https://www.cnblogs.com/wupeiqi/p/9078770.html
wusir讲
Python垃圾回收机制

引用计数器为主,标记清除和分代回收为辅
a.什么是引用计数器(源码:object.h)
当创建一个对象后,python内部有一个变量ob_refcnt保存着使用此内存的个数.
a = 123
b = a
del b
b. 循环引用
a = [11,22] a 1
b = [33,44]
a.append(b) b 的引用 2
b.append(a) a 2
del a # a = 0 才是垃圾 ,才会被回收
del b
内存中还有a和b [11,22] .. 计数都是1了
c. 标记清除和分代回收
python中维护了一个数据结构, 不为0的对象放入,python解释器回去逐一查找每个元素,检查是否有循环引入,如果有,都-1
2
1
0
如果是垃圾,就标记0,不是垃圾上升成1代,下一层扫10次,上一层扫1次,(700,10,10) 根据多少开始扫(900,200开始扫...) (时间效率)
在这个例子中程序执行完del语句后,A、B对象已经没有任何引用指向这两个对象,但是这两个对象各包含一个对方对象的引用,虽然最后两个对象都无法通过其它变量来引用这两个对象了,这对GC来说就是两个非活动对象或者说是垃圾对象,但是他们的引用计数并没有减少到零。因此如果是使用引用计数法来管理这两对象的话,他们并不会被回收,它会一直驻留在内存中,就会造成了内存泄漏(内存空间在使用完毕后未释放)。为了解决对象的循环引用问题,Python引入了标记-清除和分代回收两种GC机制。
a = [11, 22]
b = [33, 44]
a.append(b) # a [11, 22, [33, 44]]
b.append(a) # [33, 44, [11, 22, [...]]] 循环了 a加b的时候,b又加a
# b [33,44,[11,22]] a.append() 可能是a[11,22,[33,44],[...]]
- https://blog.csdn.net/xiongchengluo1129/article/details/80462651
- https://www.jianshu.com/p/ef8a218c6b89
如果用两个队列实现一个栈?
把后面的几个添加到b的队列,然后剩下一个
和上面一样,把后面的几个添加到b的队列,然后剩下一个
什么是MySQL的存储过程?
pymysql
存在数据库中的一个sql语句,并为其取一个名字.
-- 创建存储过程
delimiter //
create procedure p1()
BEGIN
select * from t1;
END//
delimiter ;
-- 执行存储过程
call p1()
-
有参数的
对于存储过程,可以接收参数,其参数有三类:
- in 仅用于传入参数用
- out 仅用于返回值用
- inout 既可以传入又可以当作返回值
-
-- 创建存储过程 delimiter \ create procedure p1( in i1 int, in i2 int, inout i3 int, out r1 int ) BEGIN DECLARE temp1 int; DECLARE temp2 int default 0; set temp1 = 1; set r1 = i1 + i2 + temp1 + temp2; set i3 = i3 + 100; end\ delimiter ; -- 执行存储过程 set @t1 =4; # @类似于全局变量 set @t2 = 0; CALL p1 (1, 2 ,@t1, @t2); SELECT @t1,@t2;
delimiter //
默认情况下,不可能等到用户把这些语句全部输入完之后,再执行整段语句。
因为mysql一遇到分号,它就要自动执行。
即,在语句RETURN '';时,mysql解释器就要执行了。
这种情况下,就需要事先把delimiter换成其它符号,如//或$$
这样只有当//出现之后,mysql解释器才会执行这段语句 https://www.cnblogs.com/nickup/p/6628892.html
.
什么是MySQL的触发器?
对某个表进行【增/删/改】操作的前后如果希望触发某个特定的行为时,可以使用触发器,触发器用于定制用户对表的行进行【增/删/改】前后的行为。 (类似于装饰器?)
1、创建基本语法
# 插入前
delimiter //
CREATE TRIGGER tri_before_insert_tb1 BEFORE INSERT ON tb1 FOR EACH ROW #每行
BEGIN
IF NEW. NAME == 'alex' THEN
INSERT INTO tb2 (NAME)
VALUES
('aa')
END
END//
delimiter ;
..................................after.................
