1.1 Train/dev/test sets
在构建一个神经网络的时候我们往往需要设计很多参数,如:layers,learning rates ,acivation functions,hidden units, 而这些参数我们往往不能一次性就能设计到成为了最佳的参数,往往是我们自己有一些想法,然后写出代码,开始实验,然后开始调整,再次更改代码实验,就这样一步步调整,得到最佳的参数.使神经网络的性能最佳.
目前深度学习被应用到很多领域,如NLP,Vision,Speech recognize等等,往往在某个领域的效果好的深度神经网络不能直接应用在其他领域中.
设置最佳的train/dev/test sets能够提高训练的效率.
train set用于训练算法模型,dev set 用于验证各个算法情况,来选择最好的算法,test set 用于测试算法的最好情况,作为该算法的无偏估计。

在训练样本比较少的情况,我们可以设置train/dev/test set 的比值为70/30/0 or 60/20/20
训练样本比较庞大的时候,可以设置他们的比值为98/1/1,样本越大,那么train所占的比值便越大,因为我们的目的是得到最佳的神经网络模型,而样本十分庞大时,dev/test sets 的比值小也会有庞大的样本,它们只是用来验证与测试最佳的神经网络,并不需要数目巨大的样本,所以它们的比值可以设计的相对更小一些.

我们往往会遇到一种情况:假设我们做了一个app要对猫的图片进行一个判断,训练的与 验证/测试的样本来源不同,解决这个问题的方法是保证dev/test sets的来源一致
值得一提的是,训练样本非常重要,通常我们可以将现有的训练样本做一些处理,例如图片的翻转、假如随机噪声等,来扩大训练样本的数量,从而让该模型更加强大。即使Train sets和Dev/Test sets不来自同一分布,使用这些技巧也能提高模型性能。
如果没有Test sets也是没有问题的。Test sets的目标主要是进行无偏估计。我们可以通过Train sets训练不同的算法模型,然后分别在Dev sets上进行验证,根据结果选择最好的算法模型。这样也是可以的,不需要再进行无偏估计了。如果只有Train sets和Dev sets,通常也有人把这里的Dev sets称为Test sets,我们要注意加以区别。
1.2~1.3 Bias and Variance
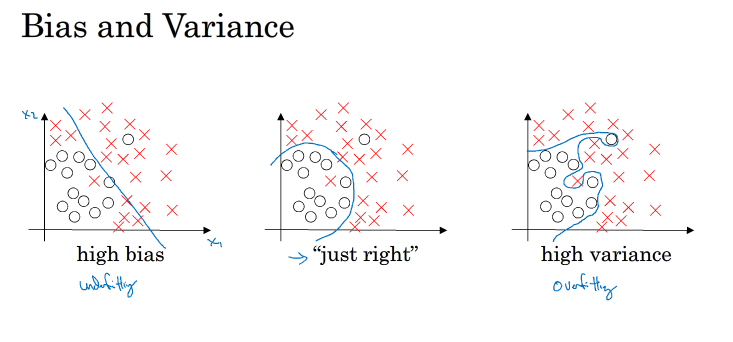
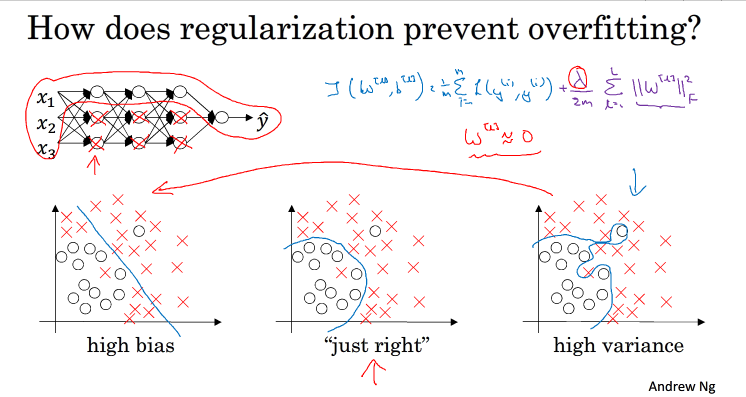
输入特征与输出值 接近一个线性关系时,这种欠拟合的情况我们可以称之为高偏差, 相反的出现过拟合的情况时,我们称之为高方差. 而上图中间那张就是我们所期望得到的.接下来我们通过一些数据来更加直观的理解什么是高偏差 ,什么是高方差
假设我们train set error 与test set error如下所示:

