参考:
http://www.cnblogs.com/LBSer/p/4083131.html
https://blog.csdn.net/scorpio3k/article/details/53103239
http://jinnianshilongnian.iteye.com/blog/2305117
http://iamzhongyong.iteye.com/blog/1742829
https://blog.csdn.net/qianshangding0708/article/details/104026669
https://blog.csdn.net/qianshangding0708/article/details/104026669
一、问题描述
某天A君突然发现自己的接口请求量突然涨到之前的10倍,没多久该接口几乎不可使用,并引发连锁反应导致整个系统崩溃。如何应对这种情况呢?生活给了我们答案:比如老式电闸都安装了保险丝,一旦有人使用超大功率的设备,保险丝就会烧断以保护各个电器不被强电流给烧坏。同理我们的接口也需要安装上“保险丝”,以防止非预期的请求对系统压力过大而引起的系统瘫痪,当流量过大时,可以采取拒绝或者引流等机制。
二、常用的限流算法
常用的限流算法有两种:漏桶算法和令牌桶算法。
漏桶算法思路很简单,水(请求)先进入到漏桶里,漏桶以一定的速度出水,当水流入速度过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
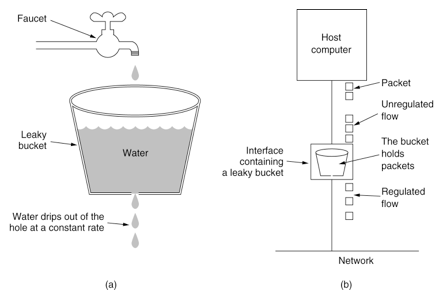
图1 漏桶算法示意图
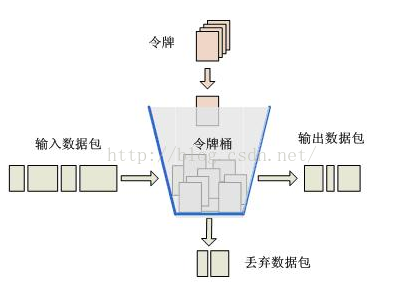
对于很多应用场景来说,除了要求能够限制数据的平均传输速率外,还要求允许某种程度的突发传输。这时候漏桶算法可能就不合适了,令牌桶算法更为适合。如图2所示,令牌桶算法的原理是系统会以一个恒定的速度往桶里放入令牌,而如果请求需要被处理,则需要先从桶里获取一个令牌,当桶里没有令牌可取时,则拒绝服务。
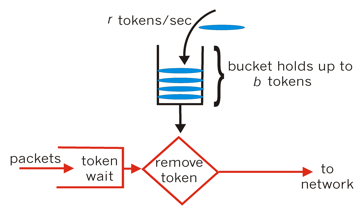
图2 令牌桶算法示意图
三、限流工具类RateLimiter
Google开源工具包Guava提供了限流工具类RateLimiter,该类基于令牌桶算法来完成限流,非常易于使用。RateLimiter类的接口描述请参考:RateLimiter接口描述,具体使用请参考:RateLimiter使用实践。
下面是主要源码:

public double acquire() {
return acquire(1);
}
public double acquire(int permits) {
checkPermits(permits); //检查参数是否合法(是否大于0)
long microsToWait;
synchronized (mutex) { //应对并发情况需要同步
microsToWait = reserveNextTicket(permits, readSafeMicros()); //获得需要等待的时间
}
ticker.sleepMicrosUninterruptibly(microsToWait); //等待,当未达到限制时,microsToWait为0
return 1.0 * microsToWait / TimeUnit.SECONDS.toMicros(1L);
}
private long reserveNextTicket(double requiredPermits, long nowMicros) {
resync(nowMicros); //补充令牌
long microsToNextFreeTicket = nextFreeTicketMicros - nowMicros;
double storedPermitsToSpend = Math.min(requiredPermits, this.storedPermits); //获取这次请求消耗的令牌数目
double freshPermits = requiredPermits - storedPermitsToSpend;
long waitMicros = storedPermitsToWaitTime(this.storedPermits, storedPermitsToSpend)
+ (long) (freshPermits * stableIntervalMicros);
this.nextFreeTicketMicros = nextFreeTicketMicros + waitMicros;
this.storedPermits -= storedPermitsToSpend; // 减去消耗的令牌
return microsToNextFreeTicket;
}
private void resync(long nowMicros) {
// if nextFreeTicket is in the past, resync to now
if (nowMicros > nextFreeTicketMicros) {
storedPermits = Math.min(maxPermits,
storedPermits + (nowMicros - nextFreeTicketMicros) / stableIntervalMicros);
nextFreeTicketMicros = nowMicros;
}
}
适用场景
并不能说明令牌桶一定比漏洞好,她们使用场景不一样。令牌桶可以用来保护自己,主要用来对调用者频率进行限流,为的是让自己不被打垮。所以如果自己本身有处理能力的时候,如果流量突发(实际消费能力强于配置的流量限制),那么实际处理速率可以超过配置的限制。而漏桶算法,这是用来保护他人,也就是保护他所调用的系统。主要场景是,当调用的第三方系统本身没有保护机制,或者有流量限制的时候,我们的调用速度不能超过他的限制,由于我们不能更改第三方系统,所以只有在主调方控制。这个时候,即使流量突发,也必须舍弃。因为消费能力是第三方决定的。
总结起来:如果要让自己的系统不被打垮,用令牌桶。如果保证别人的系统不被打垮,用漏桶算法
服务治理---限流(令牌桶算法)
1、最近在写一个分布式服务的框架,对于分布式服务的框架来说,除了远程调用,还要进行服务的治理
当进行促销的时候,所有的资源都用来完成重要的业务,就比如双11的时候,主要的业务就是让用户查询商品,以及购买支付,
此时,金币查询、积分查询等业务就是次要的,因此要对这些服务进行服务的降级,典型的服务降级算法是采用令牌桶算法,
因此在写框架的时候去研究了一下令牌桶算法
2、在实施QOS策略时,可以将用户的数据限制在特定的带宽,当用户的流量超过额定带宽时,超过的带宽将采取其它方式来处理。
要衡量流量是否超过额定的带宽,网络设备并不是采用单纯的数字加减法来决定的,也就是说,比如带宽为100K,而用户发来
的流量为110K,网络设备并不是靠110K减去100K等于10K,就认为用户超过流量10K。网络设备衡量流量是否超过额定带宽,
需要使用令牌桶算法来计算。下面详细介绍令牌桶算法机制:
当网络设备衡量流量是否超过额定带宽时,需要查看令牌桶,而令牌桶中会放置一定数量的令牌,一个令牌允许接口发送
或接收1bit数据(有时是1 Byte数据),当接口通过1bit数据后,同时也要从桶中移除一个令牌。当桶里没有令牌的时候,任何流
量都被视为超过额定带宽,只有当桶中有令牌时,数据才可以通过接口。令牌桶中的令牌不仅仅可以被移除,同样也可以往里添加,
所以为了保证接口随时有数据通过,就必须不停地往桶里加令牌,由此可见,往桶里加令牌的速度,就决定了数据通过接口的速度。
因此,我们通过控制往令牌桶里加令牌的速度从而控制用户流量的带宽。而设置的这个用户传输数据的速率被称为承诺信息速率(CIR),
通常以秒为单位。比如我们设置用户的带宽为1000 bit每秒,只要保证每秒钟往桶里添加1000个令牌即可。
3、举例:
将CIR设置为8000 bit/s,那么就必须每秒将8000个令牌放入桶中,当接口有数据通过时,就从桶中移除相应的令牌,每通过1 bit,
就从桶中移除1个令牌。当桶里没有令牌的时候,任何流量都被视为超出额定带宽,而超出的流量就要采取额外动作。每秒钟往桶里加的令牌
就决定了用户流量的速率,这个速率就是CIR,但是每秒钟需要往桶里加的令牌总数,并不是一次性加完的,一次性加进的令牌数量被称为Burst size(Bc),
如果Bc只是CIR的一半,那么很明显每秒钟就需要往桶里加两次令牌,每次加的数量总是Bc的数量。还有就是加令牌的时间,Time interval(Tc),
Tc表示多久该往桶里加一次令牌,而这个时间并不能手工设置,因为这个时间可以靠CIR和Bc的关系计算得到, Bc/ CIR= Tc。
4、令牌桶算法图例
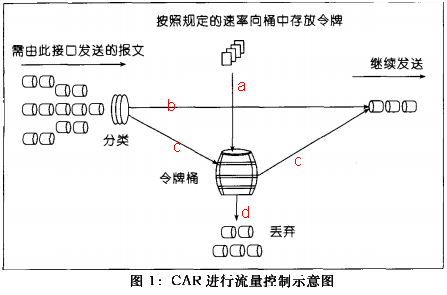
a. 按特定的速率向令牌桶投放令牌
b. 根据预设的匹配规则先对报文进行分类,不符合匹配规则的报文不需要经过令牌桶的处理,直接发送;
c. 符合匹配规则的报文,则需要令牌桶进行处理。当桶中有足够的令牌则报文可以被继续发送下去,同时令牌桶中的令牌 量按报文的长度做相应的减少;
d. 当令牌桶中的令牌不足时,报文将不能被发送,只有等到桶中生成了新的令牌,报文才可以发送。这就可以限制报文的流量只能是小于等于令牌生成的速度,达到限制流量的目的。
5、Java参考代码:
package com.netease.datastream.util.flowcontrol;
import java.io.BufferedWriter;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStreamWriter;
import java.util.Random;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;
/**
* <pre>
* Created by inter12 on 15-3-18.