基本语法
delimiter 自定义结束符号
create trigger 触发器名字 触发时间 触发事件 on 表 for each row
begin
-- 触发器内容主体,每行用分号结尾
end
自定义的结束符合
delimiter ;
原文链接:https://blog.csdn.net/babycan5/article/details/82789099
###### mysql视图?
CREATE VIEW v1 AS
select * from score where student_id = 2 and course_id = 1;
查过的结果集当做一张表 (简化方便,类似于函数?)
select * from v1 (虚拟的)
select * from v1 where sid = 1 ;
###### http和Https的区别?****
http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议。
:不安全/80
:安全/443 = http+ssl
对称加密: 双方密钥相同(123加密123解密,密码易被劫持)
非对称加密:公钥/私钥 (加密/解密都行)
数字证书: (机构将公司信息加到证书里,还有公钥) / 密钥自己拿着 访问网站,浏览器生成随机字符串(对称密钥),用公钥加密,(内存中放着) 发给网站,(私钥解密) 拿到随机字符串 .
然后根据对称密钥加密后的消息发送.
用到了对称密钥和非对称密钥. 非对称密钥是传对称密钥的,对称密钥是加密的
对称加密:
双方是一样的,也是明文所以,容易被捕获和更改.
非对称加密:
公钥每个人都有是用来加密的或者解密,密钥是唯一的,用来解密.或者加密. b为了证明是a传过来的内容,先用a的私钥加密,然后用b的公钥加密. 然后b用b的私钥解密用a的公钥解密就可以证明是a传过来的内容.
数字签名:(验证数据来源以及数据完整性)
对整个内容加密如果内容多,太浪费时间,用哈希算法,给所有的加个密,为摘要,然后在对摘要加上a的信息,的hash值为h1,传给b,b用a的公钥解密,成功则说明是a传过来的,对正文进行hash运算,得到hash值为h2, h1=h2,则邮件未被更改,但是不足: c趁a不在,用c的私钥加密,然后发送了c的内容和公钥,那么b接收的就不知道是谁的了.就要用数字证书
非对称加密:
数字签名:
###### 数字证书:
首先A去找"证书中心"(certificate authority,简称CA),为公钥做认证。证书中心用自己的私钥,对A的公钥和一些相关信息一起加密,生成"数字证书"(Digital Certificate):
A在邮件正文下方除了数字签名,另外加上这张数字证书
收到Email后用CA的公钥解密这份数字证书,拿到A的公钥,然后验证数字签名,后面流程就和图1的流程一样了
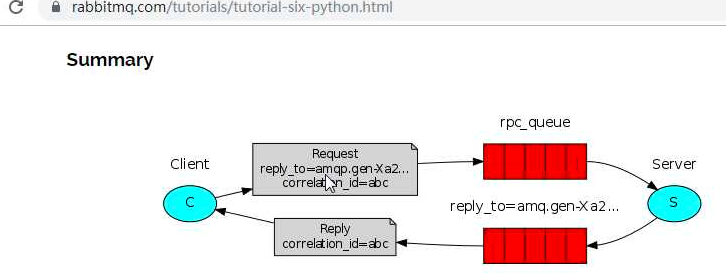
###### 什么是rpc?
远程过程调用
api接口可以(drf)
基于消息队列 :*放任务 取任务 (两个队列) 第二个:(收结果)
放:(任务信息,随机字符串(名字))
了解<https://www.rabbitmq.com/tutorials>官方文档
###### redis aof 和 rdb
aof 记录所有的命令 回复的慢 执行命令
rdb 快照 每60秒 (到59秒)可能失真
###### redis和memcache区别?
memcache: 数据类型单一; 无法持久化;不支持高可用;不支持集群;
redis: 有5大数据类型;可以持久化;支持高可用;支持集群;
##### lulin面试题:
###### django中间件
###### 跨域
什么是跨域?
当前浏览器访问a.com域名,按钮ajax向b.com发送请求(可以发过去,b的服务器也可以处理,处理完也可以返回),但是返回到浏览器后, 浏览器给阻止.
为什么会存在跨域?