第一种情况,train set error 小,而dev set error大,说明过拟合,属于high variance,第二种,train set error 较大,dev set error 接近,欠拟合,属于high bias,
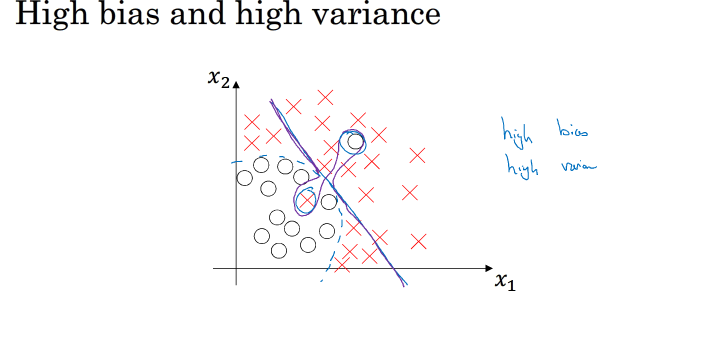
第三种情况train set error 较大,且dev set error 与train set error 相差大,那么既是high variance 又是high bias,图像如下 紫色线表示:
那么该如何使得偏差减小来得到最佳的神经网络模型呢,方法如下:
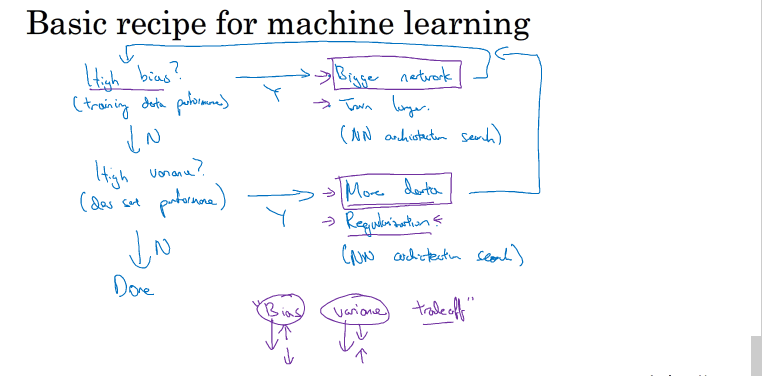
high bias:用更复杂网络
high variance:更多的数据,正则化,完善网络
1.4 Regularization
回顾一下之前的logistic regression,采用L2 regularization 结果如下:

这里我们只是对w进行了一个正则化,因为w的维度相对于b来说比较大,所以b可以忽略
我们把||w [l] || 2 ||w[l]||2 称为Frobenius范数,记为||w [l] || 2 F 。一个矩阵的Frobenius范数就是计算所有元素平方和再开方,如
这里要注意的是,当我们对w进行正则化的时候,更新参数w的时候,dw也应该要变化

此时w也叫weight decay,这是因为更新w[l]时会比没有正则项的时候少αλ/m *w[l],不断迭代,w就会不断更新,不断减小.
除了L2 regularization 以外,还有L1 regularization

