第2章 Spark角色介绍及运行模式
2.1 集群角色
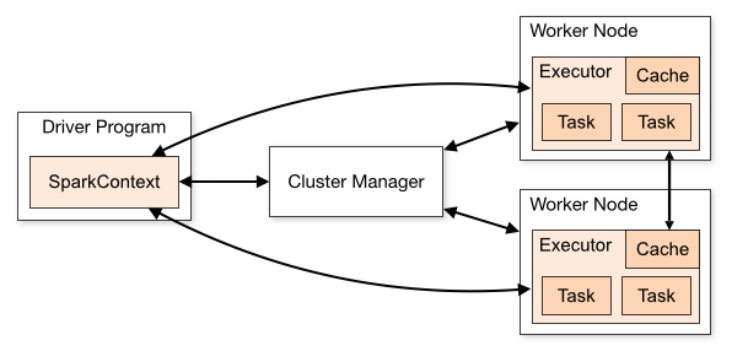
从物理部署层面上来看,Spark主要分为两种类型的节点,Master节点和Worker节点:Master节点主要运行集群管理器的中心化部分,所承载的作用是分配Application到Worker节点,维护Worker节点,Driver,Application的状态。Worker节点负责具体的业务运行。
从Spark程序运行的层面来看,Spark主要分为驱动器节点和执行器节点。
2.2 运行模式
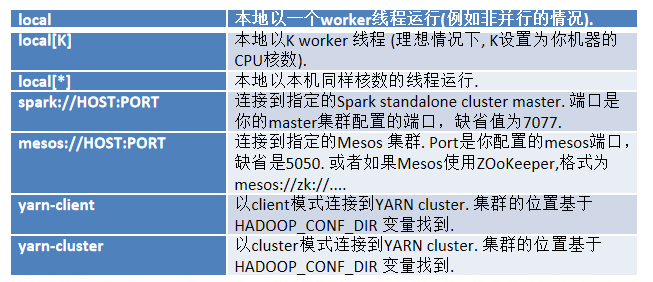
1)Local模式: Local模式就是运行在一台计算机上的模式,通常就是用于在本机上练手和测试。它可以通过以下集中方式设置master。
local: 所有计算都运行在一个线程当中,没有任何并行计算,通常我们在本机执行一些测试代码,或者练手,就用这种模式;
local[K]: 指定使用几个线程来运行计算,比如local[4]就是运行4个worker线程。通常我们的cpu有几个core,就指定几个线程,最大化利用cpu的计算能力;
local[*]: 这种模式直接帮你按照cpu最多cores来设置线程数了。
2)Standalone模式: 构建一个由Master+Slave构成的Spark集群,Spark运行在集群中。

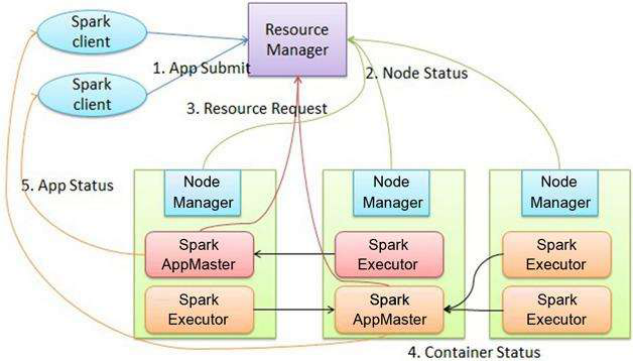
3)Yarn模式: Spark客户端直接连接Yarn;不需要额外构建Spark集群。有yarn-client和yarn-cluster两种模式,主要区别在于:Driver程序的运行节点。
yarn-client:Driver程序运行在客户端,适用于交互、调试,希望立即看到app的输出
yarn-cluster:Driver程序运行在由RM(ResourceManager)启动的AP(APPMaster)适用于生产环境
4)Mesos模式:Spark客户端直接连接Mesos;不需要额外构建Spark集群。国内应用比较少,更多的是运用yarn调度。