浏览器具有同源策略.
如何解决跨域?
jsonp
cors, 百度设置一个响应头 Access-Control-Allow-Origin = "*"
def index(request):
data = HttpResponse('xxxx')
data['Access-Control-Allow-Origin'] = "*"
return data
###### django请求生命周期
###### ajax
###### MVC & MTV
- model view controller
- model template view
- 模型 模板 视图
###### ORM的批量创建
bulk_create()
##### 其他的lidaichuang面试题目:
Python和Go的区别?以及各自的优势?
列表生成式的好处?
列表推导式是将所有的值一次性加载到内存中
生成器是将列表推导式的[]改成(),不会将所有的值一次性加载到内存中,延迟计算,一次返回一个结果,它不会一次生成所有的结果
search和match的区别?
match()函数只检测字符串开头位置是否匹配,匹配成功才会返回结果,否则返回None
search()函数会在整个字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
什么是贪婪匹配?
什么是贪婪匹配:贪婪匹配在匹配字符串时总是尝试匹配尽可能多的字符。
什么是非贪婪匹配:与贪婪匹配相反,非贪婪匹配在匹配字符串时总是尝试匹配尽可能少的字符。
在python中默认采用的是贪婪模式,使用非贪婪模式的话,只需要在量词后面直接加上一个问号”?”。
m1 = re.search(f'w+',a).group()
m2 = re.search(f'w+?',a).group()
33dkfkdsji3456
3
面向对象中的`__cal__`方法的作用?
对象后面加括号,触发执行。
对于 call 方法的执行是由对象后加括号触发的,即:对象() 或者 类()()
什么是元类?【不好】
一切皆对象:类实际上就是一个对象
Person类也是一个对象,那他一定是由一个类实例化得到的,这个类就是元类
type是内置的一个元类,所有的类都是由type实例化得到的
产生类的类叫做元类
print(type(object)) # type object 是 type类型
print(issubclass(type, object)) # type 是 object 的子类 # class type(object):
super的作用?【不好】
返回一个父类或兄弟类类型的代理对象,让你能够调用一些从继承过来的方法。
它有两个典型作用:
a. 在单继承的类层次结构中,super()可用于引用父类而不显式父类名称,从而使代码更易于维护。
b. 在多重继承中,可以保证公共父类仅被执行一次。
什么是偏函数?
所以,简单总结functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
int2 = functools.partial(int, base=2) # 否则的话,默认是10进制
functools.partial就是帮助我们创建一个偏函数的,不需要我们自己定义int2(),可以直接使用下面的代码创建一个新的函数int2:
def int2(x, base=2):
return int(x, base)
e2:
max2 = functools.partial(max, 10)
实际上会把10作为*args的一部分自动加到左边,也就是:
max2(5, 6, 7)
装饰器的应用场景?什么是单例模式?
csrf_token
自定义标签,过滤器
auth_required
staticmethod和classmethod的区别?
面向对象的上下文管理?【不好】
栈和队列的区别?
如何做链表的逆置?【回去写】
class Foo:
def init(self,item):
self.item = item
self.next = None
循环反转单链表
-- coding:utf-8 --
class ListNode:
def init(self, x):
self.val = x
self.next = None
class Solution:
def ReverseList(self, pHead):
if not pHead or not pHead.next:
return pHead
last = None
while pHead:
tmp = pHead.next
pHead.next = last
last = pHead
pHead = tmp
return last
什么是中序遍历?
先遍历左子树,然后访问根结点,最后遍历右子树。
如何将一个列表中第二大的数找到?
