之前写的mysql去重多个字段,是不太对的。因为我是用distinct (xm,phone)去重,然后将xm,phone为唯一的数据插入新表,但是数据中有三个字段:id,xm,phone,我上一种方法是没法插入id的,因为xm,phone重复的加上id,就变成不重复的了。
例子:
id nam phone
1 张三 123
2 张三 123
这本来是重复的数据,但是如果distinc * 就成了两条不重复的数据了,因为前面的id不重复
INSERT into chongfubiao_quchong_copy (id, nam, phone)
select distinct * from chongfubiao_quchong ;
而下面这种又会有语法错误[Err] ERROR: INSERT has more target columns than expressions;因为查询的是两栏插入的是三栏
INSERT into chongfubiao_quchong_copy1 (id, nam, phone)
select distinct nam,phone from chongfubiao_quchong ;
没法处理。然后从网上搜索,查到下面答案:
sql中如何删除一个表中重复的记录? https://zhidao.baidu.com/question/331566667.html
[SQL]delete from jck_rk_info_quchong_endwhere sfzh in (select sfzh from jck_rk_info_quchong_end group by sfzh having count(sfzh) > 1)and bh not in (select min(bh) from jck_rk_info_quchong_end group by bh having count(bh )>1)
时间: 14.839s
受影响的行: 2026251
不是很好,因为把重复的都去除,连本身也去除。 要实现的是,重复数据中多余的数据删除,只保留重复数据的一条数据
又搜到一个和上面的语句差不多,不知道为啥,怎么判断语句的时候都是min呢?都是not in 呢? 反正我都没有成功?原因如下:
#插入重复的的数据 多个值去重后的一个 # 这个语句是有问题的,主要在于not in min(),只能筛选出最小的那个,比如有 1,2,3,后续保留的是2,3。还是有两个重复的,而且只能去除一个,不是每个重复的去除一个(1000个重复的去除1000个)。是所有重复的中去除一个(1000个重复的去除1个)。
INSERT into quchongcharu_copy (id,name,sfzh)select * from quchongcharuwheresfzh in (select sfzh from quchongcharu group by sfzh having count(sfzh) > 1)and id not in ( select min(id) from quchongcharu group by id having count(id )> 1);
既然大家都用这个实现了去重。而不是把重复的本身也去除掉,可能是我使用有点问题。下面这个也是同样的语句没法,但是画的图好,帮助我实现了我的需求。
思路来源,和其他分享一样都是用的max,不能实现我的需求。不过用图形象,启发了我。我试了下min也不行,后来试了用in 不用not in就可以了。https://blog.csdn.net/wumian0123/article/details/81539631
修改后的查询语句如下-对重复的语句进行去重仅保留本身:
SELECT id,name,sfzh
FROM quchongcharu
WHERE
(sfzh , name) IN
(SELECT sfzh,name FROM quchongcharu
GROUP BY sfzh, name
HAVING COUNT(*)>1)
AND
id IN
(SELECT min(id) FROM quchongcharu
GROUP BY sfzh,name
HAVING COUNT(*) > 1)
数据
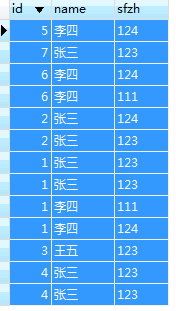
查询出重复数据的本身
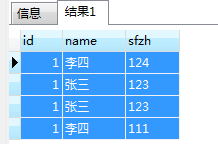
由于1 张三 123、1 张三 123数据id也重复,然后后面的and判断语句是根据id筛选本身的,没法排除,其余均可以。关于id一般都是编号,每个人的id都不是一样的,所以实际场合应该符合条件(但是这个问题现在仍然存在,后续想解决)