与L2 regularization相比,L1 regularization得到的w更加稀疏,即很多w为零值。其优点是节约存储空间,因为大部分w为0。然而,实际上L1 regularization在解决high variance方面比L2 regularization并不更具优势。而且,L1的在微分求导方面比较复杂。所以,一般L2 regularization更加常用。
1.5 Why regularization reduces overfitting
为什么正则化可以减少过拟合
当λ足够大的时候,w[l]约等于0,即该神经网络中的某些神经元对整个网络基本没影响了,整个nn由复杂变得简单,识别特征的复杂度也变得更简单
因此,选择合适大小的λ λ 值,就能够同时避免high bias和high variance,得到最佳模型。
另一种直观的理解是如下:
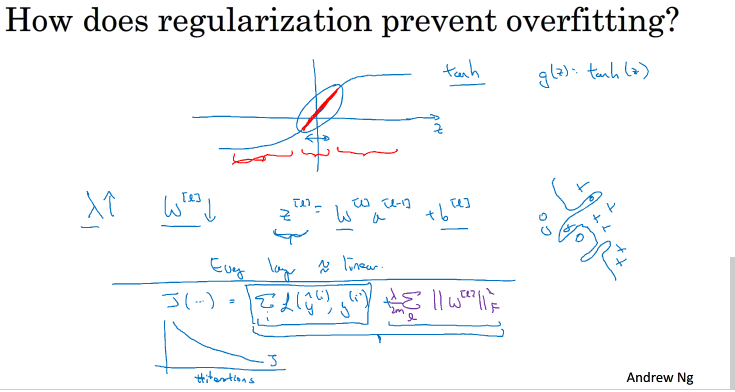
假设激活函数为tanh函数,调整λ使得w足够小,当w很小的时候,z也变得很小,g(z)趋向于一个线性函数,整个模型趋向于一个线性回归,这就完成了high variance 到high bias 的改变
1.6 dropout regularizationn
Dropout是指在深度学习网络的训练过程中,对于每层的神经元,按照一定的概率将其暂时从网络中丢弃。也就是说,每次训练时,每一层都有部分神经元不工作,起到简化复杂网络模型的效果,从而避免发生过拟合。

用Inverted dropout实现dropout ,假设有一个NN,要对第三层进行dropout,令keep_prob=0.8,设一个d3的随机向量,该随机向量的维度与a[3]保持一致,让其小于keep_prob,则其中80%的元素为1,20%的元素为0。 然后对第3层的神经元进行一个删减,a3= np.multiply(a3,d3),相乘使得其中20%的值为0,即作为下一个输入层的值为0,对下一个输出层便不会存在影响.
最后,还要对a3进行scale up处理,即:
a3/= keep_prob
进行这一步的原因是使得下一层的期望输入值不发生改变,删减20%之后,便要除以80%
Inverted dropout的另外一个好处就是在对该dropout后的神经网络进行测试时能够减少scaling问题。因为在训练时,使用scale up保证a3的期望值没有大的变化,测试时就不需要再对样本数据进行类似的尺度伸缩操作了。
对于m个样本,单次迭代训练时,随机删除掉隐藏层一定数量的神经元;然后,在删除后的剩下的神经元上正向和反向更新权重w和常数项b;接着,下一次迭代中,再恢复之前删除的神经元,重新随机删除一定数量的神经元,进行正向和反向更新w和b。不断重复上述过程,直至迭代训练完成。
值得注意的是,使用dropout训练结束后,在测试和实际应用模型时,不需要进行dropout和随机删减神经元,所有的神经元都在工作。
1.7 understand dropout

dropout 能起作用的原因是,他会随机的删除某些隐藏单元,使得下一层的输出值不会过分的依赖于某一个隐藏单元,从而实现了降低权重的效果
在使用dropout 的时候,对于整个神经网络影响最大的层keep_prob可以调低一些,如上图第二层的w维度为(7,7),对整个NN影响最大,所以设计keep_prob可以调小一些,而影响小的可以keep_prob调大一些
一般来说,神经元越多的隐藏层,keep_out可以设置得小一些.,例如0.5;神经元越少的隐藏层,keep_out可以设置的大一些,例如0.8,设置是1。另外,实际应用中,不建议对输入层进行dropout,如果输入层维度很大,例如图片,那么可以设置dropout,但keep_out应设置的大一些,例如0.8,0.9。总体来说,就是越容易出现overfitting的隐藏层,其keep_prob就设置的相对小一些。没有准确固定的做法,通常可以根据validation进行选择。
使用dropout的时候,可以通过绘制cost function来进行debug,看看dropout是否正确执行。一般做法是,将所有层的keep_prob全设置为1,再绘制cost function,即涵盖所有神经元,看J是否单调下降。下一次迭代训练时,再将keep_prob设置为其它值。
1.8 other regularization methods
对于处理过拟合问题我们可以提供更多的样本,关于样本的提供,我们能对已有的样本进行处理得到新的样本,这叫data augmentation,如下:

另一种防止过拟合的方法是early stoping
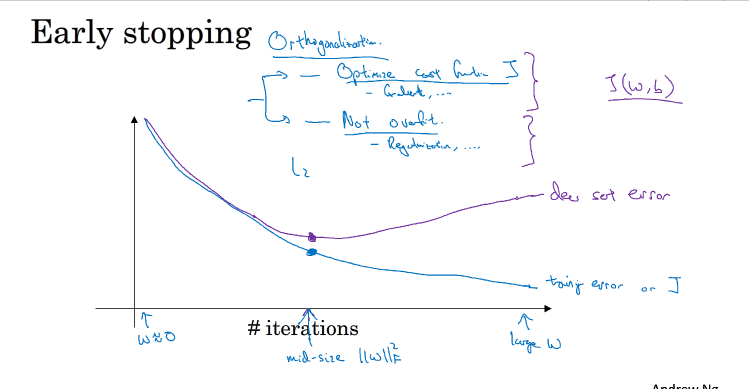
一般train set error 随着迭代次数增加而减小,而dev/test sets 会先减少后增加
Early stopping的做法通过减少迭代次数来防止过拟合,同时实现既减少了cost function J,有不会产生过拟合,但并没有分开解决的好,L2 regularization能分开解决J和过拟合的问题,L2 regularization常用,但L2 的参数λ选择较复杂,early stopping胜在简单.
1.9 Normalizing Inputs

对数据进行一个归一化可以提高训练的速度,归一化的步骤:
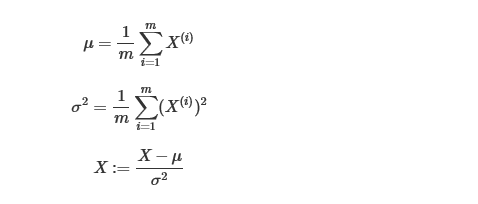
值得注意的是对训练集的数据归一化训练后,dev/test set 验证/测试时也要进行一个归一化
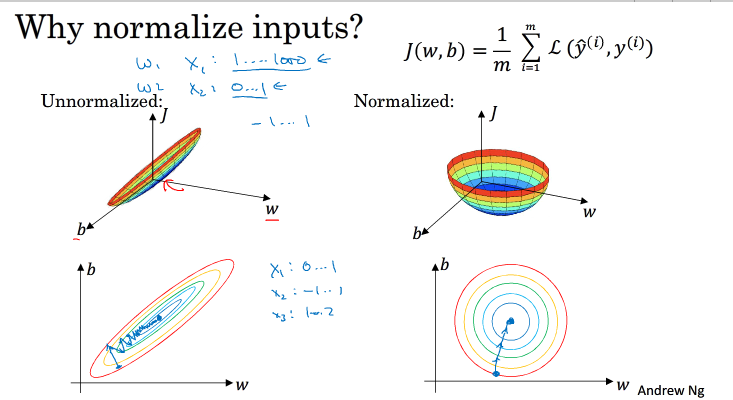
归一化的原因是使得w的数量级相差不多,以便于更好的梯度下降
假如输入特征是二维的,且x1的范围是[1,1000],x2的范围是[0,1]。如果不进行标准化处理,x1与x2之间分布极不平衡,训练得到的w1和w2也会在数量级上差别很大,这样导致的结果是cost function与w和b的关系可能是一个非常细长的椭圆形碗。对其进行梯度下降算法时,由于w1和w2数值差异很大,只能选择很小的学习因子 α ,来避免J发生振荡。一旦α 较大,必然发生振荡,J不再单调下降
如果进行了标准化操作,x1与x2分布均匀,w1和w2数值差别不大,得到的cost function与w和b的关系是类似圆形碗。对其进行梯度下降算法时, α 可以选择相对大一些,且J一般不会发生振荡
另外一种情况,如果输入特征之间的范围本来就比较接近,那么不进行标准化操作也是没有太大影响的。但是,标准化处理在大多数场合下还是值得推荐的。
1.10 Vanish and Exploding gradients
梯度消失和梯度爆炸指的是神经网络中计算的梯度非常小或非常大
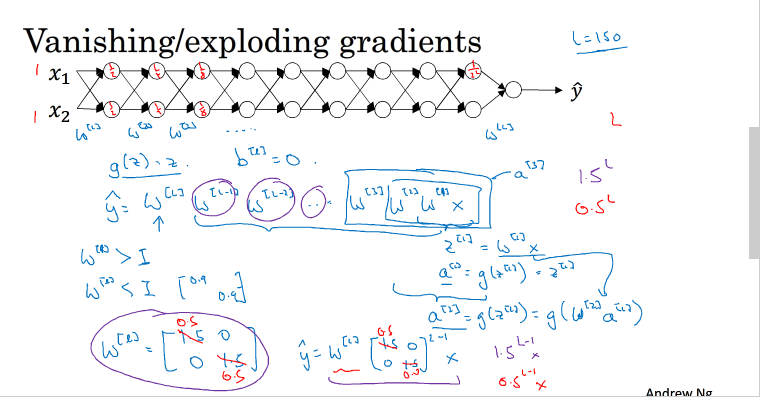
举一个例子:
假设b[l]为0,那么最后的输出y hat 为 w[l]*w[l-1]*...w[1]*x的一个函数,如果每一层的w都大于1,那么每一层的输出值会呈现一个指数的形式增加,如果每一层的w都小于1,会呈指数的形式递减,如上图所示
1.11 Weight Initialization for Deep Networks