* </pre>
*/
public class TokenBucket {
// 默认桶大小个数 即最大瞬间流量是64M
private static final int DEFAULT_BUCKET_SIZE = 1024 * 1024 * 64;
// 一个桶的单位是1字节
private int everyTokenSize = 1;
// 瞬间最大流量
private int maxFlowRate;
// 平均流量
private int avgFlowRate;
// 队列来缓存桶数量:最大的流量峰值就是 = everyTokenSize*DEFAULT_BUCKET_SIZE 64M = 1 * 1024 *
// 1024 * 64
private ArrayBlockingQueue<Byte> tokenQueue = new ArrayBlockingQueue<Byte>(
DEFAULT_BUCKET_SIZE);
private ScheduledExecutorService scheduledExecutorService = Executors
.newSingleThreadScheduledExecutor();
private volatile boolean isStart = false;
private ReentrantLock lock = new ReentrantLock(true);
private static final byte A_CHAR = 'a';
public TokenBucket() {
}
public TokenBucket(int maxFlowRate, int avgFlowRate) {
this.maxFlowRate = maxFlowRate;
this.avgFlowRate = avgFlowRate;
}
public TokenBucket(int everyTokenSize, int maxFlowRate, int avgFlowRate) {
this.everyTokenSize = everyTokenSize;
this.maxFlowRate = maxFlowRate;
this.avgFlowRate = avgFlowRate;
}
public void addTokens(Integer tokenNum) {
// 若是桶已经满了,就不再家如新的令牌
for (int i = 0; i < tokenNum; i++) {
tokenQueue.offer(Byte.valueOf(A_CHAR));
}
}
public TokenBucket build() {
start();
return this;
}
/**
* 获取足够的令牌个数
*
* @return
*/
public boolean getTokens(byte[] dataSize) {
// Preconditions.checkNotNull(dataSize);
// Preconditions.checkArgument(isStart,
// "please invoke start method first !");
int needTokenNum = dataSize.length / everyTokenSize + 1;// 传输内容大小对应的桶个数
final ReentrantLock lock = this.lock;
lock.lock();
try {
boolean result = needTokenNum <= tokenQueue.size(); // 是否存在足够的桶数量
if (!result) {
return false;
}
int tokenCount = 0;
for (int i = 0; i < needTokenNum; i++) {
Byte poll = tokenQueue.poll();
if (poll != null) {
tokenCount++;
}
}
return tokenCount == needTokenNum;
} finally {
lock.unlock();
}
}
public void start() {
// 初始化桶队列大小
if (maxFlowRate != 0) {
tokenQueue = new ArrayBlockingQueue<Byte>(maxFlowRate);
}
// 初始化令牌生产者
TokenProducer tokenProducer = new TokenProducer(avgFlowRate, this);
scheduledExecutorService.scheduleAtFixedRate(tokenProducer, 0, 1,
TimeUnit.SECONDS);
isStart = true;
}
public void stop() {
isStart = false;
scheduledExecutorService.shutdown();
}
public boolean isStarted() {
return isStart;
}
class TokenProducer implements Runnable {
private int avgFlowRate;
private TokenBucket tokenBucket;
public TokenProducer(int avgFlowRate, TokenBucket tokenBucket) {
this.avgFlowRate = avgFlowRate;
this.tokenBucket = tokenBucket;
}
@Override
public void run() {
tokenBucket.addTokens(avgFlowRate);
}
}
public static TokenBucket newBuilder() {
return new TokenBucket();
}
public TokenBucket everyTokenSize(int everyTokenSize) {
this.everyTokenSize = everyTokenSize;
return this;
}
public TokenBucket maxFlowRate(int maxFlowRate) {
this.maxFlowRate = maxFlowRate;
return this;
}
public TokenBucket avgFlowRate(int avgFlowRate) {
this.avgFlowRate = avgFlowRate;
return this;
}
private String stringCopy(String data, int copyNum) {
StringBuilder sbuilder = new StringBuilder(data.length() * copyNum);
for (int i = 0; i < copyNum; i++) {
sbuilder.append(data);
}
return sbuilder.toString();
}
public static void main(String[] args) throws IOException,
InterruptedException {
tokenTest();
}
private static void arrayTest() {
ArrayBlockingQueue<Integer> tokenQueue = new ArrayBlockingQueue<Integer>(
10);
tokenQueue.offer(1);
tokenQueue.offer(1);
tokenQueue.offer(1);
System.out.println(tokenQueue.size());
System.out.println(tokenQueue.remainingCapacity());
}
private static void tokenTest() throws InterruptedException, IOException {
TokenBucket tokenBucket = TokenBucket.newBuilder().avgFlowRate(512)
.maxFlowRate(1024).build();
BufferedWriter bufferedWriter = new BufferedWriter(
new OutputStreamWriter(new FileOutputStream("D:/ds_test")));
String data = "xxxx";// 四个字节
for (int i = 1; i <= 1000; i++) {
Random random = new Random();
int i1 = random.nextInt(100);
boolean tokens = tokenBucket.getTokens(tokenBucket.stringCopy(data,
i1).getBytes());
TimeUnit.MILLISECONDS.sleep(100);
if (tokens) {
bufferedWriter.write("token pass --- index:" + i1);