对列表进行倒叙排序sorted(),然后取索引为1的数
如果遥过yield自己实现一个协程?【不好】
async、await关键字?【不好】
async 是定义一个协程函数的
阻塞操作必须使用await关键字进行挂起
async def request(url):
print('请求前')
# response = aiohttp.get(url)
# 老师模拟的请求我以为真的请求的,也是请求那里是 time.sleep() 不支持异步
await asyncio.sleep(2) # 阻塞操作必须使用await关键字进行挂起
for url in urls:
c = request(url)
task = asyncio.ensure_future(c) # 任务对象和协程对象一样 # 现在还未执行
# print(task) # <Task pending coro=<request() running at D: ...
task.add_done_callback(callback) # callback 里没有task参数,前面就是task调用的 # # 报错: asyncio.base_futures.InvalidStateError: Result is not set.
loop = asyncio.get_event_loop()
loop.run_until_complete(task) # 但是这里放c 协程对象会出错 cannot reuse already awaited coroutine
# print(task) # <Task finished coro=<request() done, defined at D: ... # 执行完
什么是I0多路复用?【不好】
线程池和进程池的用法?
你了解的MySQL引影和区别?
组合索引想要命中需要遵循什么?什么是MySQL的执行计划?
什么是MySQL的慢日志?【不好】
什么是分库分表?【不好】
你能想到的性能优化?
django和flask的区别?
wsgi的作用?
什么是cgi?【没讲过】
F和Q是什么?
django的orm中on_delete的作用?
django中方法:only、defer?
django中的 selete_related、prefetch_related的作用?【不好】
有外键存在时,可以很好的减少数据库请求的次数,提高性能
select_related通过多表join关联查询,一次性获得所有数据,只执行一次SQL查询
prefetch_related分别查询每个表,然后根据它们之间的关系进行处理,执行两次查询
django如何做读写分离?
django如何写原生SQL?
redis和memcache的区别?
m 只有一种数据类型 字符串 k/v 可以json字典
redis 五种
m:无法持久化(断电 不行),不支持高可用; 不支持集群;
redis 可以持久化 高可用 (哨兵); 集群;
redis如何保留热点数据?过期策略
redis的分布式锁是什么?
redis如何实现的高可用?
rabbmitMQ和kafka的区别?
什么是celery?
一个简单、灵活且可靠、处理大量消息的分布式系统,可以在一台或者多台机器上运行。
单个 Celery 进程每分钟可处理数以百万计的任务。
通过消息进行通信,使用消息队列(broker)在客户端和消费者之间进行协调。
安装方式
pip install -U Celery
ORM和原生SQL的区别?
drf如何实现的认证流程?
获取原生request, self._request
获取认证类的对象, request.authenticator
1.封装Request
认证成功,走反射方法
认证失败,抛异常
实现认证走perform_authentication
里面有request.user
获取认证对象, 进行一步步的认证
self._authenticate()
执行认证类的authenticate方法
1.如果auth方法抛出异常,self._not_auth()执行
2.有返回值,必须得是元祖(request.user, request.auth)
3.返回None , 当前不处理,下一个认证来处理
重写Authtication
重写函数
authenticate
authenticate_header
drf如何实现的截流?
gitm何做协同开发?
基于gitlab做的协同开发,每个人一个分支.
git如何做code review?
基于pull request来实现 (gitee)
组长(同意,合并)
权限组件的实现流程?权限都用到了那些表?
如何实现粒度控制到按钮?
如果让你实现的话,如何实现粒度控制到行?【思考题】
权限信息为什么要放在session中?放在session中有什么不好的地方?
django中如何实现事务?
crm有应用到数据库的锁吗?
crm系统都有哪些功能?
为什么不用现成的crm而来自己开发?
有听说过有第三方现成的crm吗?
第二张
深浅拷贝?
浅拷贝: 只拷贝第一层元素
深拷贝: 不可变数据类型共用一个内存空间的值,可变数据类型重新开辟空间,不管嵌套多深
你了解的内置函数?【不好】
filter
map
zip
reduce
常用的模块?【不好】
os
time
hashilib
sys
什么是迭代器?什么是生成器?
拥有__iter__方法和__next__方法
迭代器
面向对象中_new_方法的作用?_call_方法的作用?【不好】
进程、线程、协程的区别?【一般】
进程
特点:操作系统级别 开销大 数据隔离
资源分配的最小单位 数据不安全
可以利用多核
线程
特点:操作系统级别 开销小 数据共享
被cpu调度的最小单位 数据不安全
可以利用多核
协程
特点:用户级别 开销极小 数据共享的
不能利用多核 从代码级别来看数据安全
进程
你用过什么起进程的模块么?
multprocessing
concurrent.futrues 进程池
Process(target=func,args=(参数,)).start()
join()
ProcessPoolExcutor
为什么要起进程?
