集成学习 Ensemble Learning
集成学习简介:
用通俗易懂的话来解释集成学习,我们可以理解为就是开会。会议目的就是综合参加会议所有人的提议,拟定出一个最佳的方案。同样我们也可以这么说,就是把各个模型进行二次结合,找到一个最符合实际情况的数据集,有些模型出现过拟合,欠拟合的情况用集成学习可以提高准确率。
其中集成学习的算法有:
1.1.个体学习器之间不存在强依赖关系,装袋(bagging)
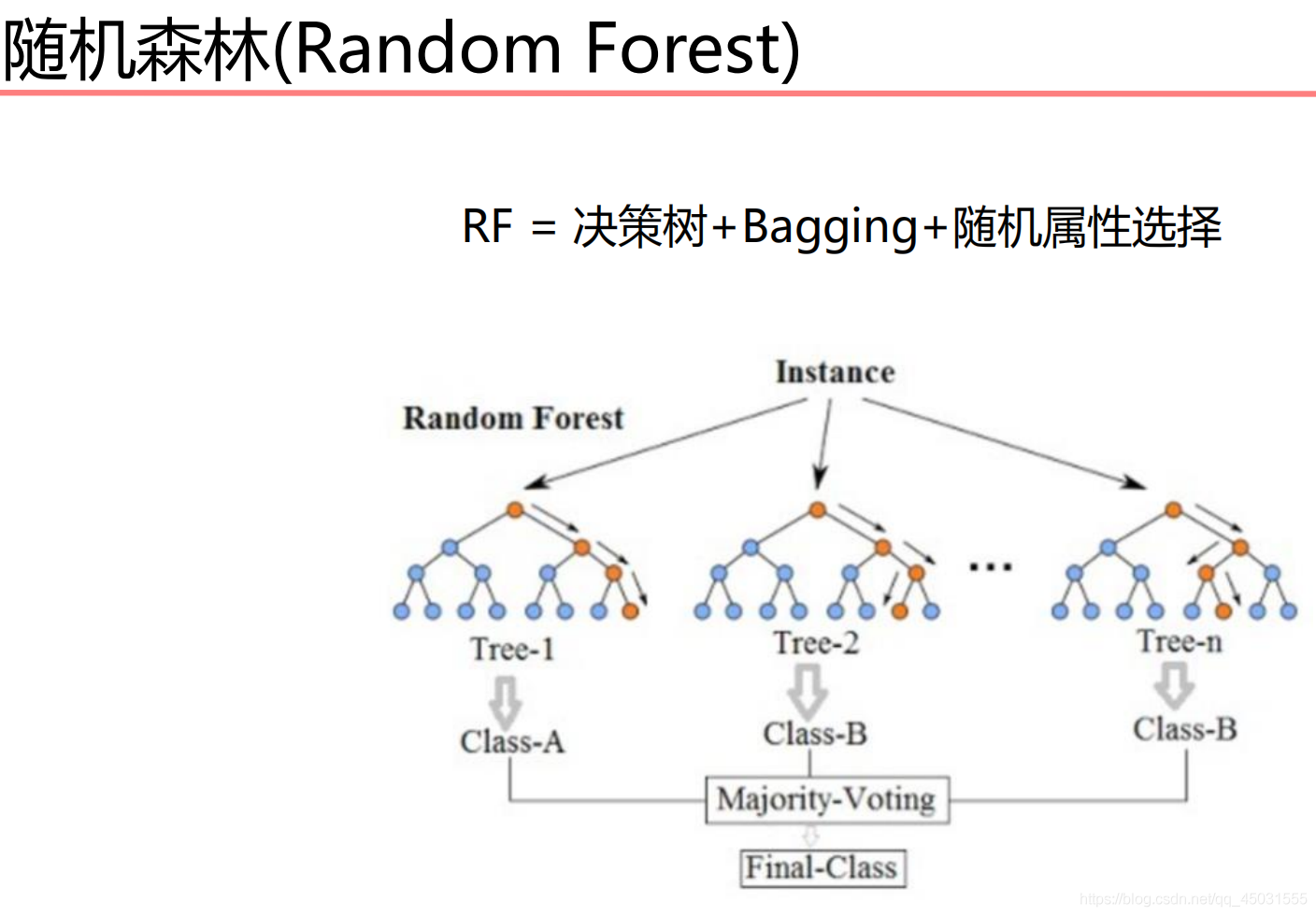
2.随机森林(Random Forest)
3.个体学习器之间存在强依赖关系,提升(boosting)
4.Stacking
bagging算法
大体思路:
有一个大的数据集,我们随机有放回的抽取一些样本组成N个小的样本,把这N个样本用适合的模型训练M轮,我们得到了N个训练好的模型,将得到的N个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果。
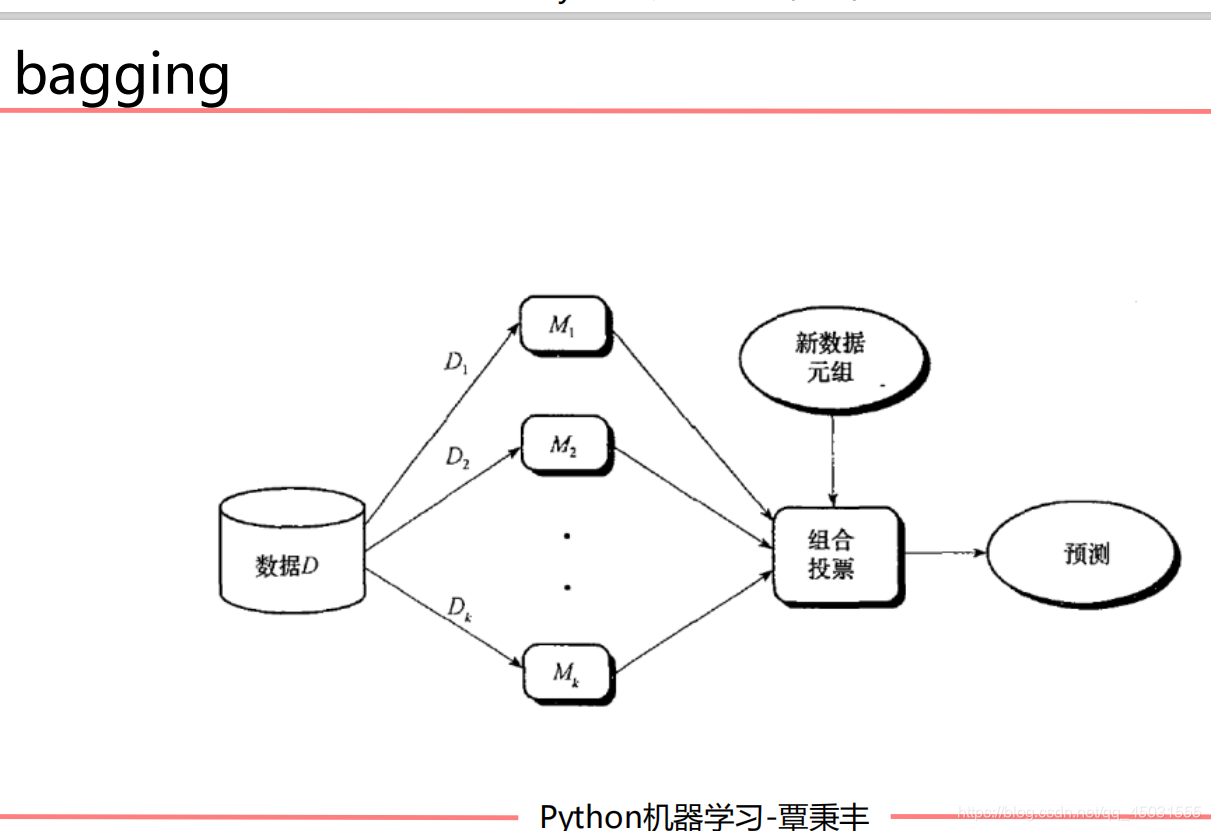
(ps:我的很多图片都来自AI--MOOC谭老师的PPT)
实例体验一下bagging
有些时候集成学习可能也会让准确率降低,这里展示一下这样的情况,有些时候开会的时候,每个人想法不一样也会使解决问题变得困难。毕竟整个bagging是要从N个里面投票的,使模型符合整个数据集,出现比单个模型准确率也是正常现象。
# 导入算法包以及数据集
from sklearn import neighbors
from sklearn import datasets
from sklearn.ensemble import BaggingClassifier
from sklearn import tree
from sklearn.model_selection import train_test_split
import numpy as np
import matplotlib.pyplot as plt
#选用 鸢尾花数据集,在sklearn库里就有的
iris = datasets.load_iris()
# 特征我们只用前两个特征
x_data = iris.data[:,:2]