System.out.println("token pass --- index:" + i1);
} else {
bufferedWriter.write("token rejuect --- index" + i1);
System.out.println("token rejuect --- index" + i1);
}
bufferedWriter.newLine();
bufferedWriter.flush();
}
bufferedWriter.close();
}
}
高并发系统限流中的漏桶算法和令牌桶算法,通过流量整形和速率限制提升稳定性
在大数据量高并发访问时,经常会出现服务或接口面对暴涨的请求而不可用的情况,甚至引发连锁反映导致整个系统崩溃。此时你需要使用的技术手段之一就是限流,当请求达到一定的并发数或速率,就进行等待、排队、降级、拒绝服务等。在限流时,常见的两种算法是漏桶和令牌桶算法算法,本文即对相关内容进行重点介绍。
一、漏桶和令牌桶算法的概念
漏桶算法(Leaky Bucket):主要目的是控制数据注入到网络的速率,平滑网络上的突发流量。漏桶算法提供了一种机制,通过它,突发流量可以被整形以便为网络提供一个稳定的流量。漏桶算法的示意图如下:
请求先进入到漏桶里,漏桶以一定的速度出水,当水请求过大会直接溢出,可以看出漏桶算法能强行限制数据的传输速率。
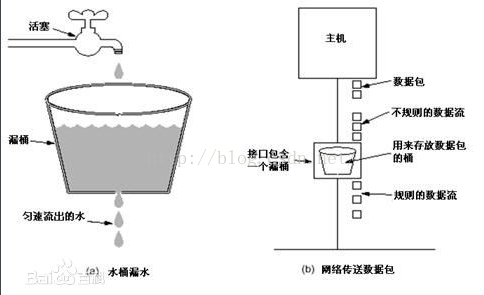
令牌桶算法(Token Bucket):是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。令牌桶算法示意图如下所示:
大小固定的令牌桶可自行以恒定的速率源源不断地产生令牌。如果令牌不被消耗,或者被消耗的速度小于产生的速度,令牌就会不断地增多,直到把桶填满。后面再产生的令牌就会从桶中溢出。最后桶中可以保存的最大令牌数永远不会超过桶的大小。
二、两种算法的区别
两者主要区别在于“漏桶算法”能够强行限制数据的传输速率,而“令牌桶算法”在能够限制数据的平均传输速率外,还允许某种程度的突发传输。在“令牌桶算法”中,只要令牌桶中存在令牌,那么就允许突发地传输数据直到达到用户配置的门限,所以它适合于具有突发特性的流量。
三、使用Guava的RateLimiter进行限流控制
Guava是google提供的java扩展类库,其中的限流工具类RateLimiter采用的就是令牌桶算法。RateLimiter 从概念上来讲,速率限制器会在可配置的速率下分配许可证,如果必要的话,每个acquire() 会阻塞当前线程直到许可证可用后获取该许可证,一旦获取到许可证,不需要再释放许可证。通俗的讲RateLimiter会按照一定的频率往桶里扔令牌,线程拿到令牌才能执行,比如你希望自己的应用程序QPS不要超过1000,那么RateLimiter设置1000的速率后,就会每秒往桶里扔1000个令牌。例如我们需要处理一个任务列表,但我们不希望每秒的任务提交超过两个,此时可以采用如下方式:
有一点很重要,那就是请求的许可数从来不会影响到请求本身的限制(调用acquire(1) 和调用acquire(1000) 将得到相同的限制效果,如果存在这样的调用的话),但会影响下一次请求的限制,也就是说,如果一个高开销的任务抵达一个空闲的RateLimiter,它会被马上许可,但是下一个请求会经历额外的限制,从而来偿付高开销任务。注意:RateLimiter 并不提供公平性的保证。

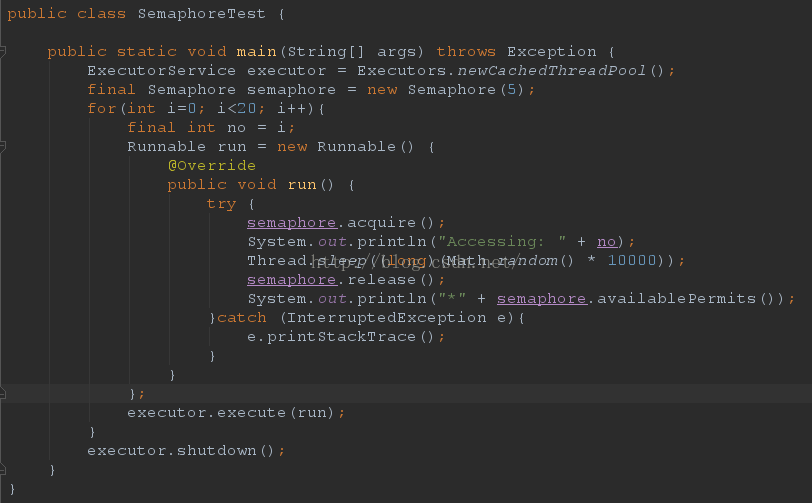
四、使用Semphore进行并发流控
Java 并发库的Semaphore 可以很轻松完成信号量控制,Semaphore可以控制某个资源可被同时访问的个数,通过 acquire() 获取一个许可,如果没有就等待,而 release() 释放一个许可。单个信号量的Semaphore对象可以实现互斥锁的功能,并且可以是由一个线程获得了“锁”,再由另一个线程释放“锁”,这可应用于死锁恢复的一些场合。下面的Demo中申明了一个只有5个许可的Semaphore,而有20个线程要访问这个资源,通过acquire()和release()获取和释放访问许可:
最后:进行限流控制还可以有很多种方法,针对不同的场景各有优劣,例如通过AtomicLong计数器控制、使用MQ消息队列进行流量削峰【通过配置消费者线程池】等等。
聊聊高并发系统之限流特技
在开发高并发系统时有三把利器用来保护系统:缓存、降级和限流。缓存的目的是提升系统访问速度和增大系统能处理的容量,可谓是抗高并发流量的银弹;而降级是当服务出问题或者影响到核心流程的性能则需要暂时屏蔽掉,待高峰或者问题解决后再打开;而有些场景并不能用缓存和降级来解决,比如稀缺资源(秒杀、抢购)、写服务(如评论、下单)、频繁的复杂查询(评论的最后几页),因此需有一种手段来限制这些场景的并发/请求量,即限流。
限流的目的是通过对并发访问/请求进行限速或者一个时间窗口内的的请求进行限速来保护系统,一旦达到限制速率则可以拒绝服务(定向到错误页或告知资源没有了)、排队或等待(比如秒杀、评论、下单)、降级(返回兜底数据或默认数据,如商品详情页库存默认有货)。
一般开发高并发系统常见的限流有:限制总并发数(比如数据库连接池、线程池)、限制瞬时并发数(如nginx的limit_conn模块,用来限制瞬时并发连接数)、限制时间窗口内的平均速率(如Guava的RateLimiter、nginx的limit_req模块,限制每秒的平均速率);其他还有如限制远程接口调用速率、限制MQ的消费速率。另外还可以根据网络连接数、网络流量、CPU或内存负载等来限流。
先有缓存这个银弹,后有限流来应对618、双十一高并发流量,在处理高并发问题上可以说是如虎添翼,不用担心瞬间流量导致系统挂掉或雪崩,最终做到有损服务而不是不服务;限流需要评估好,不可乱用,否则会正常流量出现一些奇怪的问题而导致用户抱怨。
在实际应用时也不要太纠结算法问题,因为一些限流算法实现是一样的只是描述不一样;具体使用哪种限流技术还是要根据实际场景来选择,不要一味去找最佳模式,白猫黑猫能解决问题的就是好猫。
因在实际工作中遇到过许多人来问如何进行限流,因此本文会详细介绍各种限流手段。那么接下来我们从限流算法、应用级限流、分布式限流、接入层限流来详细学习下限流技术手段。
限流算法
常见的限流算法有:令牌桶、漏桶。计数器也可以进行粗暴限流实现。
令牌桶算法
令牌桶算法是一个存放固定容量令牌的桶,按照固定速率往桶里添加令牌。令牌桶算法的描述如下:
-
假设限制2r/s,则按照500毫秒的固定速率往桶中添加令牌;
-
桶中最多存放b个令牌,当桶满时,新添加的令牌被丢弃或拒绝;
-
当一个n个字节大小的数据包到达,将从桶中删除n个令牌,接着数据包被发送到网络上;
-
如果桶中的令牌不足n个,则不会删除令牌,且该数据包将被限流(要么丢弃,要么缓冲区等待)。

漏桶算法
漏桶作为计量工具(The Leaky Bucket Algorithm as a Meter)时,可以用于流量整形(Traffic Shaping)和流量控制(TrafficPolicing),漏桶算法的描述如下:
-
一个固定容量的漏桶,按照常量固定速率流出水滴;
-
如果桶是空的,则不需流出水滴;
-
可以以任意速率流入水滴到漏桶;
-
如果流入水滴超出了桶的容量,则流入的水滴溢出了(被丢弃),而漏桶容量是不变的。

令牌桶和漏桶对比:
-
令牌桶是按照固定速率往桶中添加令牌,请求是否被处理需要看桶中令牌是否足够,当令牌数减为零时则拒绝新的请求;
-
漏桶则是按照常量固定速率流出请求,流入请求速率任意,当流入的请求数累积到漏桶容量时,则新流入的请求被拒绝;
-
令牌桶限制的是平均流入速率(允许突发请求,只要有令牌就可以处理,支持一次拿3个令牌,4个令牌),并允许一定程度突发流量;
-
漏桶限制的是常量流出速率(即流出速率是一个固定常量值,比如都是1的速率流出,而不能一次是1,下次又是2),从而平滑突发流入速率;
-
令牌桶允许一定程度的突发,而漏桶主要目的是平滑流入速率;
-
两个算法实现可以一样,但是方向是相反的,对于相同的参数得到的限流效果是一样的。
另外有时候我们还使用计数器来进行限流,主要用来限制总并发数,比如数据库连接池、线程池、秒杀的并发数;只要全局总请求数或者一定时间段的总请求数设定的阀值则进行限流,是简单粗暴的总数量限流,而不是平均速率限流。
到此基本的算法就介绍完了,接下来我们首先看看应用级限流。
应用级限流
限流总并发/连接/请求数
对于一个应用系统来说一定会有极限并发/请求数,即总有一个TPS/QPS阀值,如果超了阀值则系统就会不响应用户请求或响应的非常慢,因此我们最好进行过载保护,防止大量请求涌入击垮系统。
如果你使用过Tomcat,其Connector 其中一种配置有如下几个参数:
acceptCount:如果Tomcat的线程都忙于响应,新来的连接会进入队列排队,如果超出排队大小,则拒绝连接;
maxConnections: 瞬时最大连接数,超出的会排队等待;
maxThreads:Tomcat能启动用来处理请求的最大线程数,如果请求处理量一直远远大于最大线程数则可能会僵死。
详细的配置请参考官方文档。另外如Mysql(如max_connections)、Redis(如tcp-backlog)都会有类似的限制连接数的配置。
限流总资源数