如果激活函数是tanh,在初始化w时,令其方差为
1/n。相应的python伪代码为:
w[l] = np.random.randn(n[l],n[l-1])*np.sqrt(1/n[l-1]) 如果激活函数是ReLU,权重w的初始化一般令其方差为2n 2n :
w[l] = np.random.randn(n[l],n[l-1])*np.sqrt(2/n[l-1]) - 1
除此之外,Yoshua Bengio提出了另外一种初始化w的方法,令其方差为2n [l−1] n [l] 2n[l−1]n[l] :
w[l] = np.random.randn(n[l],n[l-1])*np.sqrt(2/n[l-1]*n[l]) - 1
至于选择哪种初始化方法因人而异,可以根据不同的激活函数选择不同方法。另外,我们可以对这些初始化方法中设置某些参数,作为超参数,通过验证集进行验证,得到最优参数,来优化神经网络。
1.12~1.14 Gradient check
Back Propagation神经网络有一项重要的测试是梯度检查(gradient checking)。其目的是检查验证反向传播过程中梯度下降算法是否正确。
函数在某点的梯度如下:
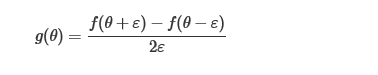
神经网络中的梯度检查如下:


1.w,b组成的函数J(w,b),把w,b看做一个向量θ,
2.反向传播的dw,db组成一个向量dθ
则对1的求导应约等于2中的dθ,如上图所示
通过比较两者的欧式距离(Euclidean),来比较两者的相似度
一般来说,如果欧氏距离越小,例如10 −7 10−7 ,甚至更小,则表明dθ approx 与dθ 越接近,即反向梯度计算是正确的,没有bugs。如果欧氏距离较大,例如10 −5 10−5 ,则表明梯度计算可能出现问题,需要再次检查是否有bugs存在。如果欧氏距离很大,例如10 −3 10−3 ,甚至更大,则表明dθ approx 与dθ 差别很大,梯度下降计算过程有bugs,需要仔细检查。
使用梯度检查的注意事项:

-
不要在整个训练过程中都进行梯度检查,仅仅作为debug使用。
-
如果梯度检查出现错误,找到对应出错的梯度,检查其推导是否出现错误。
-
注意不要忽略正则化项,计算近似梯度的时候要包括进去。
-
梯度检查时关闭dropout,检查完毕后再打开dropout。
-
随机初始化时运行梯度检查,经过一些训练后再进行梯度检查(不常用)。