爬虫的时候 数据分析做的比较复杂 比较多 -- 开启多进程
为什么要爬虫?
线程
你用过多线程么? 用过、爬虫
django(默认就是线程)socketserver(多线程+io多路复用)flask(默认用协程,协程找不到,就用线程)
你知不知道python的GIL锁
这个锁有什么效果
你写代码的时候用到过哪些锁
互斥锁(只能acquire一次) 递归锁(在一个线程中acquire多次也不会死锁)
互斥锁 效率高、用好了也不会出错
logging queue list 是否线程安全
logging queue 线程安全
list 的所有方法都是线程安全的 append insert extend pop
list[0] += 1 线程不安全了
dict update setdefault 都是线程安全的
dic[key] += 1 线程不安全
协程
gevent asyncio
你用过协程么?
爬虫 aiohttp
web项目 sanic asyncio模块
线程和协程的区别
操作系统控制线程 程序员代码用户控制协程
协程的本质就是一条线程
线程对于IO操作的感知力更强 :打开文件 网络操作 时间模块
协程对于IO操作的感知力弱很多 :网络操作 时间操作
文件操作频繁的情况下 协程无法规避掉这部分io操作
协程有哪些模块?
gevent
acyncio :aiohttp sanic
什么是GL锁?
GIL:全局解释器锁 , Cpython解释器下的
,导致了同一进程中多个线程不能利用多核
相对安全 gc垃圾回收机制,不想加太多细粒度的锁
TCP三次握手和四次挥手?
三次握手
tcp协议在建立连接的时候经历的过程
第一次由客户端向server端发送Syn请求
server端在发送ack回复的时候顺便发送syn请求
客户端收到请求和回复再确认发送一次ack请求
就建立起一个全双工的通信
四次挥手
tcp协议 再断开连接的时候经历的过程
第一次由客户端或者server端发起 发送FIN请求
对方回复ack
对方发送fin请求
接收并回复ack
断开了两端的连接
为什么要有三次握手和四次挥手?
OSI7层模型?为什么要有这么多层?
应用层 http https ftp snmp (会话层 表示层 应用层)
传输层 tcp udp 四层路由器 四层交换机
网络层 ip 路由器 三层交换机
数据链路层 arp 交换机 网卡
物理层
分层的目的是利用层次结构可以把开放系统的信息交换问题分解到一系列容易控制的软硬件模块-层中,而各层可以根据需要独立进行修改或扩充功能,同时,有利于个不同制造厂家的设备互连,也有利于大家学习、理解数据通讯网络。
OSI参考模型中不同层完成不同的功能,各层相互配合通过标准的接口进行通信。
left join和inner join的区别?【不好】
外链接之左连接:优先显示左表全部记录
全外连接:显示左右两个表全部记录
char和varchar的区别?
varchar 变长的 时间换空间型
char 定长的
如何导出和导入数据?【不好】
组合索引想要命中索引应该遵循什么原则?【不好】
列举http请求头?
user-agent
session
cookie
请求方法:
get
post
put : update
delete
options
patch : partial_update
head
trace
列举http常见的状态码?
1xx(消息) 接受了 还没处理完
2xx(成功) 接受理解处理完
3xx(重定向) 访问了一会又去访问了别的(更新的)
老网站大用户量,重新推广开新域名 跳转:localtion.href='网址' 跳过去了
4xx(请求错误) 请求不和发
5xx (服务器错误) 服务器在处理某个正确请求是发生错误
django请求生命周期。
请求进来,路由系统,先走as_view(),然后在走dispatch,反射
def as_view():
def view():
return view
然后相当于执行的view()函数 as_view()
就成fbv那样了, 执行的view , 然后就是 view() : def view() : return self.dispatch() # drf , 请求封装 ,认证, 权限 , 节流, 反射对应的method执行
走models数据操作 走templates返回页面 中间件 response回去
列举django的orm操作?
django orm中on_delete的作用?
django如何执行原生SQL?
