1.Map端的Combiner.
通过单词计数WordCountApp.java的例子,如何在Map端设置Combiner...
只附录部分代码:
1 /** 2 * 以文本 3 * hello you 4 * hello me 5 * 为例子. 6 * map方法调用了两次,因为有两行 7 * k2 v2 键值对的数量有几个? 8 * 有4个.有四个单词. 9 * 10 * 会产生几个分组? 11 * 产生3个分组. 12 * 有3个不同的单词. 13 * 14 */ 15 public class WordCountApp { 16 public static void main(String[] args) throws Exception { 17 //程序在这里运行,要有驱动. 18 Configuration conf = new Configuration(); 19 Job job = Job.getInstance(conf,WordCountApp.class.getSimpleName()); 20 21 //我们运行此程序通过运行jar包来执行.一定要有这句话. 22 job.setJarByClass(WordCountApp.class); 23 FileInputFormat.setInputPaths(job,args[0]); 24 25 job.setMapperClass(WordCountMapper.class);//设置Map类 26 job.setMapOutputKeyClass(Text.class);//设置Map的key 27 job.setMapOutputValueClass(LongWritable.class);//设置Map的value 28 29 job.setCombinerClass(WordCountReducer.class);//数据在Map端先进行 一次合并. 30 /* 31 这个setCombinerClass设置参数只能是一个继承了Reduce类的类.直接用我们定义的WordCountReducer. 32 在单词技术的例子中,Map端产生了四个键值对,两个hello,you和me各一个. 33 这样合并之后Map端最终只产生三个键值对. 34 这样在Reduce端也只处理三个键值对,而不是没有合并之前的四个. 35 这样Map端最终产生的键值对少了,Map端向Reduce端传递键值对占用的带宽就小.提高网络通信的速度. 36 Reduce端接受键值对的数量变少,就减少了Reduce端处理键值对所需要的时间. 37 以上就是Combiner的好处(在Map端对数据进行一次合并). 38 Map端的合并和Reduce端的合并是不能相互取代的. 39 在Map端进行的合并是局部合并,当前Map任务在它之中的合并. 40 各个Map任务之间还是会 有相同的数据的.这些相同的数据要到Reduce端进行合并. 41 */ 42 43 job.setReducerClass(WordCountReducer.class);//设置Reduce的类 44 job.setOutputKeyClass(Text.class);//设置Reduce的key Reduce这个地方只有输出的参数可以设置. 方法名字也没有Reduce关键字区别于Map 45 job.setOutputValueClass(LongWritable.class);//设置Reduce的value. 46 47 FileOutputFormat.setOutputPath(job, new Path(args[1])); 48 job.waitForCompletion(true);//表示结束了才退出,不结束不退出 49 }
......................................................
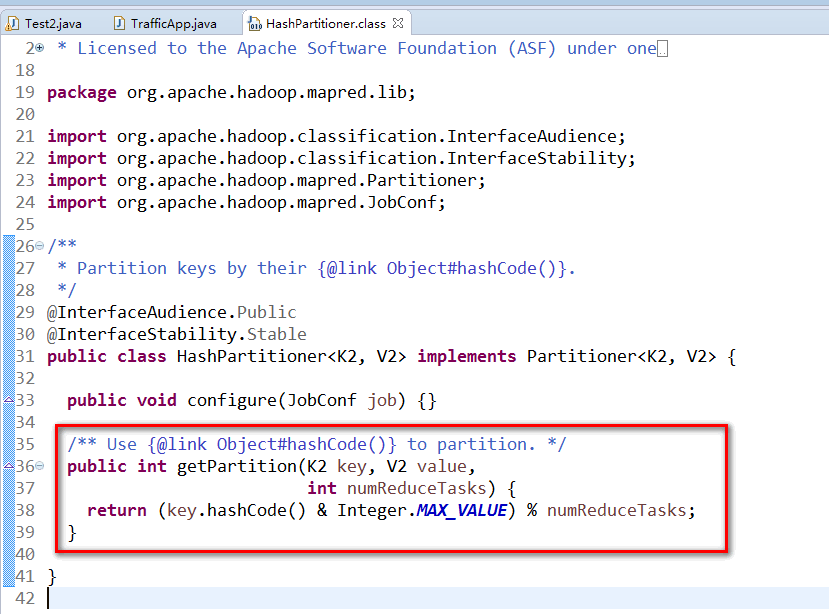
2.Reduce端的Partitioner.
以流量统计TrafficCountApp.java的例子示例Reduce端设置Partitioner.
只附录部分代码:
1 public class TrafficApp { 2 public static void main(String[] args) throws Exception { 3 Job job = Job.getInstance(new Configuration(), TrafficApp.class.getSimpleName()); 4 job.setJarByClass(TrafficApp.class); 5 6 FileInputFormat.setInputPaths(job, args[0]); 7 8 job.setMapperClass(TrafficMapper.class); 9 job.setMapOutputKeyClass(Text.class); 10 job.setMapOutputValueClass(TrafficWritable.class); 11 12 job.setNumReduceTasks(2);//设定Reduce的数量为2 13 job.setPartitionerClass(TrafficPartitioner.class);//设定一个Partitioner的类. 14 /* 15 *Partitioner是如何实现不同的Map输出分配到不同的Reduce中? 16 *在不适用指定的Partitioner时,有 一个默认的Partitioner. 17 *就是HashPartitioner. 18 *其只有一行代码,其意思就是过来的key,不管是什么,模numberReduceTasks之后 返回值就是reduce任务的编号. 19 *numberReduceTasks的默认值是1. 任何一个数模1(取余数)都是0. 20 *这个地方0就是取编号为0的Reduce.(Reduce从0开始编号.) 21 */ 22 23 job.setReducerClass(TrafficReducer.class); 24 job.setOutputKeyClass(Text.class); 25 job.setOutputValueClass(TrafficWritable.class); 26 27 FileOutputFormat.setOutputPath(job, new Path(args[1])); 28 job.waitForCompletion(true); 29 } 30 31 public static class TrafficPartitioner extends Partitioner<Text,TrafficWritable>{//k2,v2 32 33 @Override 34 public int getPartition(Text key, TrafficWritable value,int numPartitions) { 35 long phoneNumber = Long.parseLong(key.toString()); 36 return (int)(phoneNumber%numPartitions); 37 } 38 39 }
.................................................
//============附录MapReduce中Reduce使用默认的HashPartitioner进行分组的源代码==============