如果有的资源是稀缺资源(如数据库连接、线程),而且可能有多个系统都会去使用它,那么需要限制应用;可以使用池化技术来限制总资源数:连接池、线程池。比如分配给每个应用的数据库连接是100,那么本应用最多可以使用100个资源,超出了可以等待或者抛异常。
限流某个接口的总并发/请求数
如果接口可能会有突发访问情况,但又担心访问量太大造成崩溃,如抢购业务;这个时候就需要限制这个接口的总并发/请求数总请求数了;因为粒度比较细,可以为每个接口都设置相应的阀值。可以使用Java中的AtomicLong进行限流:
try {
if(atomic.incrementAndGet() > 限流数) {
//拒绝请求
}
//处理请求
} finally {
atomic.decrementAndGet();
}
适合对业务无损的服务或者需要过载保护的服务进行限流,如抢购业务,超出了大小要么让用户排队,要么告诉用户没货了,对用户来说是可以接受的。而一些开放平台也会限制用户调用某个接口的试用请求量,也可以用这种计数器方式实现。这种方式也是简单粗暴的限流,没有平滑处理,需要根据实际情况选择使用;
限流某个接口的时间窗请求数
即一个时间窗口内的请求数,如想限制某个接口/服务每秒/每分钟/每天的请求数/调用量。如一些基础服务会被很多其他系统调用,比如商品详情页服务会调用基础商品服务调用,但是怕因为更新量比较大将基础服务打挂,这时我们要对每秒/每分钟的调用量进行限速;一种实现方式如下所示:
LoadingCache<Long, AtomicLong> counter =
CacheBuilder.newBuilder()
.expireAfterWrite(2, TimeUnit.SECONDS)
.build(new CacheLoader<Long, AtomicLong>() {
@Override
public AtomicLong load(Long seconds) throws Exception {
return new AtomicLong(0);
}
});
long limit = 1000;
while(true) {
//得到当前秒
long currentSeconds = System.currentTimeMillis() / 1000;
if(counter.get(currentSeconds).incrementAndGet() > limit) {
System.out.println("限流了:" + currentSeconds);
continue;
}
//业务处理
}
我们使用Guava的Cache来存储计数器,过期时间设置为2秒(保证1秒内的计数器是有的),然后我们获取当前时间戳然后取秒数来作为KEY进行计数统计和限流,这种方式也是简单粗暴,刚才说的场景够用了。
平滑限流某个接口的请求数
之前的限流方式都不能很好地应对突发请求,即瞬间请求可能都被允许从而导致一些问题;因此在一些场景中需要对突发请求进行整形,整形为平均速率请求处理(比如5r/s,则每隔200毫秒处理一个请求,平滑了速率)。这个时候有两种算法满足我们的场景:令牌桶和漏桶算法。Guava框架提供了令牌桶算法实现,可直接拿来使用。
Guava RateLimiter提供了令牌桶算法实现:平滑突发限流(SmoothBursty)和平滑预热限流(SmoothWarmingUp)实现。
SmoothBursty
RateLimiter limiter = RateLimiter.create(5);
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
将得到类似如下的输出:
0.0
0.198239
0.196083
0.200609
0.199599
0.19961
1、RateLimiter.create(5) 表示桶容量为5且每秒新增5个令牌,即每隔200毫秒新增一个令牌;
2、limiter.acquire()表示消费一个令牌,如果当前桶中有足够令牌则成功(返回值为0),如果桶中没有令牌则暂停一段时间,比如发令牌间隔是200毫秒,则等待200毫秒后再去消费令牌(如上测试用例返回的为0.198239,差不多等待了200毫秒桶中才有令牌可用),这种实现将突发请求速率平均为了固定请求速率。
再看一个突发示例:
System.out.println(limiter.acquire(5));
System.out.println(limiter.acquire(1));
System.out.println(limiter.acquire(1));
将得到类似如下的输出:
0.0
0.98745
0.183553
0.199909
limiter.acquire(5)表示桶的容量为5且每秒新增5个令牌,令牌桶算法允许一定程度的突发,所以可以一次性消费5个令牌,但接下来的limiter.acquire(1)将等待差不多1秒桶中才能有令牌,且接下来的请求也整形为固定速率了。
System.out.println(limiter.acquire(10));
System.out.println(limiter.acquire(1));
System.out.println(limiter.acquire(1));
将得到类似如下的输出:
0.0
1.997428
0.192273
0.200616
同上边的例子类似,第一秒突发了10个请求,令牌桶算法也允许了这种突发(允许消费未来的令牌),但接下来的limiter.acquire(1)将等待差不多2秒桶中才能有令牌,且接下来的请求也整形为固定速率了。
接下来再看一个突发的例子:
System.out.println(limiter.acquire());
Thread.sleep(2000L);
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
System.out.println(limiter.acquire());
将得到类似如下的输出:
0.0
0.0
0.0
0.0
0.499876
0.495799
1、创建了一个桶容量为2且每秒新增2个令牌;
2、首先调用limiter.acquire()消费一个令牌,此时令牌桶可以满足(返回值为0);
3、然后线程暂停2秒,接下来的两个limiter.acquire()都能消费到令牌,第三个limiter.acquire()也同样消费到了令牌,到第四个时就需要等待500毫秒了。
此处可以看到我们设置的桶容量为2(即允许的突发量),这是因为SmoothBursty中有一个参数:最大突发秒数(maxBurstSeconds)默认值是1s,突发量/桶容量=速率*maxBurstSeconds,所以本示例桶容量/突发量为2,例子中前两个是消费了之前积攒的突发量,而第三个开始就是正常计算的了。令牌桶算法允许将一段时间内没有消费的令牌暂存到令牌桶中,留待未来使用,并允许未来请求的这种突发。
SmoothBursty通过平均速率和最后一次新增令牌的时间计算出下次新增令牌的时间的,另外需要一个桶暂存一段时间内没有使用的令牌(即可以突发的令牌数)。另外RateLimiter还提供了tryAcquire方法来进行无阻塞或可超时的令牌消费。
因为SmoothBursty允许一定程度的突发,会有人担心如果允许这种突发,假设突然间来了很大的流量,那么系统很可能扛不住这种突发。因此需要一种平滑速率的限流工具,从而系统冷启动后慢慢的趋于平均固定速率(即刚开始速率小一些,然后慢慢趋于我们设置的固定速率)。Guava也提供了SmoothWarmingUp来实现这种需求,其可以认为是漏桶算法,但是在某些特殊场景又不太一样。
SmoothWarmingUp创建方式:RateLimiter.create(doublepermitsPerSecond, long warmupPeriod, TimeUnit unit)
permitsPerSecond表示每秒新增的令牌数,warmupPeriod表示在从冷启动速率过渡到平均速率的时间间隔。
示例如下:
for(int i = 1; i < 5;i++) {
System.out.println(limiter.acquire());
}
Thread.sleep(1000L);
for(int i = 1; i < 5;i++) {
System.out.println(limiter.acquire());
}
将得到类似如下的输出:
0.0
0.51767
0.357814
0.219992
0.199984
0.0
0.360826
0.220166
0.199723
0.199555
速率是梯形上升速率的,也就是说冷启动时会以一个比较大的速率慢慢到平均速率;然后趋于平均速率(梯形下降到平均速率)。可以通过调节warmupPeriod参数实现一开始就是平滑固定速率。
到此应用级限流的一些方法就介绍完了。假设将应用部署到多台机器,应用级限流方式只是单应用内的请求限流,不能进行全局限流。因此我们需要分布式限流和接入层限流来解决这个问题。
分布式限流
分布式限流最关键的是要将限流服务做成原子化,而解决方案可以使使用redis+lua或者nginx+lua技术进行实现,通过这两种技术可以实现的高并发和高性能。
首先我们来使用redis+lua实现时间窗内某个接口的请求数限流,实现了该功能后可以改造为限流总并发/请求数和限制总资源数。Lua本身就是一种编程语言,也可以使用它实现复杂的令牌桶或漏桶算法。
redis+lua实现中的lua脚本:
local limit = tonumber(ARGV[1]) --限流大小
local current = tonumber(redis.call("INCRBY", key, "1")) --请求数+1
if current > limit then --如果超出限流大小
return 0
elseif current == 1 then --只有第一次访问需要设置2秒的过期时间
redis.call("expire", key,"2")
end
return 1
如上操作因是在一个lua脚本中,又因Redis是单线程模型,因此是线程安全的。如上方式有一个缺点就是当达到限流大小后还是会递增的,可以改造成如下方式实现:
local limit = tonumber(ARGV[1]) --限流大小
local current = tonumber(redis.call('get', key) or "0")
if current + 1 > limit then --如果超出限流大小
return 0
else --请求数+1,并设置2秒过期
redis.call("INCRBY", key,"1")
redis.call("expire", key,"2")
return 1
end
如下是Java中判断是否需要限流的代码:
String luaScript = Files.toString(new File("limit.lua"), Charset.defaultCharset());
Jedis jedis = new Jedis("192.168.147.52", 6379);
String key = "ip:" + System.currentTimeMillis()/ 1000; //此处将当前时间戳取秒数
Stringlimit = "3"; //限流大小
return (Long)jedis.eval(luaScript,Lists.newArrayList(key), Lists.newArrayList(limit)) == 1;
}
因为Redis的限制(Lua中有写操作不能使用带随机性质的读操作,如TIME)不能在Redis Lua中使用TIME获取时间戳,因此只好从应用获取然后传入,在某些极端情况下(机器时钟不准的情况下),限流会存在一些小问题。
使用Nginx+Lua实现的Lua脚本:
local function acquire()
local lock =locks:new("locks")
local elapsed, err =lock:lock("limit_key") --互斥锁
local limit_counter =ngx.shared.limit_counter --计数器
local key = "ip:" ..os.time()
local limit = 5 --限流大小
local current =limit_counter:get(key)
if current ~= nil and current + 1> limit then --如果超出限流大小
lock:unlock()
return 0
end
if current == nil then
limit_counter:set(key, 1, 1) --第一次需要设置过期时间,设置key的值为1,过期时间为1秒
else
limit_counter:incr(key, 1) --第二次开始加1即可
end
lock:unlock()
return 1
end
ngx.print(acquire())
实现中我们需要使用lua-resty-lock互斥锁模块来解决原子性问题(在实际工程中使用时请考虑获取锁的超时问题),并使用ngx.shared.DICT共享字典来实现计数器。如果需要限流则返回0,否则返回1。使用时需要先定义两个共享字典(分别用来存放锁和计数器数据):
- http {
- ……
- lua_shared_dict locks 10m;
- lua_shared_dict limit_counter 10m;
- }
有人会纠结如果应用并发量非常大那么redis或者nginx是不是能抗得住;不过这个问题要从多方面考虑:你的流量是不是真的有这么大,是不是可以通过一致性哈希将分布式限流进行分片,是不是可以当并发量太大降级为应用级限流;对策非常多,可以根据实际情况调节;像在京东使用Redis+Lua来限流抢购流量,一般流量是没有问题的。
对于分布式限流目前遇到的场景是业务上的限流,而不是流量入口的限流;流量入口限流应该在接入层完成,而接入层笔者一般使用Nginx。
接入层限流
接入层通常指请求流量的入口,该层的主要目的有:负载均衡、非法请求过滤、请求聚合、缓存、降级、限流、A/B测试、服务质量监控等等,可以参考笔者写的《使用Nginx+Lua(OpenResty)开发高性能Web应用》。
对于Nginx接入层限流可以使用Nginx自带了两个模块:连接数限流模块ngx_http_limit_conn_module和漏桶算法实现的请求限流模块ngx_http_limit_req_module。还可以使用OpenResty提供的Lua限流模块lua-resty-limit-traffic进行更复杂的限流场景。
limit_conn用来对某个KEY对应的总的网络连接数进行限流,可以按照如IP、域名维度进行限流。limit_req用来对某个KEY对应的请求的平均速率进行限流,并有两种用法:平滑模式(delay)和允许突发模式(nodelay)。
ngx_http_limit_conn_module
limit_conn是对某个KEY对应的总的网络连接数进行限流。可以按照IP来限制IP维度的总连接数,或者按照服务域名来限制某个域名的总连接数。但是记住不是每一个请求连接都会被计数器统计,只有那些被Nginx处理的且已经读取了整个请求头的请求连接才会被计数器统计。
配置示例:
limit_conn_zone$binary_remote_addr zone=addr:10m;
limit_conn_log_level error;
limit_conn_status 503;
...
server {
...
location /limit {
limit_conn addr 1;
}
limit_conn:要配置存放KEY和计数器的共享内存区域和指定KEY的最大连接数;此处指定的最大连接数是1,表示Nginx最多同时并发处理1个连接;
limit_conn_zone:用来配置限流KEY、及存放KEY对应信息的共享内存区域大小;此处的KEY是“$binary_remote_addr”其表示IP地址,也可以使用如$server_name作为KEY来限制域名级别的最大连接数;
limit_conn_status:配置被限流后返回的状态码,默认返回503;
limit_conn_log_level:配置记录被限流后的日志级别,默认error级别。
limit_conn的主要执行过程如下所示:
1、请求进入后首先判断当前limit_conn_zone中相应KEY的连接数是否超出了配置的最大连接数;
2.1、如果超过了配置的最大大小,则被限流,返回limit_conn_status定义的错误状态码;
2.2、否则相应KEY的连接数加1,并注册请求处理完成的回调函数;
3、进行请求处理;
4、在结束请求阶段会调用注册的回调函数对相应KEY的连接数减1。
limt_conn可以限流某个KEY的总并发/请求数,KEY可以根据需要变化。
按照IP限制并发连接数配置示例:
首先定义IP维度的限流区域:
接着在要限流的location中添加限流逻辑:
limit_conn perip 2;
echo "123";
}
即允许每个IP最大并发连接数为2。
使用AB测试工具进行测试,并发数为5个,总的请求数为5个:
将得到如下access.log输出:
[08/Jun/2016:20:10:51+0800] [1465373451.802] 200
[08/Jun/2016:20:10:51+0800] [1465373451.803] 200
[08/Jun/2016:20:10:51 +0800][1465373451.803] 503
[08/Jun/2016:20:10:51 +0800][1465373451.803] 503
[08/Jun/2016:20:10:51 +0800][1465373451.803] 503
此处我们把access log格式设置为log_format main '[$time_local] [$msec] $status';分别是“日期 日期秒/毫秒值 响应状态码”。
如果被限流了,则在error.log中会看到类似如下的内容:
按照域名限制并发连接数配置示例:
首先定义域名维度的限流区域:
接着在要限流的location中添加限流逻辑:
limit_conn perserver 2;
echo "123";
}
即允许每个域名最大并发请求连接数为2;这样配置可以实现服务器最大连接数限制。
ngx_http_limit_req_module
limit_req是漏桶算法实现,用于对指定KEY对应的请求进行限流,比如按照IP维度限制请求速率。
配置示例:
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
limit_conn_log_level error;
limit_conn_status 503;
...