#获取标签
y_data = iris.target
# 切分数据集和测试及
x_train,x_test,y_train,y_test = train_test_split(x_data, y_data)
#用sklearn中的KNN模型
knn = neighbors.KNeighborsClassifier()
knn.fit(x_train, y_train)# 准确率
knn.score(x_test, y_test)
运行结果的到准确率:

使用bagging集成学习
#用bagging集成学习,在这里分为N个KNN模型,在N模型中结合
bagging_knn = BaggingClassifier(knn, n_estimators=300)
# 输入数据建立模型
bagging_knn.fit(x_train, y_train)
bagging_knn.score(x_test, y_test)
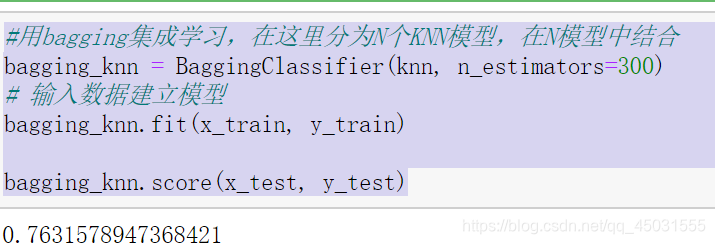
我们可以感觉出来,精确度下降了,其实我自己运行了好几次才出现这样的情况,因为每次的随机取样是不一样的,会影响计算结果。下面用一张图片形象的展示一个结合的意思
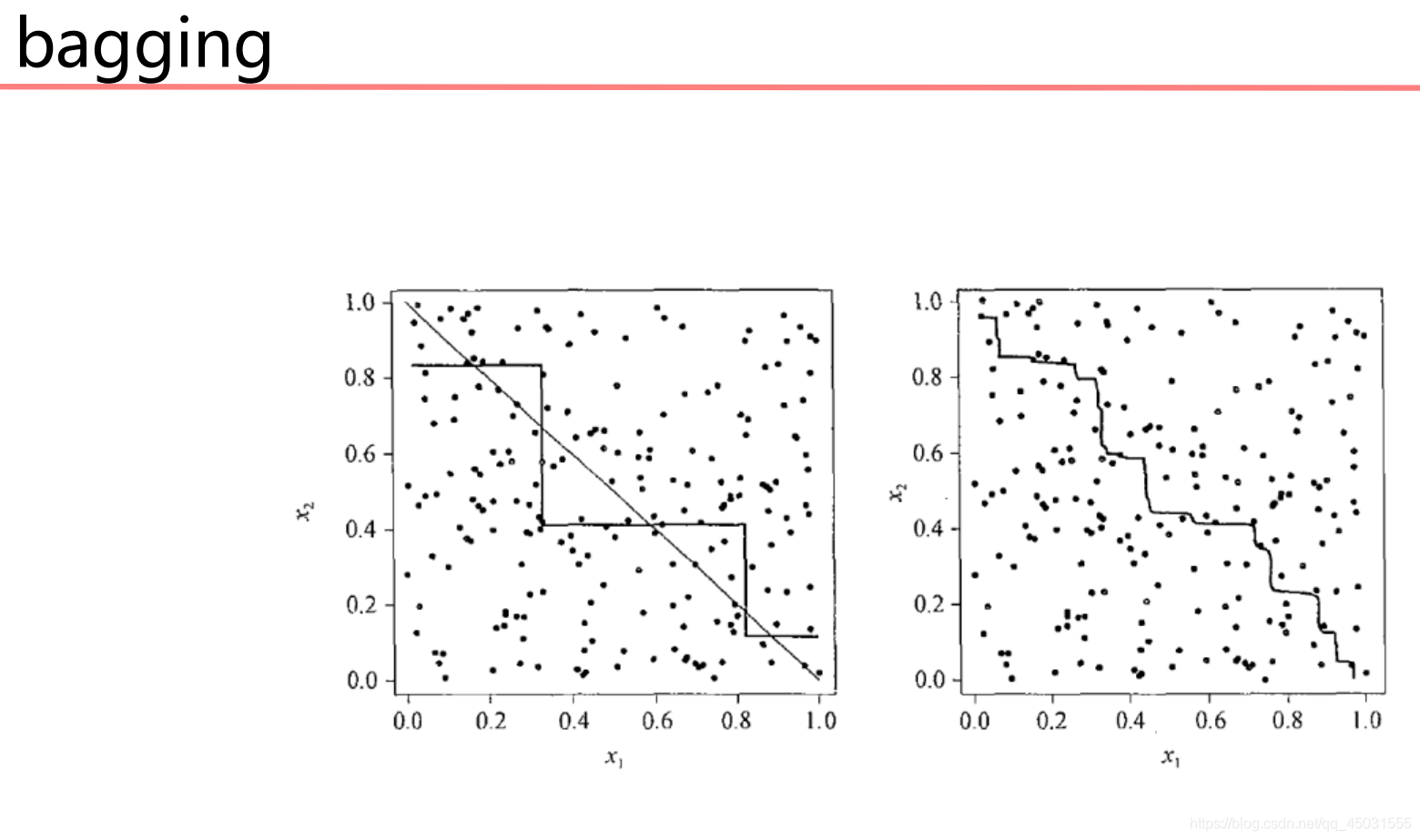
随机森林算法:
大致思路:

代码部分:
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import numpy as np
import matplotlib.pyplot as plt
# 载入数据
data = np.genfromtxt("LR-testSet2.txt", delimiter=",")
x_data = data[:,:-1]
y_data = data[:,-1]
x_train,x_test,y_train,y_test = train_test_split(x_data, y_data, test_size = 0.5)
dtree = tree.DecisionTreeClassifier()
dtree.fit(x_train, y_train)
print('单一决策树准确率:',dtree.score(x_test, y_test))
RF = RandomForestClassifier(n_estimators=50)
RF.fit(x_train, y_train)
print('使用随机数森林后的准确率:',RF.score(x_test, y_test))
运行截图:

随机森林确实对于决策树准确率的提升效果明显。
boosting
算法大致思路:
AdaBoost是英文“Adaptive Boosting”(自适应增强)
的缩写,它的自适应在于:前一个基本分类器被错误分类的
样本的权值会增大,而正确分类的样本的权值会减小,并再
次用来训练下一个基本分类器。同时,在每一轮迭代中,加
入一个新的弱分类器,直到达到某个预定的足够小的错误率
或达到预先指定的最大迭代次数才确定最终的强分类器。换句话说就是用各个弱分类器的正确率高的部分组装成一个强分类器。
实例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import tree
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import make_gaussian_quantiles
from sklearn.metrics import classification_report# 生成2维正态分布,生成的数据按分位数分为两类,500个样本,2个样本特征
x1, y1 = make_gaussian_quantiles(n_samples=500, n_features=2,n_classes=2)
# 生成2维正态分布,生成的数据按分位数分为两类,400个样本,2个样本特征均值都为3
x2, y2 = make_gaussian_quantiles(mean=(3, 3), n_samples=500, n_features=2, n_classes=2)
# 将两组数据合成一组数据
x_data = np.concatenate((x1, x2))
y_data = np.concatenate((y1, - y2 + 1))
# 决策树模型
model = tree.DecisionTreeClassifier(max_depth=3)