语句解析(感觉好的点在于and 还有 in 还有 min最小值保证唯一)
上面语句在于where后的筛选语句
# 这句是统计出sfzh,name分组后,分组的sfzh,name出现数目大于1的即为重复
(sfzh , name) IN
(SELECT sfzh,name FROM quchongcharu
GROUP BY sfzh, name
HAVING COUNT(*)>1)
中间and是在上面统计出来的数据做交集。上面统计出很多重复数据
如:
1 李四 124
6 李四 124
下面
id IN
(SELECT min(id) FROM quchongcharu
GROUP BY sfzh,name
HAVING COUNT(*) > 1)
下面的语句也是出现大于1的重复,但是查询的是min(id),最小值只有一个,所以就保证唯一,不重复了:也就是id= 1 (所以我想不懂很多博客写的 not in max值,那如果 id为 1、2、4,not in 4 ,不是还有1、2吗?而且 not in 一个值,不是还有很多吗,不如in 一个值来的好啊)
1 李四 124
现在想了想,既然id in min 就能保证唯一然后后面的语句是查询重复的。那么可以不用上面的and了。
简化版查询去重语句
SELECT id,name,sfzh
FROM quchongcharu
where
id IN
(SELECT min(id) FROM quchongcharu
GROUP BY sfzh,name
HAVING COUNT(*) > 1)
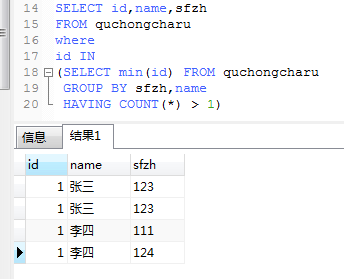
结果是一样的。
上面的语句只是找出了重复数据的本身,还有不重复数据无需去重,也需要合并一下
不重复的语句用
(sfzh , name) IN
(SELECT quchongcharu.sfzh,quchongcharu.name
FROM quchongcharu
GROUP BY quchongcharu.sfzh,quchongcharu.name
HAVING COUNT(*)=1)
查询
因为都得包括所以取并集,用or,
SELECT id,name,sfzh
FROM quchongcharu
where
id IN
(SELECT min(id) FROM quchongcharu
GROUP BY sfzh,name
HAVING COUNT(*) > 1)
or
(sfzh , name) IN
(SELECT quchongcharu.sfzh,quchongcharu.name
FROM quchongcharu
GROUP BY quchongcharu.sfzh,quchongcharu.name
HAVING COUNT(*)=1) ;
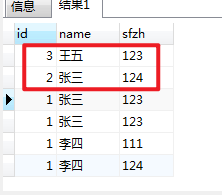
然后可以更新到一张新表中。
insert into 新表 (id,name,sfzh) 上面sql
虽然id实际生活中不会重复,但是也有可能会重复,如果不设置主键,而且上面的也看这不好看。 1 张三 123 确实是重复的,没有去重。 虽然把
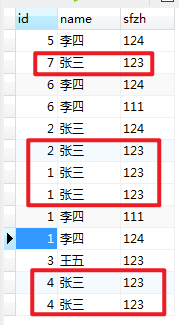
其他id的张三123去重了。
关于查询到的下述数据的去重
虽然可以如下操作
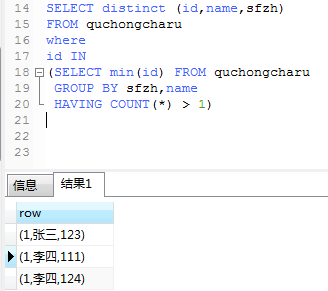
但是是row的格式().不是数据表
搜了下distinct的原理,没打搞懂,但是说和group by相似,先排序,然后。。。
https://blog.csdn.net/xpzhang123/article/details/50175755?utm_source=copy
就去搜group by的用法:
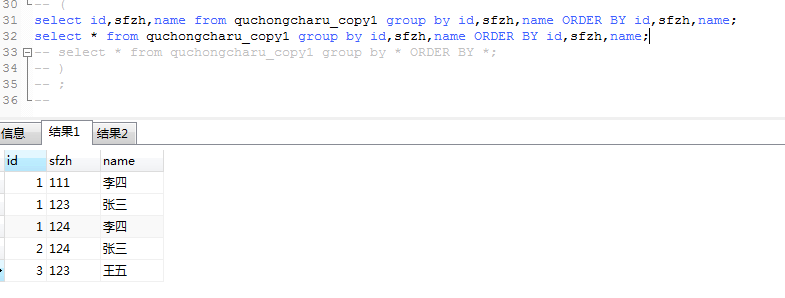
果然好用。order by是排序来的。
之前用group by order by 时,老是显示这一组的一个。(很烦,得另外处理)现在group by 和 order by 帮重复的 1 张三 123 去了重
select id,sfzh,name from quchongcharu_copy1 group by id,sfzh,name ORDER BY id,sfzh,name;
select * from quchongcharu_copy1 group by id,sfzh,name ORDER BY id,sfzh,name;
上述的问题解决语句
SELECT *
FROM quchongcharu
where
id IN
(SELECT min(id) FROM quchongcharu
GROUP BY sfzh,name
HAVING COUNT(*) > 1)
group by id,sfzh,name ORDER BY id,sfzh,name
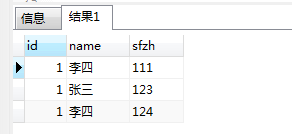
最终版去重语句 重复的都可以去的保留本身;还有保留本不重复的;
SELECT *
FROM quchongcharu
where
id IN
(SELECT min(id) FROM quchongcharu
GROUP BY sfzh,name
HAVING COUNT(*) > 1)
or
(sfzh , name) IN
(SELECT quchongcharu.sfzh,quchongcharu.name
FROM quchongcharu
GROUP BY quchongcharu.sfzh,quchongcharu.name
HAVING COUNT(*)=1)
group by id,sfzh,name ORDER BY id,sfzh,name
---最后一行 id,sfzh,name 替换 需要包含所有的列名 ,测试用例只有三列
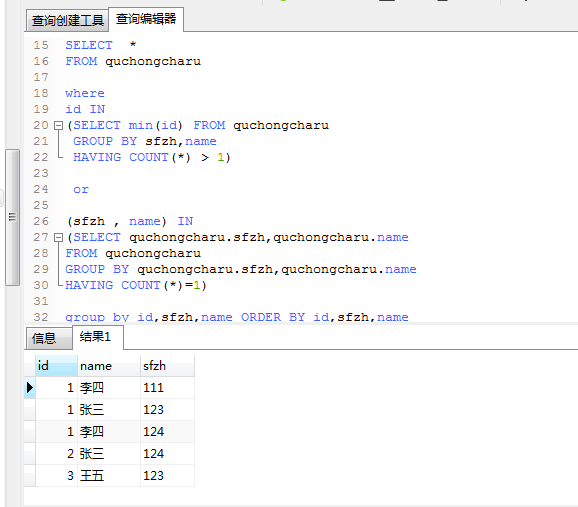
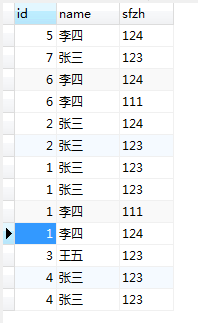
在看一眼源表:
当有时有用上面最终版去重语句但是查不出来,但是去了语句中的空格就好了。在调回有空格的,也能执行了。不知道为啥
[Err] ERROR: syntax error at or near ""
LINE 30: ;
SELECT *
FROM quchongcharu
where
id IN
(SELECT min(id) FROM quchongcharu
GROUP BY sfzh,name
HAVING COUNT(*) > 1)
or
(sfzh , name) IN
(SELECT sfzh,name
FROM quchongcharu
GROUP BY sfzh,name
HAVING COUNT(*)=1)
group by id,sfzh,name ORDER BY id,sfzh,name
--- 这边的 id,sfzh,name 是所有的列名, 如果不全报错,缺少排列的列名
---[Err] ERROR: column "•.pxxx" must appear in the GROUP BY clause or be used in an aggregate function
好麻烦呀!等着写个简单点的。
# 最新去重语句
发现去重主要作用是主要是 group by ,是一样的效果,上面having 在group by 是重复了。
简化如下 根据idcard 去重 去idcard唯一,取数据bh最下的那条数据 。 得到了 取最小的bh 所有的idcard,就不会重复了
这样
select * from gjk_rsj_rkxx_quchong
where
idcard in (
SELECT idcard FROM gjk_rsj_rkxx_quchong
GROUP BY idcard
HAVING COUNT(idcard) >= 1 )
and
bh in ( SELECT min(bh) FROM gjk_rsj_rkxx_quchong
GROUP BY idcard
HAVING COUNT(idcard) >= 1);
这样都行
select count(*) from gjk_rsj_rkxx_quchong
where
idcard
in (
SELECT idcard FROM gjk_rsj_rkxx_quchong
GROUP BY idcard
)
and
bh
in ( SELECT min(bh) FROM gjk_rsj_rkxx_quchong
GROUP BY idcard
);
然后再把上面查到的数据查到要更新的表就行了
INSERT into gjk_rsj_rkxx_quchong1 (idcard,name,sbbh,sex,nation,birthdate,education,face,marriage,zyjszw,gjzyzgdj,hkxz,grzt,hkszdmc,jzdmc,phone,txdz,yzbm,dzxx,jysydjh,byxx,bysj,sxzy,s_createtime,s_last_updatetime)
select ......