server {
...
location /limit {
limit_req zone=one burst=5 nodelay;
}
limit_req:配置限流区域、桶容量(突发容量,默认0)、是否延迟模式(默认延迟);
limit_req_zone:配置限流KEY、及存放KEY对应信息的共享内存区域大小、固定请求速率;此处指定的KEY是“$binary_remote_addr”表示IP地址;固定请求速率使用rate参数配置,支持10r/s和60r/m,即每秒10个请求和每分钟60个请求,不过最终都会转换为每秒的固定请求速率(10r/s为每100毫秒处理一个请求;60r/m,即每1000毫秒处理一个请求)。
limit_conn_status:配置被限流后返回的状态码,默认返回503;
limit_conn_log_level:配置记录被限流后的日志级别,默认error级别。
limit_req的主要执行过程如下所示:
1、请求进入后首先判断最后一次请求时间相对于当前时间(第一次是0)是否需要限流,如果需要限流则执行步骤2,否则执行步骤3;
2.1、如果没有配置桶容量(burst),则桶容量为0;按照固定速率处理请求;如果请求被限流,则直接返回相应的错误码(默认503);
2.2、如果配置了桶容量(burst>0)且延迟模式(没有配置nodelay);如果桶满了,则新进入的请求被限流;如果没有满则请求会以固定平均速率被处理(按照固定速率并根据需要延迟处理请求,延迟使用休眠实现);
2.3、如果配置了桶容量(burst>0)且非延迟模式(配置了nodelay);不会按照固定速率处理请求,而是允许突发处理请求;如果桶满了,则请求被限流,直接返回相应的错误码;
3、如果没有被限流,则正常处理请求;
4、Nginx会在相应时机进行选择一些(3个节点)限流KEY进行过期处理,进行内存回收。
场景2.1测试
首先定义IP维度的限流区域:
限制为每秒500个请求,固定平均速率为2毫秒一个请求。
接着在要限流的location中添加限流逻辑:
limit_req zone=test;
echo "123";
}
即桶容量为0(burst默认为0),且延迟模式。
使用AB测试工具进行测试,并发数为2个,总的请求数为10个:
将得到如下access.log输出:
[08/Jun/2016:20:25:56+0800] [1465381556.410] 200
[08/Jun/2016:20:25:56 +0800][1465381556.410] 503
[08/Jun/2016:20:25:56 +0800][1465381556.411] 503
[08/Jun/2016:20:25:56+0800] [1465381556.411] 200
[08/Jun/2016:20:25:56 +0800][1465381556.412] 503
[08/Jun/2016:20:25:56 +0800][1465381556.412] 503
虽然每秒允许500个请求,但是因为桶容量为0,所以流入的请求要么被处理要么被限流,无法延迟处理;另外平均速率在2毫秒左右,比如1465381556.410和1465381556.411被处理了;有朋友会说这固定平均速率不是1毫秒嘛,其实这是因为实现算法没那么精准造成的。
如果被限流在error.log中会看到如下内容:
2016/06/08 20:25:56 [error] 6130#0: *1962limiting requests, excess: 1.000 by zone "test", client: 127.0.0.1,server: _, request: "GET /limit HTTP/1.0", host:"localhost"
如果被延迟了在error.log(日志级别要INFO级别)中会看到如下内容:
2016/06/10 09:05:23 [warn] 9766#0: *97021delaying request, excess: 0.368, by zone "test", client: 127.0.0.1,server: _, request: "GET /limit HTTP/1.0", host:"localhost"
场景2.2测试
首先定义IP维度的限流区域:
为了方便测试设置速率为每秒2个请求,即固定平均速率是500毫秒一个请求。
接着在要限流的location中添加限流逻辑:
limit_req zone=test burst=3;
echo "123";
}
固定平均速率为500毫秒一个请求,通容量为3,如果桶满了新的请求被限流,否则可以进入桶中排队并等待(实现延迟模式)。
为了看出限流效果我们写了一个req.sh脚本:
sleep 0.3
ab -c 6 -n 6 http://localhost/limit
首先进行6个并发请求6次URL,然后休眠300毫秒,然后再进行6个并发请求6次URL;中间休眠目的是为了能跨越2秒看到效果,如果看不到如下的效果可以调节休眠时间。
将得到如下access.log输出:
[09/Jun/2016:08:46:43+0800] [1465433203.959] 200
[09/Jun/2016:08:46:43 +0800][1465433203.959] 503
[09/Jun/2016:08:46:43 +0800][1465433203.960] 503
[09/Jun/2016:08:46:44+0800] [1465433204.450] 200
[09/Jun/2016:08:46:44+0800] [1465433204.950] 200
[09/Jun/2016:08:46:45 +0800][1465433205.453] 200
[09/Jun/2016:08:46:45 +0800][1465433205.766] 503
[09/Jun/2016:08:46:45 +0800][1465433205.766] 503
[09/Jun/2016:08:46:45 +0800][1465433205.767] 503
[09/Jun/2016:08:46:45+0800] [1465433205.950] 200
[09/Jun/2016:08:46:46+0800] [1465433206.451] 200
[09/Jun/2016:08:46:46+0800] [1465433206.952] 200

桶容量为3,即桶中在时间窗口内最多流入3个请求,且按照2r/s的固定速率处理请求(即每隔500毫秒处理一个请求);桶计算时间窗口(1.5秒)=速率(2r/s)/桶容量(3),也就是说在这个时间窗口内桶最多暂存3个请求。因此我们要以当前时间往前推1.5秒和1秒来计算时间窗口内的总请求数;另外因为默认是延迟模式,所以时间窗内的请求要被暂存到桶中,并以固定平均速率处理请求:
第一轮:有4个请求处理成功了,按照漏桶桶容量应该最多3个才对;这是因为计算算法的问题,第一次计算因没有参考值,所以第一次计算后,后续的计算才能有参考值,因此第一次成功可以忽略;这个问题影响很小可以忽略;而且按照固定500毫秒的速率处理请求。
第二轮:因为第一轮请求是突发来的,差不多都在1465433203.959时间点,只是因为漏桶将速率进行了平滑变成了固定平均速率(每500毫秒一个请求);而第二轮计算时间应基于1465433203.959;而第二轮突发请求差不多都在1465433205.766时间点,因此计算桶容量的时间窗口应基于1465433203.959和1465433205.766来计算,计算结果为1465433205.766这个时间点漏桶为空了,可以流入桶中3个请求,其他请求被拒绝;又因为第一轮最后一次处理时间是1465433205.453,所以第二轮第一个请求被延迟到了1465433205.950。这里也要注意固定平均速率只是在配置的速率左右,存在计算精度问题,会有一些偏差。
如果桶容量改为1(burst=1),执行req.sh脚本可以看到如下输出:
09/Jun/2016:09:04:30+0800] [1465434270.362] 200
[09/Jun/2016:09:04:30 +0800][1465434270.371] 503
[09/Jun/2016:09:04:30 +0800] [1465434270.372]503
[09/Jun/2016:09:04:30 +0800][1465434270.372] 503
[09/Jun/2016:09:04:30 +0800][1465434270.372] 503
[09/Jun/2016:09:04:30+0800] [1465434270.864] 200
[09/Jun/2016:09:04:31 +0800][1465434271.178] 503
[09/Jun/2016:09:04:31 +0800][1465434271.178] 503
[09/Jun/2016:09:04:31 +0800][1465434271.178] 503
[09/Jun/2016:09:04:31 +0800][1465434271.178] 503
[09/Jun/2016:09:04:31 +0800][1465434271.179] 503
[09/Jun/2016:09:04:31+0800] [1465434271.366] 200
桶容量为1,按照每1000毫秒一个请求的固定平均速率处理请求。
场景2.3测试
首先定义IP维度的限流区域:
为了方便测试配置为每秒2个请求,固定平均速率是500毫秒一个请求。
接着在要限流的location中添加限流逻辑:
limit_req zone=test burst=3 nodelay;
echo "123";
}
桶容量为3,如果桶满了直接拒绝新请求,且每秒2最多两个请求,桶按照固定500毫秒的速率以nodelay模式处理请求。
为了看到限流效果我们写了一个req.sh脚本:
sleep 1
ab -c 6 -n 6 http://localhost/limit
sleep 0.3
ab -c 6 -n 6 http://localhost/limit
sleep 0.3
ab -c 6 -n 6 http://localhost/limit
sleep 0.3
ab -c 6 -n 6 http://localhost/limit
sleep 2
ab -c 6 -n 6 http://localhost/limit
将得到类似如下access.log输出:
[09/Jun/2016:14:30:11+0800] [1465453811.754] 200