# 输入数据建立模型
model.fit(x_data, y_data)
print('单个决策树分类准确性:',model.score(x_data,y_data))
# AdaBoost模型
model = AdaBoostClassifier(DecisionTreeClassifier(max_depth=3),n_estimators=10)
# 训练模型
model.fit(x_data, y_data)
# 模型准确率
print('boosting分类后准确率:',model.score(x_data,y_data))

由几个弱分类器组合而成的强分类器确实很强
stacking算法:
算法大致思路:
使用多个不同的分类器对训练集进预测,把预测
得到的结果作为一个次级分类器的输入。次级分
类器的输出是整个模型的预测结果。意思就是说 我们可以用决策树,KNN,神经网络,逻辑回归等分类模型集合成一个强分类器。
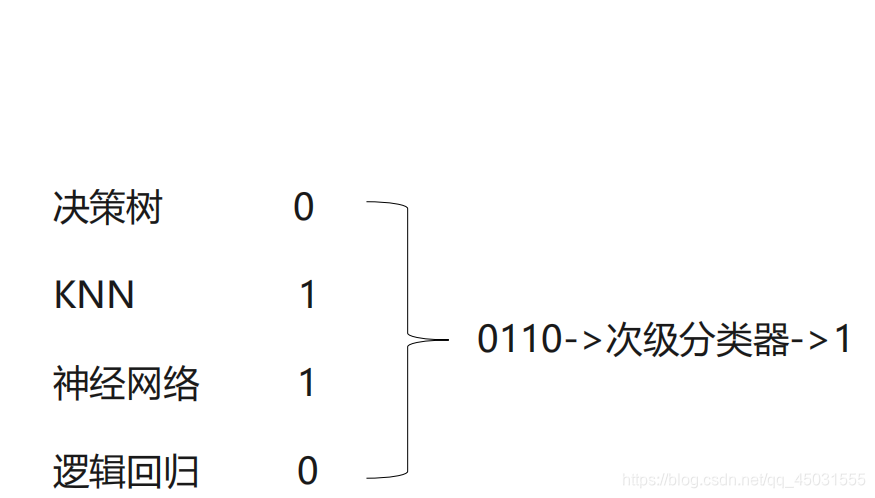
举例:
from sklearn import datasets
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from mlxtend.classifier import StackingClassifier # pip install mlxtend
import numpy as np
# 载入数据集
iris = datasets.load_iris()
# 只要第1,2列的特征
x_data, y_data = iris.data[:, 1:3], iris.target
# 定义三个不同的分类器
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = DecisionTreeClassifier()
clf3 = LogisticRegression()
# 定义一个次级分类器
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2, clf3],
meta_classifier=lr)
for clf,label in zip([clf1, clf2, clf3, sclf],
