项b [i] 维度的行等于i层神经元的个数,列始终为1
为了方便运算,我们将其向量化:
先用乘法表示,可以看为

不使用for循环,利用矩阵运算的思想,输入矩阵X的维度为(n x ,m)。这样,我们可以把上面的for循环写成矩阵运算的形式

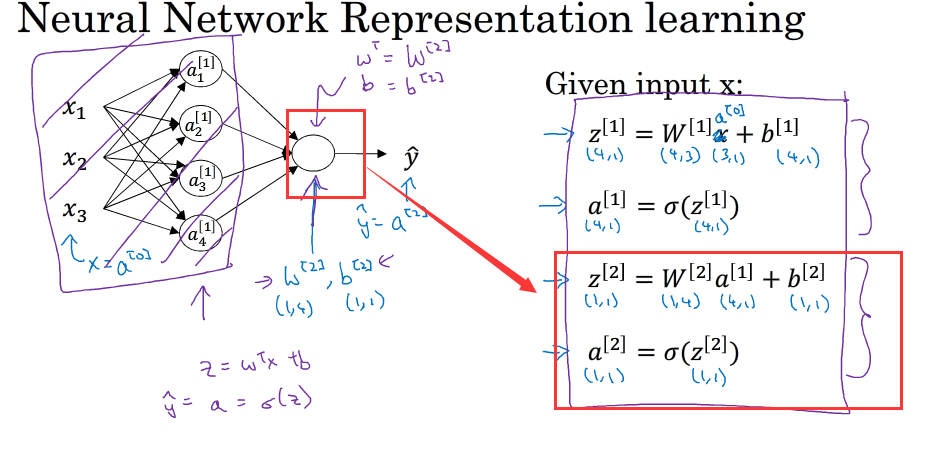
W[1]的维度为(i,nx) i为隐藏层神经元的个数,b[1]的维度为(i,1), i为隐藏层神经元的个数,Z[1]的维度为(i,m) m为样本个数,A[1]的维度为(i,m),W[2]的维度为(n,i),n为输出层个数,b[2]的维度为(n,1),Z[2]的维度为(n,m),n为输出层个数 A[2]的维度为(n,m)
ps:输入层X也可用A[0]表示
Activation Function:
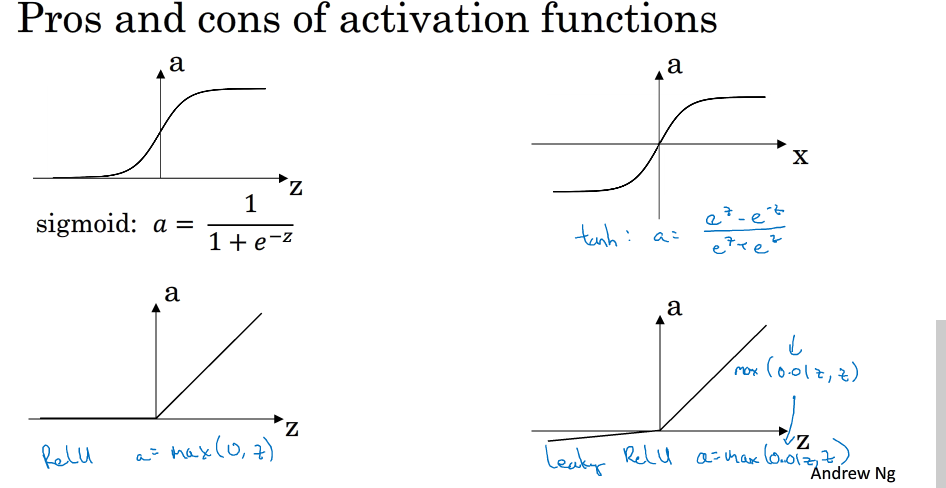
tanh 函数与sigmoid 函数区别: tanh函数几乎在各个方面都比sigmoid函数表现好,因为tanh函数的取值范围在[-1,+1]之间,隐藏层的输出被限定在[-1,+1]之间,可以看成是在0值附近分布,均值为0。这样从隐藏层到输出层,数据起到了归一化(均值为0)的效果.而对于输出层的激活函数,因为二分类问题的输出取值为{0,+1},所以一般会选择sigmoid作为激活函数。
sigmoid函数和tanh函数,有这样一个问题,就是当|z|很大的时候,激活函数的斜率(梯度)很小。因此,在这个区域内,梯度下降算法会运行得比较慢。在实际应用中,应尽量避免使z落在这个区域,使|z|尽可能限定在零值附近,从而提高梯度下降算法运算速度
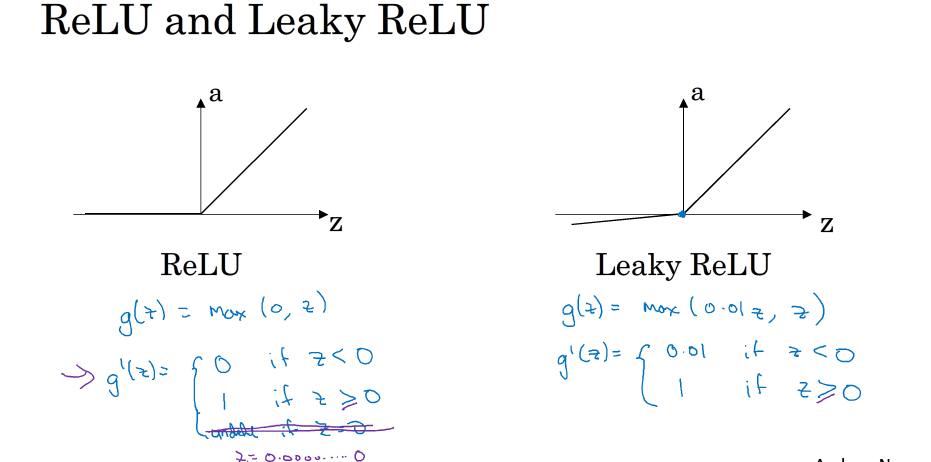
为了弥补sigmoid函数和tanh函数的这个缺陷,就出现了ReLU激活函数。ReLU激活函数在z大于零时梯度始终为1;在z小于零时梯度始终为0;z等于零时的梯度可以当成1也可以当成0,实际应用中并不影响。对于隐藏层,选择ReLU作为激活函数能够保证z大于零时梯度始终为1,从而提高神经网络梯度下降算法运算速度。但当z小于零时,存在梯度为0的缺点,实际应用中,这个缺点影响不是很大。为了弥补这个缺点,出现了Leaky ReLU激活函数,能够保证z小于零是梯度不为0。
最后总结一下,如果是分类问题,输出层的激活函数一般会选择sigmoid函数。但是隐藏层的激活函数通常不会选择sigmoid函数,tanh函数的表现会比sigmoid函数好一些。实际应用中,通常会会选择使用ReLU或者Leaky ReLU函数,保证梯度下降速度不会太小。其实,具体选择哪个函数作为激活函数没有一个固定的准确的答案,应该要根据具体实际问题进行验证(validation)。
为什么用使用非线性函数:如果隐藏层和输出层都是用线性函数最后就可以化为一个 w'x+b的函数,这样就和简单的使用线性模型没有任何关系,过程如下:

隐藏层必须使用非线性激活函数
另外,如果所有的隐藏层全部使用线性激活函数,只有输出层使用非线性激活函数,那么整个神经网络的结构就类似于一个简单的逻辑回归模型,而失去了神经网络模型本身的优势和价值。
当然,如果是预测问题而不是分类问题,输出y是连续的情况下,输出层的激活函数可以使用线性函数。如果输出y恒为正值,则也可以使用ReLU激活函数,具体情况,具体分析。
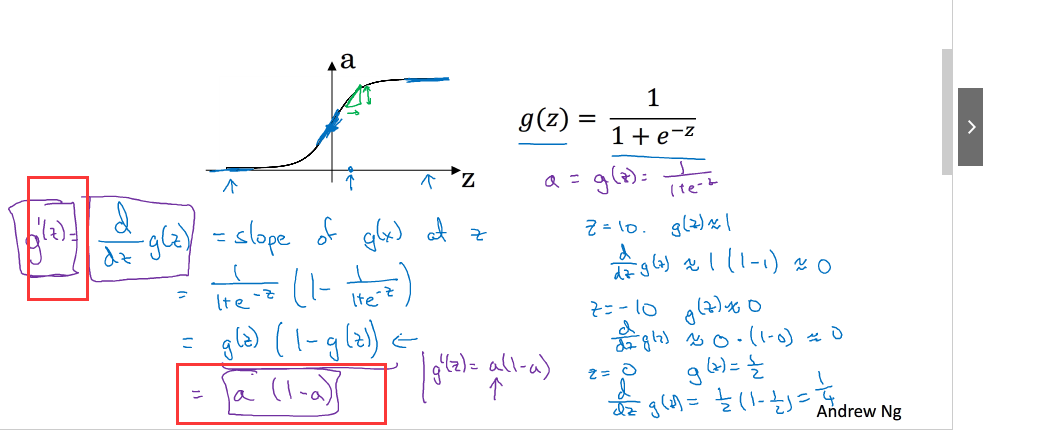
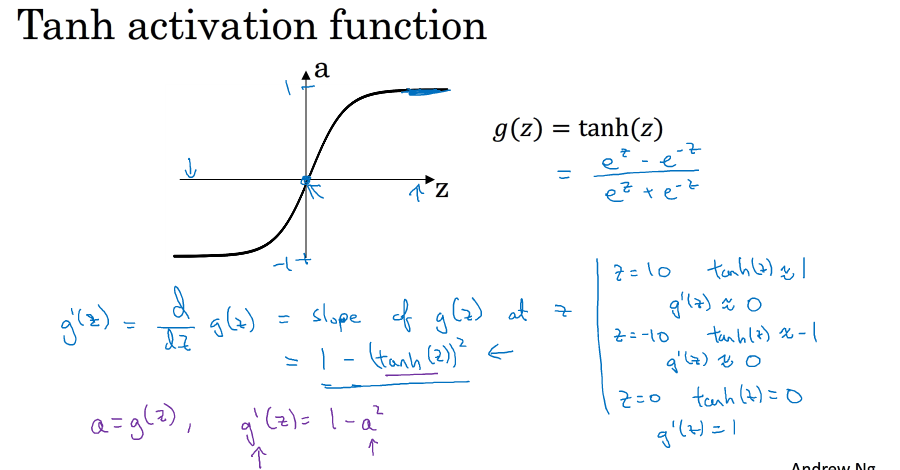
各个激活函数的导数:
Gradient descent for neural networks:
神经网络中的梯度下降,关于反向传播的求导问题,与第二章的差不多,求导采用求导中的链式法则,一步步进行运算,即可求得结果

Random Initialization
关于w和b的初始化,如果将w全部初始化为0,就会得到 a1[1]=a2[1] 。经过推导得到dz [1] 1 =dz [1] 2 dz1[1]=dz2[1] ,以及dW [1] 1 =dW [1] 2 dW1[1]=dW2[1] 。因此,这样的结果是隐藏层两个神经元对应的权重行向量W [1] 1 W1[1] 和W [1] 2 W2[1] 每次迭代更新都会得到完全相同的结果, W1[1] 始终等于W [1] 2 W2[1] ,完全对称。这样隐藏层设置多个神经元就没有任何意义了。值得一提的是,参数b可以全部初始化为零,并不会影响神经网络训练效果。
python中初始化随机变量w可以用以下代码:
W_1 = np.random.randn((2,2))*0.01
b_1 = np.zero((2,1))
W_2 = np.random.randn((1,2))*0.01
b_2 = 0
这里我们将W [1] 1 W1[1] 和W [1] 2 W2[1] 乘以0.01的目的是尽量使得权重W初始化比较小的值。之所以让W比较小,是因为如果使用sigmoid函数或者tanh函数作为激活函数的话,W比较小,得到的|z|也比较小(靠近零点),而零点区域的梯度比较大,这样能大大提高梯度下降算法的更新速度,尽快找到全局最优解。如果W较大,得到的|z|也比较大,附近曲线平缓,梯度较小,训练过程会慢很多。
当然,如果激活函数是ReLU或者Leaky ReLU函数,则不需要考虑这个问题。但是,如果输出层是sigmoid函数,则对应的权重W最好初始化到比较小的值。