[09/Jun/2016:14:30:11+0800] [1465453811.755] 200
[09/Jun/2016:14:30:11+0800] [1465453811.755] 200
[09/Jun/2016:14:30:11+0800] [1465453811.759] 200
[09/Jun/2016:14:30:11 +0800][1465453811.759] 503
[09/Jun/2016:14:30:11 +0800][1465453811.759] 503
[09/Jun/2016:14:30:12+0800] [1465453812.776] 200
[09/Jun/2016:14:30:12+0800] [1465453812.776] 200
[09/Jun/2016:14:30:12 +0800][1465453812.776] 503
[09/Jun/2016:14:30:12 +0800][1465453812.777] 503
[09/Jun/2016:14:30:12 +0800][1465453812.777] 503
[09/Jun/2016:14:30:12 +0800][1465453812.777] 503
[09/Jun/2016:14:30:13 +0800] [1465453813.095]503
[09/Jun/2016:14:30:13 +0800][1465453813.097] 503
[09/Jun/2016:14:30:13 +0800][1465453813.097] 503
[09/Jun/2016:14:30:13 +0800][1465453813.097] 503
[09/Jun/2016:14:30:13 +0800][1465453813.097] 503
[09/Jun/2016:14:30:13 +0800][1465453813.098] 503
[09/Jun/2016:14:30:13+0800] [1465453813.425] 200
[09/Jun/2016:14:30:13 +0800][1465453813.425] 503
[09/Jun/2016:14:30:13 +0800][1465453813.425] 503
[09/Jun/2016:14:30:13 +0800][1465453813.426] 503
[09/Jun/2016:14:30:13 +0800][1465453813.426] 503
[09/Jun/2016:14:30:13 +0800][1465453813.426] 503
[09/Jun/2016:14:30:13+0800] [1465453813.754] 200
[09/Jun/2016:14:30:13 +0800][1465453813.755] 503
[09/Jun/2016:14:30:13 +0800][1465453813.755] 503
[09/Jun/2016:14:30:13 +0800][1465453813.756] 503
[09/Jun/2016:14:30:13 +0800][1465453813.756] 503
[09/Jun/2016:14:30:13 +0800][1465453813.756] 503
[09/Jun/2016:14:30:15+0800] [1465453815.278] 200
[09/Jun/2016:14:30:15+0800] [1465453815.278] 200
[09/Jun/2016:14:30:15+0800] [1465453815.278] 200
[09/Jun/2016:14:30:15 +0800][1465453815.278] 503
[09/Jun/2016:14:30:15 +0800][1465453815.279] 503
[09/Jun/2016:14:30:15 +0800][1465453815.279] 503
[09/Jun/2016:14:30:17+0800] [1465453817.300] 200
[09/Jun/2016:14:30:17+0800] [1465453817.300] 200
[09/Jun/2016:14:30:17+0800] [1465453817.300] 200
[09/Jun/2016:14:30:17+0800] [1465453817.301] 200
[09/Jun/2016:14:30:17 +0800][1465453817.301] 503
[09/Jun/2016:14:30:17 +0800][1465453817.301] 503

桶容量为3(,即桶中在时间窗口内最多流入3个请求,且按照2r/s的固定速率处理请求(即每隔500毫秒处理一个请求);桶计算时间窗口(1.5秒)=速率(2r/s)/桶容量(3),也就是说在这个时间窗口内桶最多暂存3个请求。因此我们要以当前时间往前推1.5秒和1秒来计算时间窗口内的总请求数;另外因为配置了nodelay,是非延迟模式,所以允许时间窗内突发请求的;另外从本示例会看出两个问题:
第一轮和第七轮:有4个请求处理成功了;这是因为计算算法的问题,本示例是如果2秒内没有请求,然后接着突然来了很多请求,第一次计算的结果将是不正确的;这个问题影响很小可以忽略;
第五轮:1.0秒计算出来是3个请求;此处也是因计算精度的问题,也就是说limit_req实现的算法不是非常精准的,假设此处看成相对于2.75的话,1.0秒内只有1次请求,所以还是允许1次请求的。
如果限流出错了,可以配置错误页面:
recursive_error_pages on;
error_page 503 //www.jd.com/error.aspx;
limit_conn_zone/limit_req_zone定义的内存不足,则后续的请求将一直被限流,所以需要根据需求设置好相应的内存大小。
此处的限流都是单Nginx的,假设我们接入层有多个nginx,此处就存在和应用级限流相同的问题;那如何处理呢?一种解决办法:建立一个负载均衡层将按照限流KEY进行一致性哈希算法将请求哈希到接入层Nginx上,从而相同KEY的将打到同一台接入层Nginx上;另一种解决方案就是使用Nginx+Lua(OpenResty)调用分布式限流逻辑实现。
lua-resty-limit-traffic
之前介绍的两个模块使用上比较简单,指定KEY、指定限流速率等就可以了,如果我们想根据实际情况变化KEY、变化速率、变化桶大小等这种动态特性,使用标准模块就很难去实现了,因此我们需要一种可编程来解决我们问题;而OpenResty提供了lua限流模块lua-resty-limit-traffic,通过它可以按照更复杂的业务逻辑进行动态限流处理了。其提供了limit.conn和limit.req实现,算法与nginx limit_conn和limit_req是一样的。
此处我们来实现ngx_http_limit_req_module中的【场景2.2测试】,不要忘记下载lua-resty-limit-traffic模块并添加到OpenResty的lualib中。
配置用来存放限流用的共享字典:
以下是实现【场景2.2测试】的限流代码limit_req.lua:
local rate = 2 --固定平均速率 2r/s
local burst = 3 --桶容量
local error_status = 503
local nodelay = false --是否需要不延迟处理
local lim, err = limit_req.new("limit_req_store", rate, burst)
if not lim then --没定义共享字典
ngx.exit(error_status)
end
local key = ngx.var.binary_remote_addr --IP维度的限流
--流入请求,如果请求需要被延迟则delay > 0
local delay, err = lim:incoming(key, true)
if not delay and err == "rejected" then --超出桶大小了
ngx.exit(error_status)
end
if delay > 0 then --根据需要决定是延迟或者不延迟处理
if nodelay then
--直接突发处理了
else
ngx.sleep(delay) --延迟处理
end
end
即限流逻辑再nginx access阶段被访问,如果不被限流继续后续流程;如果需要被限流要么sleep一段时间继续后续流程,要么返回相应的状态码拒绝请求。
在分布式限流中我们使用了简单的Nginx+Lua进行分布式限流,有了这个模块也可以使用这个模块来实现分布式限流。
另外在使用Nginx+Lua时也可以获取ngx.var.connections_active进行过载保护,即如果当前活跃连接数超过阈值进行限流保护。
//限流
end
nginx也提供了limit_rate用来对流量限速,如limit_rate 50k,表示限制下载速度为50k。
到此笔者在工作中涉及的限流用法就介绍完,这些算法中有些允许突发,有些会整形为平滑,有些计算算法简单粗暴;其中令牌桶算法和漏桶算法实现上是类似的,只是表述的方向不太一样,对于业务来说不必刻意去区分它们;因此需要根据实际场景来决定如何限流,最好的算法不一定是最适用的。
参考资料
https://en.wikipedia.org/wiki/Token_bucket
https://en.wikipedia.org/wiki/Leaky_bucket
http://redis.io/commands/incr
http://nginx.org/en/docs/http/ngx_http_limit_req_module.html
http://nginx.org/en/docs/http/ngx_http_limit_conn_module.html
https://github.com/openresty/lua-resty-limit-traffic
http://nginx.org/en/docs/http/ngx_http_core_module.html#limit_rate
系统监控和流控-java应用
目前系统的监控方面,linux机器,可以定时的获取cpu、load、IO、网络等情况,统计之后,如果超过阀值,即可报警。
web的请求,可以通过分析apache的日志,获取PV、UV以及页面的响应时间等信息,统计这些信息,如果有异常,报警即可。
但是java系统(一个java进程)中的bean的情况如何做到监控和流控呢?