['KNN','Decision Tree','LogisticRegression','StackingClassifier']):
scores = model_selection.cross_val_score(clf, x_data, y_data, cv=3, scoring='accuracy')
print("Accuracy: %0.2f [%s]" % (scores.mean(), label))
集KNN,决策树,逻辑回归于一体提高了模型的准确性。


乳腺癌预测
数据集展示
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
#用pandas处理数据
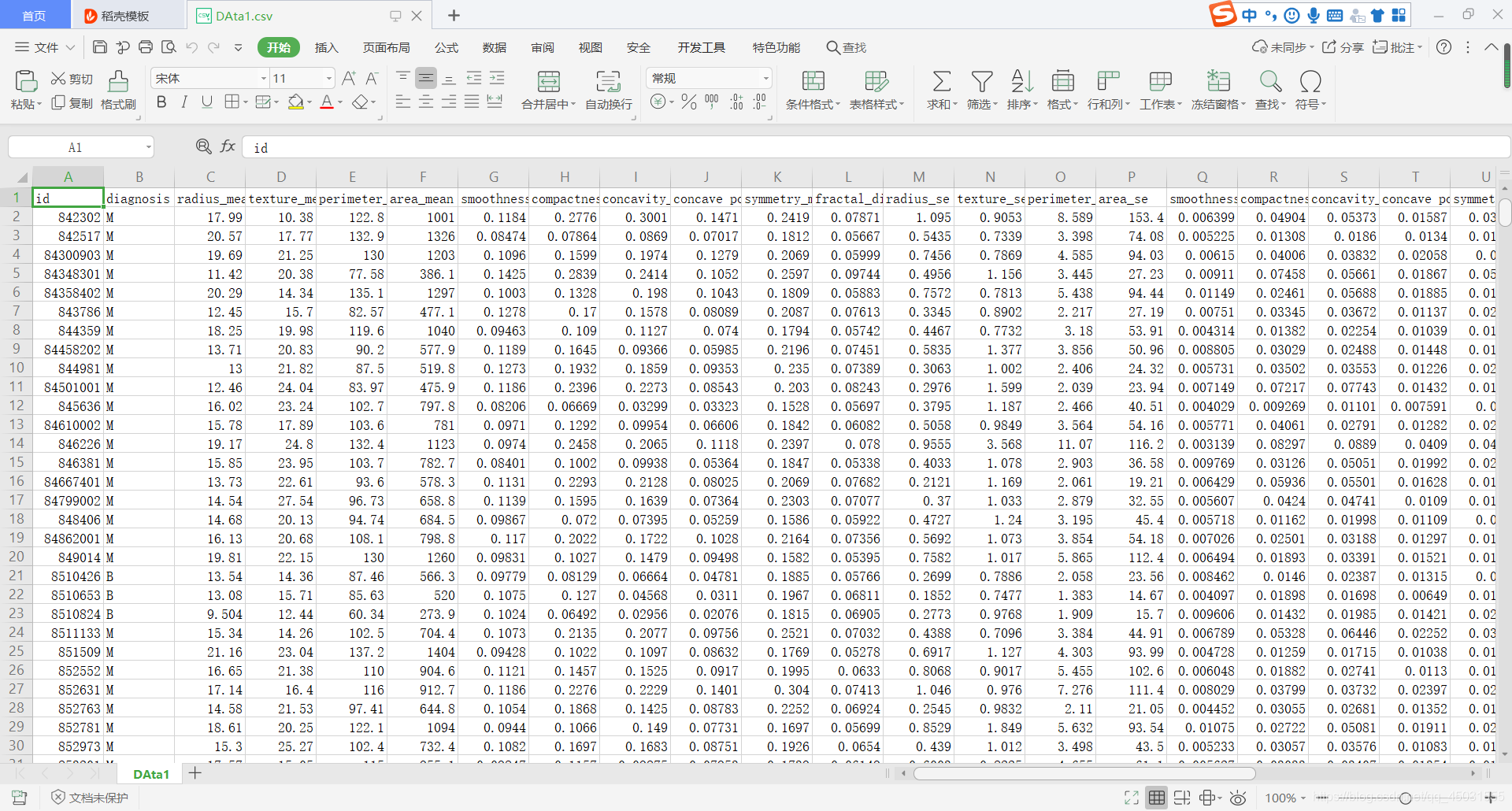
df = pd.read_csv("E:\python-ml\DAta1.csv")
#打印出DataFrame中的前5行
df.head()

df.shape()
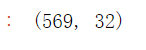
我们可以知道数据集有 569行,32列,其中有一个ID列(排序对于预测没有关系,我们不需要)
df = df.drop('id', axis=1)
df.diagnosis.unique()
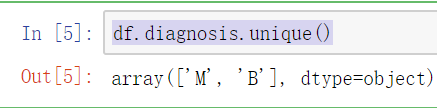
在diagnosis这个特征里一共只有两个情况M 和 B ,我们得用数据来表示这样的特征,于是用 1表示M,用0表示B
df['diagnosis'] = df['diagnosis'].map({'M':1,'B':0})
map函数是一个映射关系,这关系对于 diagnos这一列数据,在这整个列的数据都由字母变成数字。
# 获取训练数据和标签
#把标签去掉的数据集作为 特征集合
x_data = df.drop(['diagnosis'], axis=1)
#用这一列作为标签集合
y_data = df['diagnosis']
from sklearn.model_selection import train_test_split