项目的功能?发布流程?实现方式?
ansible模块?
ansible 和saltstack的对比?
ansible连不上远程机器怎么办?
项目实现时间?负责内容?
协同合作?
git 常用命令?
git init
git add
git commit -m ” “
git push
git pull
svn:
区域:
工作区: 当前的目录
缓存区: add之后的区域
本地仓库:commit之后的区域
远程仓库:
git log 查看当前版本之前的所有的提交记录
git reflog 查看所有的提交记录
git log -n # 显示最近的#条数据
git log -p 对比每次提交的差异
git log --format="%an:%ae:%s:%h" 自定义输出格式
git reset --hard hash值 回滚到自定的版本
git checkout -- file 将文件回滚到最近的一次提交
git status 查看状态
git reset HEAD file 将制定的文件从缓存区拉取到工作区,只是颜色的变化
git diff 对比工作区和本地仓库的区别
git diff --cached 对比本地仓库和缓存区的区别
git stash
git stash list 查看stash
git stash drop 删除快照
git stash pop 恢复快照并删除快照 = git stash apply + git stash drop
git stash apply stashid 恢复快照
git branch 查看分支
git branch name 新建分支
git checkout name 切换分支
git branch -d name 删除分支
git merge name 在合并到的分支上合并
git checkout -b name 创建分支并切换分支=git branch name +git chekcout name
git tag 查看标签
git tag -a name -m “” 创建一个tag
git tag -a name -m "" hash 以hash为模板创建一个tag
git tag -d name 删除一个本地的tag git push origin --tags
git tag -d v0.5 #删除本地
git push origin :refs/tags/name 删除远程仓库的tag
git push origin :refs/tags/v0.5 #往上推送一个空的=删除远程
git clone 将远程仓库的代码拉取到本地,默认是master
git push origin master 上传
git pull origin dev 下载
新电脑如何快速拿到代码?【不好】
环境搭建
安装所需要的模块(requirement)
数据库(和老板要测试库或者手动搭建一个)
功能和url去项目中找代码加注释(粗略看,抓紧为公司办事)
切记: 不要多问技术问题,可以问业务问题
主动:汇报最近的工作情况(周报).
celery使用方式?
为什么要使用celery执行异步任务?
如何代码实现异步?
如何单独文件上传?exce表如何设计?
redis数据类型?
redis是一种高级的key:value存储系统,其中value支持五种数据类型
字符串(strings)
散列(hashes)
列表(lists)
集合(sets)
有序集合(sorted sets)
redis 字符串常用方法?
set 设置key
get 获取key
append 追加string
mset 设置多个键值对
mget 获取多个键值对
del 删除key
incr 递增+1
decr 递减-1
redis 超时时间?【不好】
redis 的使用场景?【不知道】
性能高,读取速度10万次每秒
写入速度8万次每秒
所有操作支持原子性
用作缓存数据库,数据放在内存中
替代某些场景下的mysql,如社交类app
大型系统中,可以存储session信息,购物车订单
运维开发几个人?离职原因?
redis面试题:
redis和memcached比较?
redis中数据库默认是多少个db 及作用?
python操作redis的模块?
如果redis中的某个列表中的数据量非常大,如果实现循环显示每一个值?
redis如何实现主从复制?以及数据同步机制?
redis中的sentinel的作用?
如何实现redis集群?
redis中默认有多少个哈希槽?
简述redis的有哪几种持久化策略及比较?
列举redis支持的过期策略。
MySQL 里有 2000w 数据,redis 中只存 20w 的数据,如何保证 redis 中都是热点数据?
写代码,基于redis的列表实现 先进先出、后进先出队列、优先级队列。
如何基于redis实现消息队列?
如何基于redis实现发布和订阅?以及发布订阅和消息队列的区别?
什么是codis及作用?
什么是twemproxy及作用?
写代码实现redis事务操作。
redis中的watch的命令的作用?
基于redis如何实现商城商品数量计数器?
简述redis分布式锁和redlock的实现机制。
什么是一致性哈希?Python中是否有相应模块?
如何高效的找到redis中所有以oldboy开头的key?