双十一,各个系统都有一些监控和流控的策略,了解了一圈之后,打算总结一下,只是粗略的写一下思路,记录一下,不涉及到细节(因为细节坑很多)。
监控的目前是为了了解系统的运行细节,流控是为了在出现问题(瞬间请求暴涨、持续一段时间请求超过平均值、底层依赖的应用或者DB出现异常)的时候能够做出处理(动态限流拒绝新的请求进来<限流策略可以设置>、利用开关<修改静态类的属性>进行应用降级处理减少非核心的调用)。
(1)业务日志
监控业务代码抛出来的日志信息(可以在linux中通过crontab定时程序来抓取,也可以通过控制台来远程处理,也可以把文件拉到集中的分析服务器来处理),如果异常数太多,或者出现自己之前设置过的报警关键字,则进行报警;
(2)java gc的日志
java在运行过程中,如果配置了参数(-verbose:gc -Xloggc:/home/admin/logs/gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps),能够看到系统的gc的情况,如果FullGc特别频繁(超过一小时一次),可以提示报警;
(3)拥堵线程数作为监控指标
创建一个对象,里面一个key是方法的代表,然后属性中有个计数器(这个key此时对应的拥堵线程数),如果方法体内处理变慢,并发情况下拥堵线程数会增加,此时,可以进行报警,也可以把后续的请求当掉,降低负载。计数器进行变化可以有两种方式:第一种就是,通过AOP的方式,在方法调用前(before)拥堵线程数加一,方法返回后(after)拥堵线程数减一,这种好处就是不用硬编码;另外一种就需要写代码,在方法体内,调用开始加以,然后try住,在finally的时候减一。
(4)根据方法调用的QPS和RT
QPS即一秒内方法调用的次数,RT即一秒内方法调用的平均返回时间。对于web请求,一般在web服务器(apache/nginx)中做掉这个,在服务器A中部署一个client,用来做计数统计,具体的计数规则可能会比较复杂,超过阀值(有可能是攻击),则请求server端此时的拒绝策略,是让用户等待,还是跳转待验证码页面让其输入验证码之后再进行访问,还是直接返回错误。对于java中的bean方法,如何获取呢?如三种描述,两种方式一种是AOP拦截,一种是代码中硬编码。
(5)基于AOP获取一个特定方法在特定时间段(例如一分钟)的拥堵线程数、执行次数(总次数、成功次数、失败次数)、响应时间
做一个本地内存对象,用于记录这些信息,通过AOP的before获取信息(当前时间,线程数加一,调用次数加一),afterReturen获取信息(返回时间、线程数减一,调用次数加一,可以定制啥叫成功失败,然后相应次数增加),afterThrowing获取信息(返回时间、线程数减一、失败次数加一),最后定时dump内存中的数据,存储到DB或者日志,然后对于这些信息进行监控(可以根据历史来进行同比和环比)进行报警。
(6)动态来添加QPS和RT的流控
这种流控方式最为灵活,应用端依赖一个jar包,然后添加一个全局的AOP配置(对于页面的请求,在web.xml中添加filter即可),拦截所有的方法(性能消耗可以忽略),但是只有符合规则的方法才会进行统计,然后有一个控制台设置规则,设置好规则后推送到应用端,应用端获取这个规则,根据这个规则来进行统计,超出阀值则进行限流。这种方式最为灵活,遇到紧急问题的时候可以通过控制台来限流掉。
(7)请求是海量的情况下如何进行监控
在请求很大的情况下,此时应用就不要处理监控的逻辑了,只要获取调用的信息(时间点、响应时间、方法签名等信息),然后把这些信息打印到日志中,异步来进行处理,把这些日志拉到专门的分析集群,然后在分析集群里面来做实时的分析,把分析的结果持久话到BD,对于分析后的结构化数据进行监控。
转载公司一位同事的文章:
http://rdc.taobao.com/team/jm/archives/2594
流量预警和限流方案中,比较常用的有两种。第一种滑窗模式,通过统计多个单元时间的访问次数来进行控制,当单位时间的访问次数达到的某个峰值时进行限流。第二种为响应模式,通过控制当前活跃请求数,来进行流量控制。下面来简单分析下两种的优缺点。
1、滑窗模式
模式分析:
在每次有访问进来时,我们判断前N个单位时间里总访问量是否超过了设置的阈值,若超过则不允许执行。
这种模式的实现的方式更加契合流控的本质意义。理解较为简单。但由于访问量的预先不可预见性,会发生单位时间的前半段有大量的请求涌入,而后半段则拒绝所有请求的情况发生。(一般,需要会将单位时间切的足够的细来解决这个问题)其次,我们很难确定这个阈值设置在多少比较合适,只能通过经验或者模拟(如压测)来进行估计,不过即使是压测也很难估计的准确,线上每台机器的硬件参数的不同,或者同一台机子在不同的时间点其可以接受的阈值也不尽相同(系统中),每个时间点导致能够承受的最大阈值也不尽相同,我们无法考虑的周全。
所以滑窗模式往往用来对某一资源的保护上(或者说是承诺比较合适:我对某一接口的提供者承诺过,最高调用量不超过XX),如对db的保护,对某一服务的调用的控制上。因为对于我们应用来说,db或某一接口就是一共单一的整体。
代码实现思路:
每一个窗(单位时间)就是一个独立的计数器(原子计数器),用以数组保存。将当前时间以某种方式(比如取模)映射到数组的一项中。每次访问先对当前窗内计数器+1,再计算前N个单元格的访问量综合,超过阈值则限流。
这里有个问题,时间永远是递增的,单纯的取模,会导致数组过长,使用内存过多,我们可以用环形队列来解决这个问题。
2、响应模式
模式分析:
每次操作执行时,我们通过判断当前正在执行的访问数是否超过某个阈值在决定是否限流。
该模式看着思路比较的另类,但却有其独到之处。实际上我们限流的根本是为了保护资源,防止系统接受的请求过多,应接不暇,拖慢系统中其他接口的服务,造成雪崩。也就是说我们真正需要关心的是那些运行中的请求,而那些已经完成的请求已是过去时,不再是需要关心的了。
我们来看看其阈值的计算方式,对于一个请求来说,响应时间rt/qps是一个比较容易获取的参数,那么我们这样计算:qps/1000*rt。
此外,一个应用往往是个复杂的系统,提供的服务或者暴露的请求、资源不止一个。内部GC、定时任务的执行、其他服务访问的骤增,外部依赖方、db的抖动,抑或是代码中不经意间的一个bug。都可能导致相应时间的变化,导致系统同时可以执行请求的变化。而这种模式,则能恰如其分的自动做出调整,当系统不适时,rt增加时,会自动的对qps做出适应。
代码实现思路:
当访问开始时,我们对当前计数器(原子计数器)+1,当完成时,-1。该计数器即为当前正在执行的请求数。只需判断这个计数器是否超过阈值即可。