题目:有一个jsonline格式的文件file.txt大小约为10K
def get_lines(): with open('file.txt','rb') as f: return f.readlines() if __name__ == '__main__': for e in get_lines(): process(e) # 处理每一行数据
现在要处理一个大小为10G的文件,但是内存只有4G,如果在只修改get_lines 函数而其他代码保持不变的情况下,应该如何实现?需要考虑的问题都有那些?
def get_lines(): with open('file.txt','rb') as f: for i in f: yield i
方法:
from mmap import mmap def get_lines(fp): with open(fp,"r+") as f: m = mmap(f.fileno(), 0) tmp = 0 for i, char in enumerate(m): if char==b" ": yield m[tmp:i+1].decode() tmp = i+1 if __name__=="__main__": for i in get_lines("fp_some_huge_file"): print(i)
要考虑的问题有:内存只有4G无法一次性读入10G文件,需要分批读入分批读入数据要记录每次读入数据的位置。分批每次读取数据的大小,太小会在读取操作花费过多时间。
mmap函数
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
下面说一下内存映射的步骤:
1、用open系统调用打开文件, 并返回描述符fd.
2、用mmap建立内存映射, 并返回映射首地址指针start.
3、对映射(文件)进行各种操作, 显示(printf), 修改(sprintf).
4、用munmap(void *start, size_t lenght)关闭内存映射.
5、用close系统调用关闭文件fd.
系统调用mmap()用于共享内存的两种方式:
(1)使用普通文件提供的内存映射:
适用于任何进程之间。此时,需要打开或创建一个文件,然后再调用mmap()
(2)使用特殊文件提供匿名内存映射:
适用于具有亲缘关系的进程之间。由于父子进程特殊的亲缘关系,在父进程中先调用mmap(),然后调用 fork()。那么在调用fork()之后,子进程继承父进程匿名映射后的地址空间,同样也继承mmap()返回的地址,这样,父子进程就可以通过映射区 域进行通信了。注意,这里不是一般的继承关系。一般来说,子进程单独维护从父进程继承下来的一些变量。而mmap()返回的地址,却由父子进程共同维护。 对于具有亲缘关系的进程实现共享内存最好的方式应该是采用匿名内存映射的方式。此时,不必指定具体的文件,只要设置相应的标志即可。
参考博文:
https://blog.csdn.net/bbzhaohui/article/details/81665370
https://blog.csdn.net/yangle4695/article/details/52139585
enumerate()函数
- enumerate()是python的内置函数
- enumerate在字典上是枚举、列举的意思
- 对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值
- enumerate多用于在for循环中得到计数
-
例如对于一个seq,得到:
-
(0, seq[0]), (1, seq[1]), (2, seq[2])
enumerate()返回的是一个enumerate对象
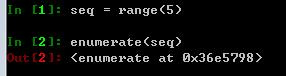
enumerate()使用
- 如果对一个列表,既要遍历索引又要遍历元素时,首先可以这样写:
list1 = ["这", "是", "一个", "测试"] for i in range (len(list1)): print i ,list1[i]
输出:这是一个测试
- 上述方法有些累赘,利用enumerate()会更加直接和优美:
list1 = ["这", "是", "一个", "测试"] for index, item in enumerate(list1): print index, item >>> 0 这 1 是 2 一个 3 测试
- enumerate还可以接收第二个参数,用于指定索引起始值,如:
list1 = ["这", "是", "一个", "测试"] for index, item in enumerate(list1, 1): print index, item >>> 1 这 2 是 3 一个 4 测试
补充
如果要统计文件的行数,可以这样写:
count = len(open(filepath, 'r').readlines())
这种方法简单,但是可能比较慢,当文件比较大时甚至不能工作。
可以利用enumerate():
count = 0 for index, line in enumerate(open(filepath,'r')): count += 1
参考内容:https://www.cnblogs.com/quietwalk/p/7997850.html