Part1 even-sized kernel 偶数大小卷积核
《Convolution with even-sized kernels and symmetric padding》
清华,NeurIPS,2019
一、 偶数大小卷积核定义
指方形卷积核,变长为偶数,例如2 * 2,4 * 4 ……
在以往,偶数卷积核一般也使用步长2来调整图片、特征图的大小(类似于池化);
二、直接用偶数大小卷积核的副作用——偏移问题
偏移问题(The shift problem):由于偶数卷积核在对特征图作卷积操作时,会出现左右不平衡,如下图:
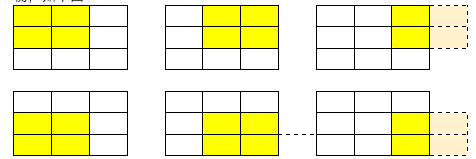
会发现正常无padding的卷积,还是四周1-pixel的padding,右边都会缺少一列。
而通过了多层的累积,会造成特征图里的正激活值(正是一些重要的特征)逐渐偏向左上角,如下图:(左边三个图是一只小鸟,经过多层偶数卷积操作后发现其重要特征偏移;右边是多个数据偏移的平均效果)。

It is clearly seen that the post-activation (ReLU) values in C2 are gradually shifting to the left-top corner of the spatial location. These compressed and distorted features are not suitable for the following classification, let alone pixel-level tasks based on it such as detection and semantic segmentation, where all the annotations will have offsets starting from the left-top corner of the image.
三、解决偏移——使用对称填充
对称填充(Symmetric padding)的步骤:
(1)把特征图(H*W*C)依通道分成四份,每一份为H*W*C/4;
(2)每一份只填充两边;
(3)再把特征图叠回原样;如下图右边:

四、偶数大小卷积核(以及)的好处
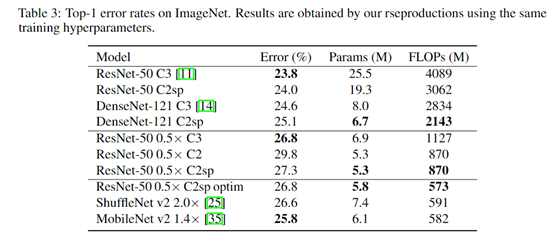
(1)参数量更少:以往工作告诉我们,通过堆叠若干个小卷积核的层,其感受野可以达到大卷积核的效果,并且参数量更少,同时也计算量更少,在图像分类上表现还行,如下面表格;
(2)缓解信息侵蚀(The information erosion hypothesis):信息侵蚀在下一个部分详细讨论(当前你可以把信息侵蚀想象成是随着神经网络层的加深,特征图边缘信息会慢慢消失)。而偶数卷积中的对称填充可以让四边的梯度分布得更均匀,从而减缓这种侵蚀,如上图左边,C2表示卷积核边长为2,sp表示对称填充。
(The smaller the ice, the faster the melting process happens. Symmetric padding equally distributes thermal gradients so as to slow down the exchange. Whereas asymmetric padding produces larger thermal gradients on a certain corner, thus accelerating it)
Part2 信息侵蚀/网络的盲点 Blind Spots
《Mind the Pad -- CNNs Can Develop Blind Spots》
Facebook AI,ICLR,2021
一、侵蚀与盲点的定义
(1)盲点
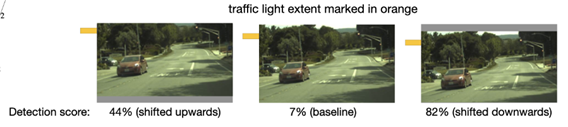
同样一个物体,在图片中的位置稍微变一点,网络的识别效果却大有不同。如下图(检测交通灯,目标大概在图的右上角,三张图的交通灯位置略有不同):
(2)信息侵蚀(information erosion)
也叫特征空间偏差(spatial bias),是由于卷积操作对输入信息的边缘处理往往少于输入信息的中间部分,然后特征图边缘的信息随着网络的加深,特征图的边缘信息会逐渐消失,如下图:
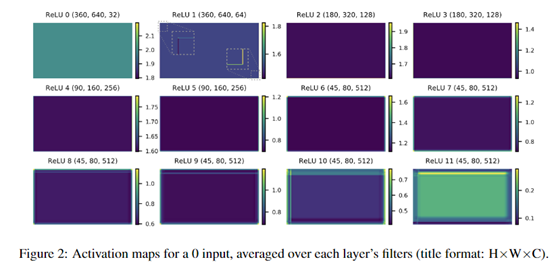
作者用一个大小为360*640,通道数为32的全0张量作为输入,可以看到随着网络的深入,其边缘的偏差越来越明显。这是因为每层卷积核所作的不当padding操作引起的。
信息侵蚀,会表现出特征伪影(feature artifact,也叫人为边界效应,即消失的那些边缘)、特征凹陷行为(foveation behavior,即中间突出/凹陷),从而导致网络出现盲点。
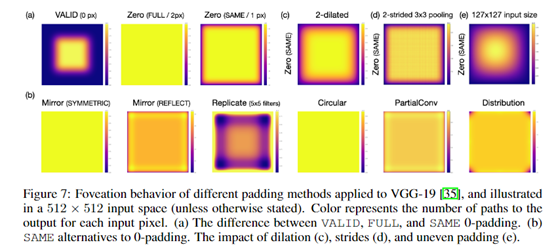
二、填充(padding)的种类及其影响
(1)valid padding:对特征图不作任何处理,只用原始的特征图;
(2)full padding:假设卷积核边为3,则在边缘填充2像素;若卷积核边为2,则填充1像素;但它会增加每一层输出的尺寸,计算量增大,不切实际;
(3)same padding:让输入和输出的大小一样,卷积核边为3,步长为1,则填充1像素;
(4)mirror padding(symmetric):特征图中的一行,左边边缘填充本行最右边第一个值,右边边缘填充最左边第一个值,上下同理;
(5)mirror padding(reflect):特征图中的一行,左边边缘填充本行最右边第二个值,右边边缘填充最左边第二个值,上下同理;
(6)replicate padding:直接复制边缘的值作为padding;
(7)Circular padding:
(8)Partial Convolution:
(9)Distribution padding:
不同padding方法在VGG-19上所呈现的凹陷现象:
三、为什么要填充
(1)保持特征图的尺寸,根据特征图大小的计算公式可知;
(2)减少边缘信息的误差,因为边缘不能成为卷积核的中心,边缘处理往往少于输入信息的中间部分;
四、填充的值
(1)0值填充,这是最常用的,因为0值填充对卷积核参数、对特征归一化的影响最小;
(2)两种mirror padding方法的填充值;
五、怎么解决侵蚀或盲点
(1)合理的输入大小
下采样层(会使特征图变小的层)的输入应满足:hi-1 = si · (hi - 1) + ki – 2 pi
其中h为输入的高,s为该层卷积核的步长,k为卷积核变长,p为padding一边的大小;
模型第一层的输入为:hi-1 = si d · (hd - 1) + ki – 2 pi 其中hd为最后一层模型图的高,d为下采样层的数量;
不同输入大小造成的影响:

(2)选择合适的padding方法
如上面所描述的各种padding方式,可以选择适合当前模型的。