# 切分数据集,stratify=y表示切分后训练集和测试集中的数据类型的比例跟切分前y中的比例一致
# 比如切分前y中0和1的比例为1:2,切分后y_train和y_test中0和1的比例也都是1:2
x_train,x_test,y_train,y_test = train_test_split(x_data, y_data, test_size=0.3, stratify=y_data)
from sklearn.metrics import accuracy_score
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, BaggingClassifier
#创建一个list,每个元素都是一个模型类
classifiers = [
KNeighborsClassifier(3),
LogisticRegression(),
MLPClassifier(hidden_layer_sizes=(20,50),max_iter=10000),
DecisionTreeClassifier(),
RandomForestClassifier(max_depth=9,min_samples_split=3),
AdaBoostClassifier(),
BaggingClassifier(),
]
log = []
for clf in classifiers:
clf.fit(x_train, y_train)#可以理解为实例化对象,训练模型
name = clf.__class__.__name__#把对应的name保存
print("="*30)#连续打印出30个*
print(name)
print('****Results****')
test_predictions = clf.predict(x_test)#用测试集数据来测试模型准确度如何
acc = accuracy_score(y_test, test_predictions)
print("Accuracy: {:.4%}".format(acc))
log.append([name, acc*100])
print("="*30)
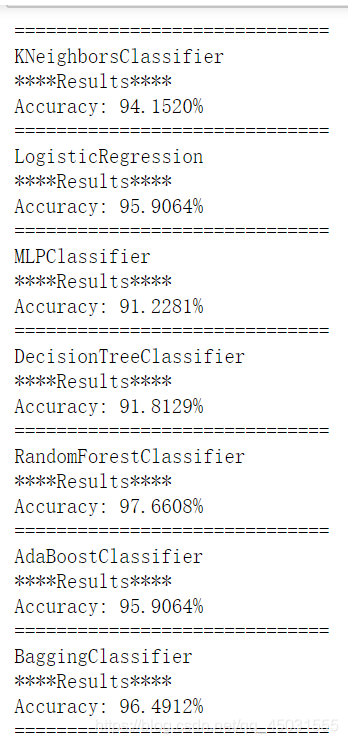
分析数据可以发现,用集成模型的准确度是要高于单一分类器的,人多力量大。