朴素贝叶斯中的朴素一词的来源是假设各特征之间相互独立。这一假设使得朴素贝叶斯算法变得简单,但有时会牺牲一定的分类准确率。朴素贝叶斯经常会用于文本分类,它的思想是基于条件概率和联合概率:
条件概率:事件A在另外一个事件B已经发生的条件下发生的概率
记作:P(A|B)
特性:P(A1,A2|B) = P(A1|B)P(A2|B)
注意:此条件概率的成立,是由于A1,A2相互独立的结果
联合概率:包含多个条件,且所有条件同时成立的概率
记作:P(A,B)
特性:P(A, B) = P(A)P(B)
贝叶斯公式:

W为给定文档的特征值(频数统计,预测文档提供),C为文档类别
为防止计算出的分类概率为0,引入拉普拉斯平滑系数:
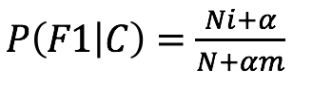
α为指定的系数,一般为1;m为训练文档中统计出来的特征词个数
朴素贝叶斯算法在sklearn中的API:
sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
朴素贝叶斯分类
alpha:拉普拉斯平滑系数
示例:20类新闻分类
数据集来源:sklearn.datasets新闻数据抓取器fetch_20newsgroups

使用朴素贝叶斯分类步骤:
1. 获取新闻的数据,20个类别
news = fetch_20newsgroups(subset='all')
2. 进行数据集分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.3)
3. 对文本数据,进行特征抽取
tf = TfidfVectorizer()
x_train = tf.fit_transform(x_train)
x_test = tf.transform(x_test)
4. estimator估计器训练
mlb = MultinomialNB(alpha=1.0)
mlb.fit(x_train, y_train)
5. 进行预测
y_predict = mlb.predict(x_test)
完整代码:
from sklearn.naive_bayes import MultinomialNB
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
def nbcls():
"""
朴素贝叶斯对新闻数据集进行预测
:return:
"""
# 获取新闻的数据,20个类别
news = fetch_20newsgroups(subset='all')
# 进行数据集分割
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.3)
# 对于文本数据,进行特征抽取
tf = TfidfVectorizer()
x_train = tf.fit_transform(x_train)
x_test = tf.transform(x_test)
# estimator估计器流程
mlb = MultinomialNB(alpha=1.0)
mlb.fit(x_train, y_train)
# 进行预测
y_predict = mlb.predict(x_test)
print("预测每篇文章的类别:", y_predict[:100])
print("真实类别为:", y_test[:100])
print("预测准确率为:", mlb.score(x_test, y_test))
return None
nbcls()
取前100篇新闻的预测的新闻分类结果及准确率:
